

1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visited
1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visited
<span><span><?php
</span></span><span><span>$graph = array(
</span></span><span> <span>'A' => array('B', 'F'),
</span></span><span> <span>'B' => array('A', 'D', 'E'),
</span></span><span> <span>'C' => array('F'),
</span></span><span> <span>'D' => array('B', 'E'),
</span></span><span> <span>'E' => array('B', 'D', 'F'),
</span></span><span> <span>'F' => array('A', 'E', 'C'),
</span></span><span><span>);</span></span><span><span><?php
</span></span><span><span>class Graph
</span></span><span><span>{
</span></span><span> <span>protected $graph;
</span></span><span> <span>protected $visited = array();
</span></span><span>
</span><span> <span>public function __construct($graph) {
</span></span><span> <span>$this->graph = $graph;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// find least number of hops (edges) between 2 nodes
</span></span><span> <span>// (vertices)
</span></span><span> <span>public function breadthFirstSearch($origin, $destination) {
</span></span><span> <span>// mark all nodes as unvisited
</span></span><span> <span>foreach ($this->graph as $vertex => $adj) {
</span></span><span> <span>$this->visited[$vertex] = false;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// create an empty queue
</span></span><span> <span>$q = new SplQueue();
</span></span><span>
</span><span> <span>// enqueue the origin vertex and mark as visited
</span></span><span> <span>$q->enqueue($origin);
</span></span><span> <span>$this->visited[$origin] = true;
</span></span><span>
</span><span> <span>// this is used to track the path back from each node
</span></span><span> <span>$path = array();
</span></span><span> <span>$path[$origin] = new SplDoublyLinkedList();
</span></span><span> <span>$path[$origin]->setIteratorMode(
</span></span><span> <span>SplDoublyLinkedList<span>::</span>IT_MODE_FIFO|SplDoublyLinkedList<span>::</span>IT_MODE_KEEP
</span></span><span> <span>);
</span></span><span>
</span><span> <span>$path[$origin]->push($origin);
</span></span><span>
</span><span> <span>$found = false;
</span></span><span> <span>// while queue is not empty and destination not found
</span></span><span> <span>while (!$q->isEmpty() && $q->bottom() != $destination) {
</span></span><span> <span>$t = $q->dequeue();
</span></span><span>
</span><span> <span>if (!empty($this->graph[$t])) {
</span></span><span> <span>// for each adjacent neighbor
</span></span><span> <span>foreach ($this->graph[$t] as $vertex) {
</span></span><span> <span>if (!$this->visited[$vertex]) {
</span></span><span> <span>// if not yet visited, enqueue vertex and mark
</span></span><span> <span>// as visited
</span></span><span> <span>$q->enqueue($vertex);
</span></span><span> <span>$this->visited[$vertex] = true;
</span></span><span> <span>// add vertex to current path
</span></span><span> <span>$path[$vertex] = clone $path[$t];
</span></span><span> <span>$path[$vertex]->push($vertex);
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span>
</span><span> <span>if (isset($path[$destination])) {
</span></span><span> <span>echo "<span><span>$origin</span> to <span>$destination</span> in "</span>,
</span></span><span> <span>count($path[$destination]) - 1,
</span></span><span> <span>" hopsn";
</span></span><span> <span>$sep = '';
</span></span><span> <span>foreach ($path[$destination] as $vertex) {
</span></span><span> <span>echo $sep, $vertex;
</span></span><span> <span>$sep = '->';
</span></span><span> <span>}
</span></span><span> <span>echo "n";
</span></span><span> <span>}
</span></span><span> <span>else {
</span></span><span> <span>echo "No route from <span><span>$origin</span> to <span>$destinationn</span>"</span>;
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span><span>}</span></span> 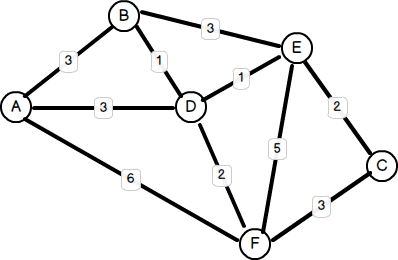
1. Create a queue 2. Enqueue the root node and mark it as visited 3. While the queue is not empty do: 3a. dequeue the current node 3b. if the current node is the one we're looking for then stop 3c. else enqueue each unvisited adjacent node and mark as visited
<span><span><?php
</span></span><span><span>$graph = array(
</span></span><span> <span>'A' => array('B', 'F'),
</span></span><span> <span>'B' => array('A', 'D', 'E'),
</span></span><span> <span>'C' => array('F'),
</span></span><span> <span>'D' => array('B', 'E'),
</span></span><span> <span>'E' => array('B', 'D', 'F'),
</span></span><span> <span>'F' => array('A', 'E', 'C'),
</span></span><span><span>);</span></span><span><span><?php
</span></span><span><span>class Graph
</span></span><span><span>{
</span></span><span> <span>protected $graph;
</span></span><span> <span>protected $visited = array();
</span></span><span>
</span><span> <span>public function __construct($graph) {
</span></span><span> <span>$this->graph = $graph;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// find least number of hops (edges) between 2 nodes
</span></span><span> <span>// (vertices)
</span></span><span> <span>public function breadthFirstSearch($origin, $destination) {
</span></span><span> <span>// mark all nodes as unvisited
</span></span><span> <span>foreach ($this->graph as $vertex => $adj) {
</span></span><span> <span>$this->visited[$vertex] = false;
</span></span><span> <span>}
</span></span><span>
</span><span> <span>// create an empty queue
</span></span><span> <span>$q = new SplQueue();
</span></span><span>
</span><span> <span>// enqueue the origin vertex and mark as visited
</span></span><span> <span>$q->enqueue($origin);
</span></span><span> <span>$this->visited[$origin] = true;
</span></span><span>
</span><span> <span>// this is used to track the path back from each node
</span></span><span> <span>$path = array();
</span></span><span> <span>$path[$origin] = new SplDoublyLinkedList();
</span></span><span> <span>$path[$origin]->setIteratorMode(
</span></span><span> <span>SplDoublyLinkedList<span>::</span>IT_MODE_FIFO|SplDoublyLinkedList<span>::</span>IT_MODE_KEEP
</span></span><span> <span>);
</span></span><span>
</span><span> <span>$path[$origin]->push($origin);
</span></span><span>
</span><span> <span>$found = false;
</span></span><span> <span>// while queue is not empty and destination not found
</span></span><span> <span>while (!$q->isEmpty() && $q->bottom() != $destination) {
</span></span><span> <span>$t = $q->dequeue();
</span></span><span>
</span><span> <span>if (!empty($this->graph[$t])) {
</span></span><span> <span>// for each adjacent neighbor
</span></span><span> <span>foreach ($this->graph[$t] as $vertex) {
</span></span><span> <span>if (!$this->visited[$vertex]) {
</span></span><span> <span>// if not yet visited, enqueue vertex and mark
</span></span><span> <span>// as visited
</span></span><span> <span>$q->enqueue($vertex);
</span></span><span> <span>$this->visited[$vertex] = true;
</span></span><span> <span>// add vertex to current path
</span></span><span> <span>$path[$vertex] = clone $path[$t];
</span></span><span> <span>$path[$vertex]->push($vertex);
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span>
</span><span> <span>if (isset($path[$destination])) {
</span></span><span> <span>echo "<span><span>$origin</span> to <span>$destination</span> in "</span>,
</span></span><span> <span>count($path[$destination]) - 1,
</span></span><span> <span>" hopsn";
</span></span><span> <span>$sep = '';
</span></span><span> <span>foreach ($path[$destination] as $vertex) {
</span></span><span> <span>echo $sep, $vertex;
</span></span><span> <span>$sep = '->';
</span></span><span> <span>}
</span></span><span> <span>echo "n";
</span></span><span> <span>}
</span></span><span> <span>else {
</span></span><span> <span>echo "No route from <span><span>$origin</span> to <span>$destinationn</span>"</span>;
</span></span><span> <span>}
</span></span><span> <span>}
</span></span><span><span>}</span></span>Un graphique et un arbre sont tous deux des structures de données non linéaires, mais elles ont des différences clés. Un arbre est un type de graphique, mais tous les graphiques ne sont pas des arbres. Un arbre est un graphique connecté sans cycles. Il a une structure hiérarchique avec un nœud racine et des nœuds enfants. Chaque nœud d'un arbre a un chemin unique de la racine. D'un autre côté, un graphique peut avoir des cycles et sa structure est plus complexe. Il peut être connecté ou déconnecté et les nœuds peuvent avoir plusieurs chemins entre eux.
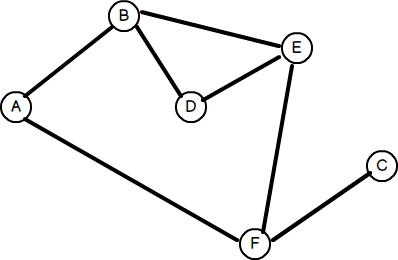
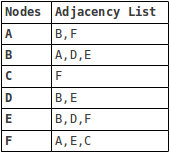
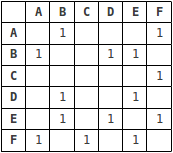
Les graphiques dans les structures de données peuvent être représentés de deux manières: matrice d'adjacence et paradopie liste. Une matrice d'adjacence est un tableau 2D de taille V x V où V est le nombre de sommets dans le graphique. S'il y a un bord entre les sommets I et J, alors la cellule à l'intersection de la ligne I et de la colonne J sera 1, sinon 0. Une liste d'adjacence est un tableau de listes liées. L'indice du tableau représente un sommet et chaque élément de sa liste liée représente les autres sommets qui forment un bord avec le sommet.
sont plusieurs types de graphiques dans les structures de données. Un graphique simple est un graphique sans boucles et pas plus d'un bord entre deux sommets. Un multigraphe peut avoir plusieurs bords entre les sommets. Un graphique complet est un graphique simple où chaque paire de sommets est connectée par un bord. Un graphique pondéré attribue un poids à chaque bord. Un graphique dirigé (ou digraph) a des bords avec une direction. Les bords pointent d'un sommet à un autre.
Les graphiques sont utilisés dans de nombreuses applications en informatique. Ils sont utilisés dans les réseaux sociaux pour représenter les liens entre les personnes. Ils sont utilisés dans le flux Web pour visiter les pages Web et créer un index de recherche. Ils sont utilisés dans les algorithmes de routage de réseau pour trouver le meilleur chemin entre deux nœuds. Ils sont utilisés en biologie pour modéliser et analyser les réseaux biologiques. Ils sont également utilisés dans les simulations sur l'infographie et la physique.
Il existe deux algorithmes de traversée graphique principaux: recherche en profondeur d'abord (DFS) et largeur d'abord de recherche (BFS). DFS explore autant que possible le long de chaque branche avant de revenir en arrière. Il utilise une structure de données de pile. BFS explore tous les sommets à la profondeur actuelle avant de passer au niveau suivant. Il utilise une structure de données de file d'attente.
En Java, un graphique peut être implémenté à l'aide d'un hashmap pour stocker la liste d'adjacence. Chaque clé du hashmap est un sommet et sa valeur est une liste liée contenant les sommets auxquels il est connecté.
Un graphique bipartite est un graphique dont les vertices peuvent être divisé en deux ensembles disjoints tels que chaque bord relie un sommet dans un ensemble sur un sommet dans l'autre ensemble. Aucun bord ne connecte les sommets dans le même ensemble.
Un sous-graphique est un graphique qui fait partie d'un autre graphique. Il a des sommets (ou tous) du graphique d'origine et des (ou tous) bords du graphique d'origine.
Un cycle dans un graphique est Un chemin qui démarre et se termine au même sommet et a au moins un bord.
Un chemin dans un graphique est une séquence de sommets où chaque paire des sommets consécutifs sont connectés par un bord.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



