

Après le lancement de Chatgpt et la poussée suivante des modèles de grande langue (LLM), leurs limites inhérentes à l'hallucination, la date de coupure des connaissances et l'incapacité de fournir des informations spécifiques à l'organisation ou à la personne sont rapidement devenues évidentes et ont été considérées comme majeures inconvénients. Pour résoudre ces problèmes, les méthodes de génération d'augmentation de la récupération (RAG) ont rapidement gagné du terrain qui intègre des données externes aux LLM et guider leur comportement pour répondre aux questions d'une base de connaissances donnée.
Fait intéressant, le premier article sur RAG a été publié en 2020 par des chercheurs de Facebook AI Research (maintenant Meta AI), mais ce n'est qu'à l'avènement de Chatgpt que son potentiel a été pleinement réalisé. Depuis lors, il n'y a pas eu d'arrêt. Des cadres de chiffons plus avancés et complexes ont été introduits, ce qui a non seulement amélioré la précision de cette technologie, mais lui a également permis de gérer les données multimodales, élargissant son potentiel pour un large éventail d'applications. J'ai écrit sur ce sujet en détail dans les articles suivants, discutant spécifiquement du chiffon multimodal contextuel, de la recherche d'IA multimodale pour les applications commerciales et des plateformes d'extraction et de jumelage.
.Intégration des données multimodales dans un modèle de langue large
Recherche d'IA multimodale pour les applications commerciales
Extraction d'informations alimentées par AI et matchmaking
Avec le paysage en expansion de la technologie des chiffons et les exigences émergentes d'accès aux données, il a été réalisé que les fonctionnalités d'un chiffon de retriever, qui répond aux questions d'une base de connaissances statiques, peut être étendue en intégrant d'autres sources de connaissances et outils diverses comme:
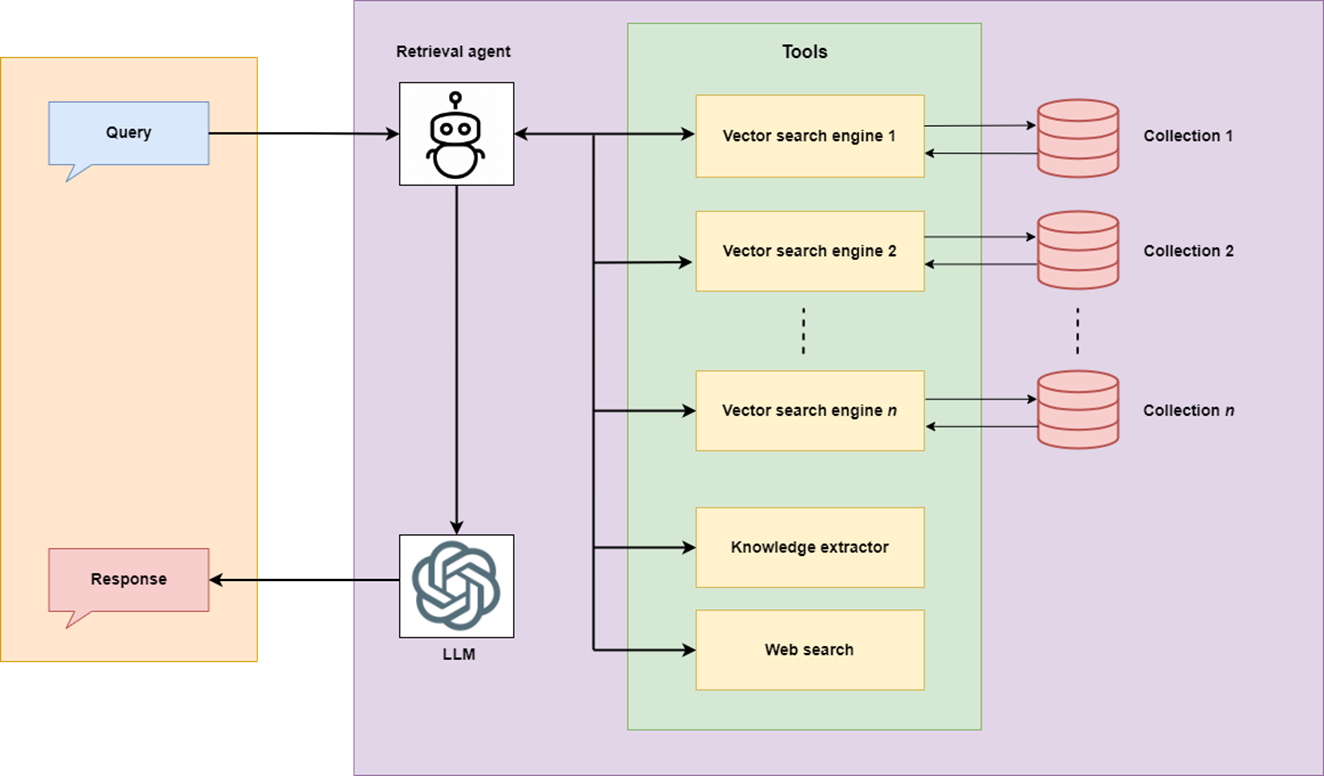
Pour y parvenir, un chiffon devrait être en mesure de sélectionner la meilleure source de connaissances et / ou outil basée sur la requête. L'émergence des agents de l'IA a introduit l'idée de " rag d'agentique " qui pourrait sélectionner le meilleur plan d'action basé sur la requête.
Dans cet article, nous développerons une application de chiffon agentique spécifique, appelée Smart Business Guide (SBG) - La première version de l'outil qui fait partie de notre projet en cours appelé Projet en cours appelé Optimiste, financé par Interreg Central Baltic. Le projet se concentre sur les immigrants de réduction des immigrants en Finlande et en Estonie pour l'entrepreneuriat et la planification d'entreprise en utilisant l'IA. SBG est l'un des outils destinés à être utilisés dans le processus de réduction de ce projet. Cet outil se concentre sur la fourniture d'informations précises et rapides provenant de sources authentiques aux personnes ayant l'intention de démarrer une entreprise, ou celles qui font déjà des affaires.
Le chiffon agentique du SBG comprend:
Quelle est la particularité de ce chiffon agentique?
spécifiquement, l'article est structuré autour des sujets suivants:
L'ensemble du code de cette application se trouve sur github.
Le code d'application est structuré en deux. py fichiers: _agentic rag.py qui implémente l'intégralité du flux de travail agentique, et app.py qui implémente le Rational Interface utilisateur graphique.
Plongeons-y.
La base de connaissances du SBG comprend des guides commerciaux et d'entrepreneuriat authentiques publiés par les agences finlandaises. Étant donné que ces guides sont volumineux et que la recherche d'une information requise n'est pas triviale, le but est de développer un chiffon agentique qui pourrait non seulement fournir des informations précises à partir de ces guides, mais peut également les augmenter une recherche sur le Web et d'autres sources de confiance dans Finlande pour des informations mises à jour.
llamaparse est une plate-forme d'analyse de document native génai construite avec LLMS et pour les cas d'utilisation de LLM. J'ai expliqué l'utilisation du llamaparse dans les articles que j'ai cités ci-dessus. Cette fois, j'ai analysé les documents directement à Llamacloud. Llamaparse offre 1000 crédits gratuits par jour. L'utilisation de ces crédits dépend du mode d'analyse. Pour le PDF en texte uniquement, « Fast ‘ Mode (1 Credit / 3 pages) fonctionne bien qui saute l'OCR, l'extraction d'image et l'identification de la table / de la tête. Il existe d'autres modes plus avancés disponibles avec un nombre plus élevé de points de crédit par page. J'ai sélectionné le mode « Premium » qui effectue l'OCR, l'extraction d'images et l'identification de la table / de la tête et est idéal pour des documents complexes avec des images.
J'ai défini les instructions d'analyse suivantes.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Les documents analysés ont été téléchargés au format Markdown de Llamacloud. La même analyse peut être effectuée via API Llamacloud que suit.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Voici un exemple de page de la créativité et des affaires du guide par Pikkala, A. et al., (2015) (" gratuit à copier pour une utilisation privée ou publique non commerciale avec l'attribution ").

Voici la sortie analysée de cette page. Llamaparse a efficacement extrait les informations de toutes les structures de la page. Le cahier indiqué dans la page est au format d'image.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Les documents de marque analysés sont ensuite divisés en morceaux en utilisant RecursiVeCaracterTextSplitter avec Chunk_Size = 3000 et Chunk_overlap = 200.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsPar la suite, un VectorStore est créé dans la base de données de chroma à l'aide d'un modèle d'intégration tel que le modèle OpenSource All-MinilM-L6-V2 ou Openai Text-Embedding-3-Garning .
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreUn agent AI est la combinaison du flux de travail et la logique de prise de décision pour répondre intelligemment aux questions ou effectuer d'autres tâches complexes qui doivent être décomposées en sous-tâches plus simples.
J'ai utilisé Langgraph pour concevoir un flux de travail pour notre agent AI pour la séquence d'actions ou de décisions sous la forme d'un graphique. Notre agent doit décider de répondre à la question de la base de données vectorielle (base de connaissances), de recherche Web, de recherche hybride ou à l'aide d'un outil.
Dans mon article suivant, j'ai expliqué le processus de création d'un flux de travail agentique à l'aide de Langgraph.
Comment développer un agent d'IA gratuit avec une recherche automatique sur Internet
Nous devons créer des nœuds graphiques qui représentent un workflow pour prendre des décisions (par exemple, recherche Web ou recherche de base de données vectorielle). Les nœuds sont connectés par bords qui définissent le flux de décisions et d'actions (par exemple, quel est l'état suivant après la récupération). Le graphique état garde une trace des informations lorsqu'elle se déplace dans le graphique afin que l'agent utilise les données correctes pour chaque étape.
Le point d'entrée du flux de travail est une fonction de routeur qui détermine le nœud initial à exécuter dans le flux de travail en analysant la requête de l'utilisateur. L'ensemble du flux de travail contient les nœuds suivants.
Voici les bords du workflow.
Une structure de l'état graphique agit comme un conteneur pour maintenir l'état du flux de travail et comprend les éléments suivants:
La structure de l'état du graphique est définie comme suit:
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
La fonction de routeur suivante analyse la requête et le achemine vers un nœud pertinent pour le traitement. Une chaîne est créée comprenant une invite pour sélectionner un outil / nœud dans un dictionnaire de sélection d'outils et la requête. La chaîne invoque un routeur LLM pour sélectionner l'outil pertinent.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Les questions qui ne sont pas pertinentes pour le flux de travail sont acheminées vers _Handle nœud non lié qui fournit une réponse de secours par le nœud générer .
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
L'ensemble du flux de travail est illustré dans la figure suivante.
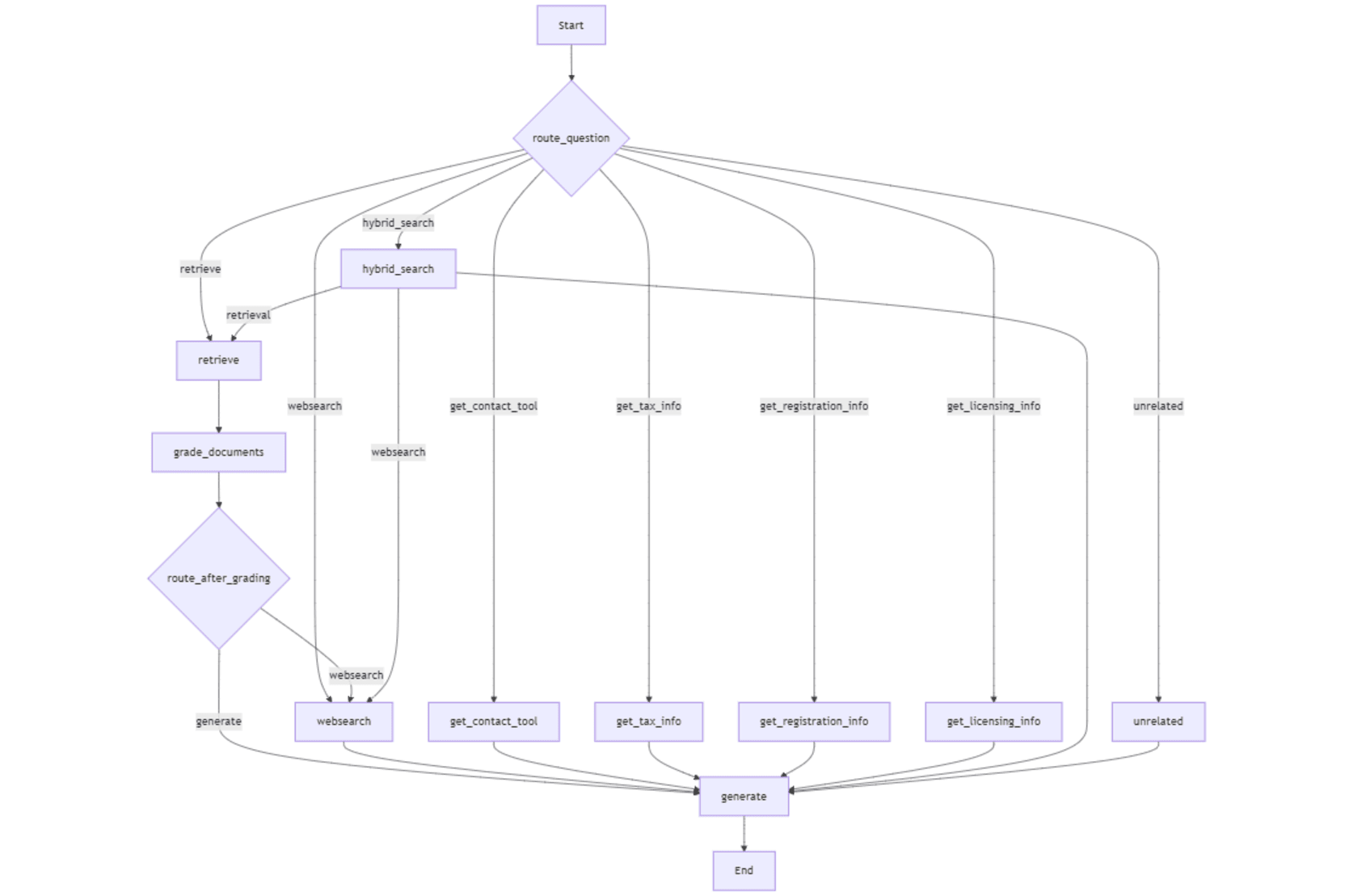
Le nœud récupérer invoque le Retriever avec la question pour récupérer des morceaux d'informations pertinentes du magasin vectoriel. Ces morceaux (" documents ") sont envoyés au nœud _grade Documents pour noter leur pertinence. Sur la base des morceaux gradués ("_filtered docs "), le nœud _Route_After Node décide de procéder à la génération avec les informations récupérées ou d'invoquer la recherche Web. La fonction d'assistance _Initialize_grader chaîne initialise la chaîne de niveleuse avec une invite guidant le Grader LLM pour évaluer la pertinence de chaque morceau. Le _grade documente analyse le nœud chaque morceau pour déterminer si elle est pertinente pour la question. Pour chaque morceau, il publie " oui " ou " non " selon que le morceau est pertinent pour la question.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Le nœud _web Search est atteint soit par _Route_after nœud nœud quand aucun morceau pertinent n'est trouvé dans les informations récupérées, ou directement par _Route Question Node lorsque _internet_search activé L'indicateur d'état est " true " (sélectionné par le Bouton radio dans l'interface utilisateur), ou la fonction du routeur décide d'acheter la requête vers _web Rechercher pour récupérer des informations récentes et plus pertinentes.
L'API gratuite du moteur de recherche Tavily peut être obtenue en créant un compte sur leur site Web. Le plan gratuit offre 1000 points de crédit par mois. Les résultats de recherche Tavily sont annexés à la variable d'état "Document " qui est ensuite transmis à générer Node avec la variable d'état " Question ".
La recherche hybride combine les résultats de la recherche et de la recherche Tavily et de la variable d'état "Document ", qui est passé pour générer un nœud avec " Question " Variable d'état.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Voici comment _get_tax
info Le nœud fonctionne avec certaines fonctions d'assistance. Les autres outils (nœuds) de ce type fonctionnent également de la même manière.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Le nœud, générer , crée la réponse finale en invoquant une chaîne avec une invite prédéfinie (classe promptTEemplate de Langchain décrite ci-dessous. L'invite _rag reçoit les variables d'état _ "Questio n", "Contex t", et "Response_styl_e" et guide l'ensemble Comportement de la génération de réponse, y compris des instructions sur le style de réponse, le ton conversationnel, les directives de formatage, les règles de citation, la manipulation du contexte hybride et la focalisation contextuelle uniquement.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)le nœud générer récupère d'abord les variables d'état " question ", " documents ", et "_answer style " et formats et formats Le " documente " en une seule chaîne qui sert de contexte. Par la suite, il invoque la chaîne de génération avec _rag invite et une génération de réponse llm _ pour générer la réponse finale qui est remplie dans "Generatio_N" State Variable. Cette variable d'état est utilisée par _App.p_y pour afficher la réponse générée dans l'interface utilisateur Streamlit .
Avec l'API libre de Groq, il est possible de frapper la limite de débit ou de fenêtre de contexte d'un modèle. Dans ce cas, j'ai étendu générer un nœud pour changer dynamiquement les modèles de manière circulaire à partir de la liste des noms de modèle et revenir au modèle actuel après avoir généré la réponse.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Il existe d'autres fonctions d'aide dans _agentic rag.py pour initialiser l'application, les LLM, les modèles d'intégration et les variables de session. La fonction _Initialize app est appelée à partir de app.py pendant l'initialisation de l'application et __ est déclenchée à chaque fois qu'une variable de modèle ou d'état est modifiée via l'application Streamlit . Il réinitialise les composants et enregistre les états mis à jour. Cette fonction maintient également la trace de diverses variables de session et empêche l'initialisation redondante.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsLes fonctions d'assistance suivantes initialisent un LLM de réponse, un modèle d'intégration, un routeur LLM et un classement LLM. La liste des noms de modèles, _Model Liste , est utilisée pour garder une trace des modèles lors de la commutation dynamique des modèles par générer nœud.
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreMaintenant, l'état du graphique, les nœuds, les points d'entrée conditionnels en utilisant _ROUTE Question , et les bords sont définis pour établir le flux entre les nœuds. Enfin, le workflow est compilé dans une exécutable app pour une utilisation dans l'interface Streamlit . Le point d'entrée de la condition dans le workflow utilise la fonction _ROUTE Question pour sélectionner le premier nœud du workflow en fonction de la requête. Le bord conditionnel (_Workflow.add_conditional bords ) décrit s'il faut passer vers WebSearch ou vers générer nœud basé sur la pertinence des morceaux déterminés par _grade Documents nœud.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
L'application Streamlit dans app.py fournit une interface interactive pour poser des questions et afficher des réponses en utilisant des paramètres dynamiques pour la sélection de modèles, les styles de réponse et les outils spécifiques à la requête. La fonction _Initialize app , importée de _agentic rag.py, initialise toutes les variables de session, y compris tous les LLM, le modèle d'intégration et d'autres options sélectionnées dans la barre latérale gauche.
Les instructions d'impression dans _agentic_rag.p_y sont capturées en redirigeant sys.stdout vers un tampon io.strimino . Le contenu de ce tampon est ensuite affiché dans l'espace réservé de débogage à l'aide du composant _text Zone dans Streamlit.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Voici l'instantané de l'interface rationalisée:

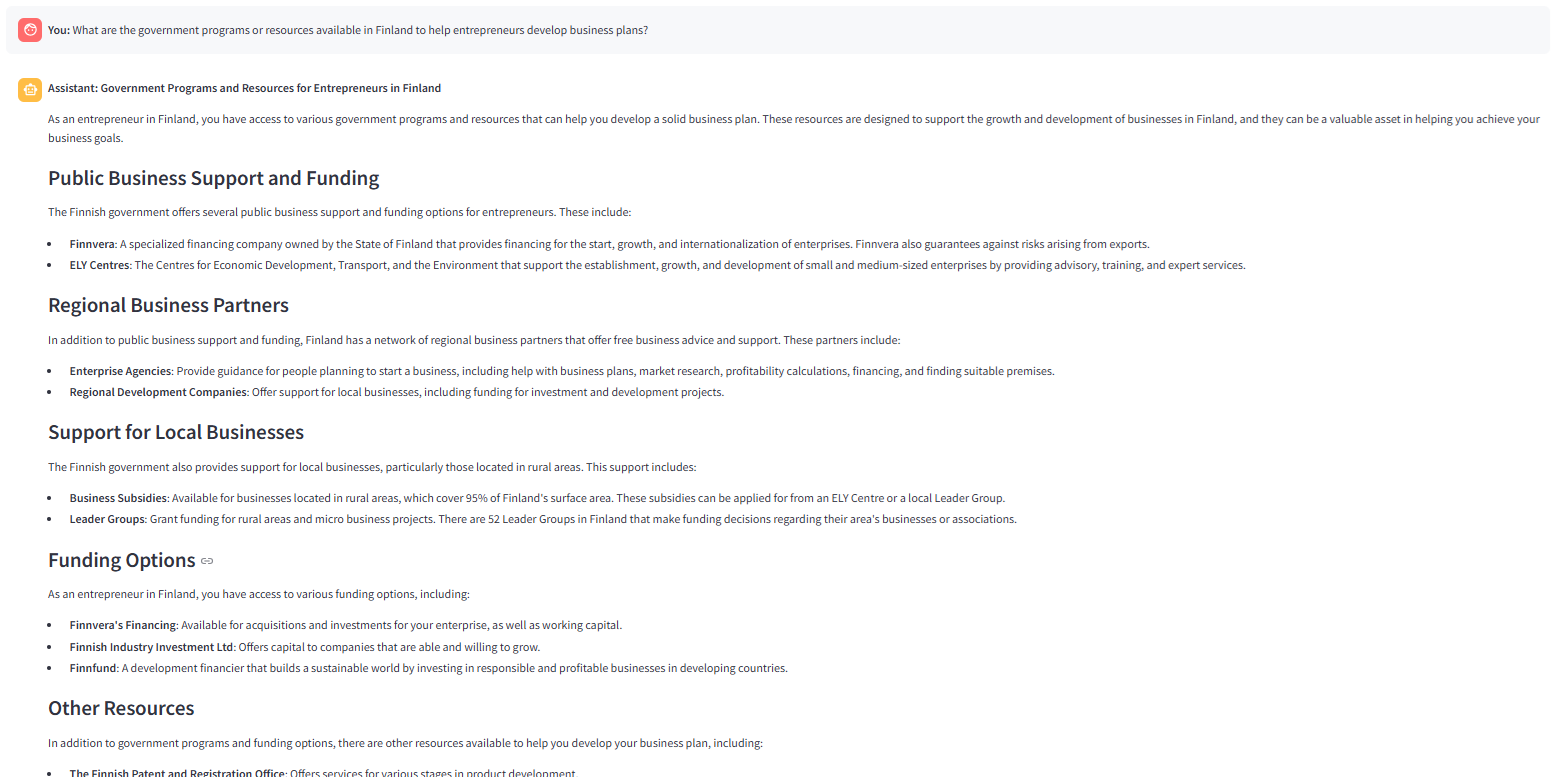
L'image suivante montre la réponse générée par LLAMA-3.3–70B-Versatile avec « Concise» Style de réponse sélectionné. Le routeur de requête (_route Question ) invoque le Retriever (recherche de vecteur) et la fonction de niveleuse trouve tous les morceaux récupérés pertinents. Par conséquent, une décision de générer la réponse via générer nœud est prise par _Route_after nœud .

L'image suivante montre la réponse à la même question en utilisant « Explicatoire « Style de réponse. Comme indiqué dans _rag invite , le LLM élabore la réponse avec plus d'explications.
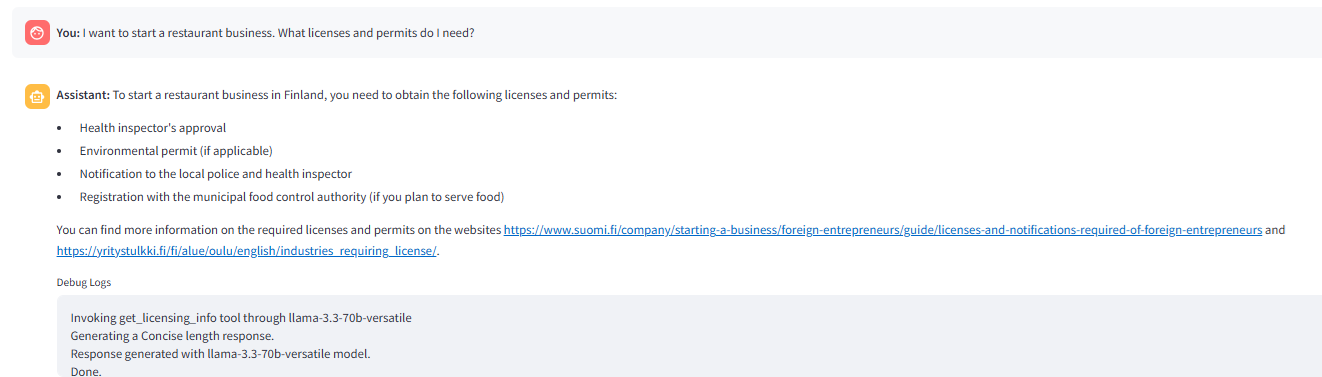
L'image suivante montre le routeur déclenchant _get_license outil d'info en réponse à la question.
L'image suivante montre une recherche Web invoquée par _ROUTE_AFTER Grading nœud Lorsqu'aucun morceau pertinent n'est trouvé dans la recherche de vecteur.
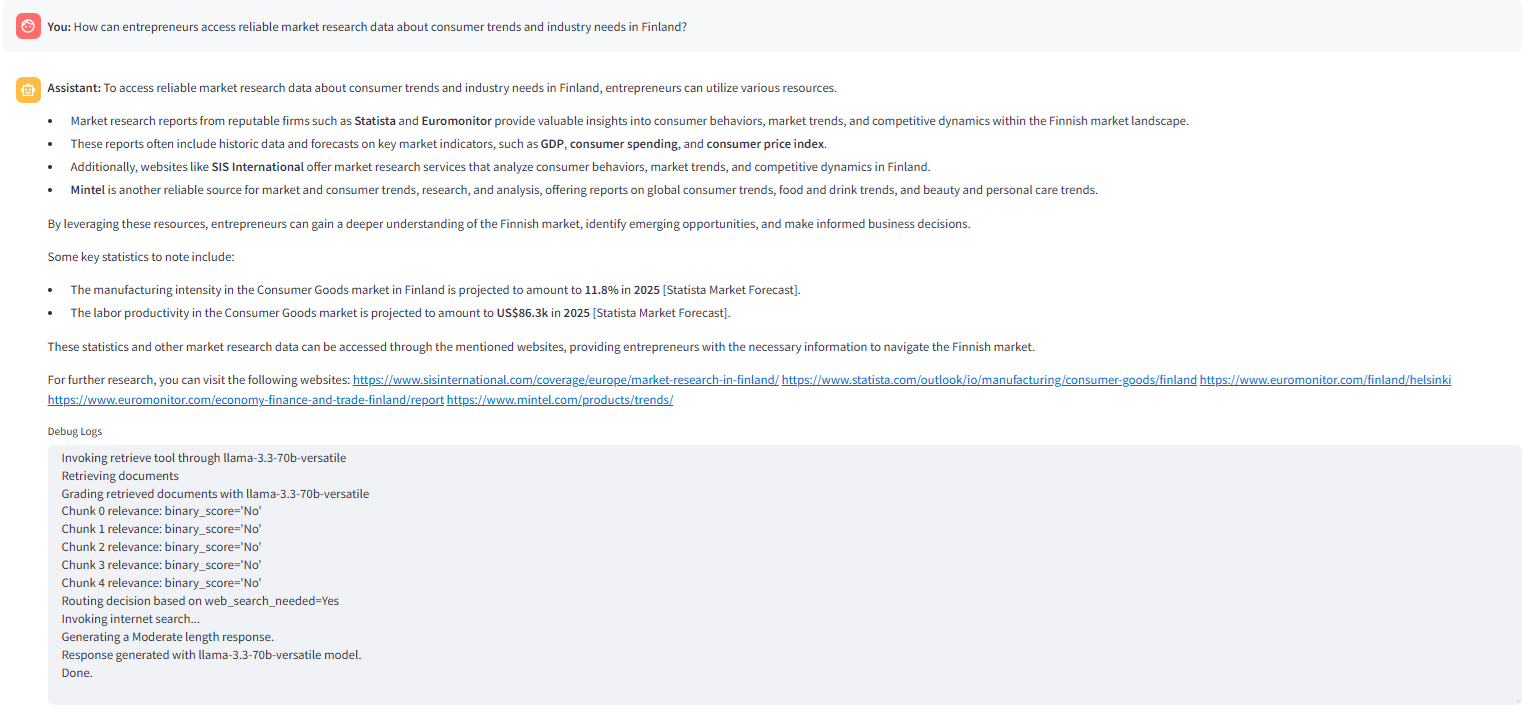
L'image suivante montre la réponse générée avec l'option de recherche hybride sélectionnée dans l'application Streamlit . Le nœud _route qustion trouve le _internet_search activé Flag de l'état ‘ true ‘ et achemine la question vers _hybrid recherche nœud.
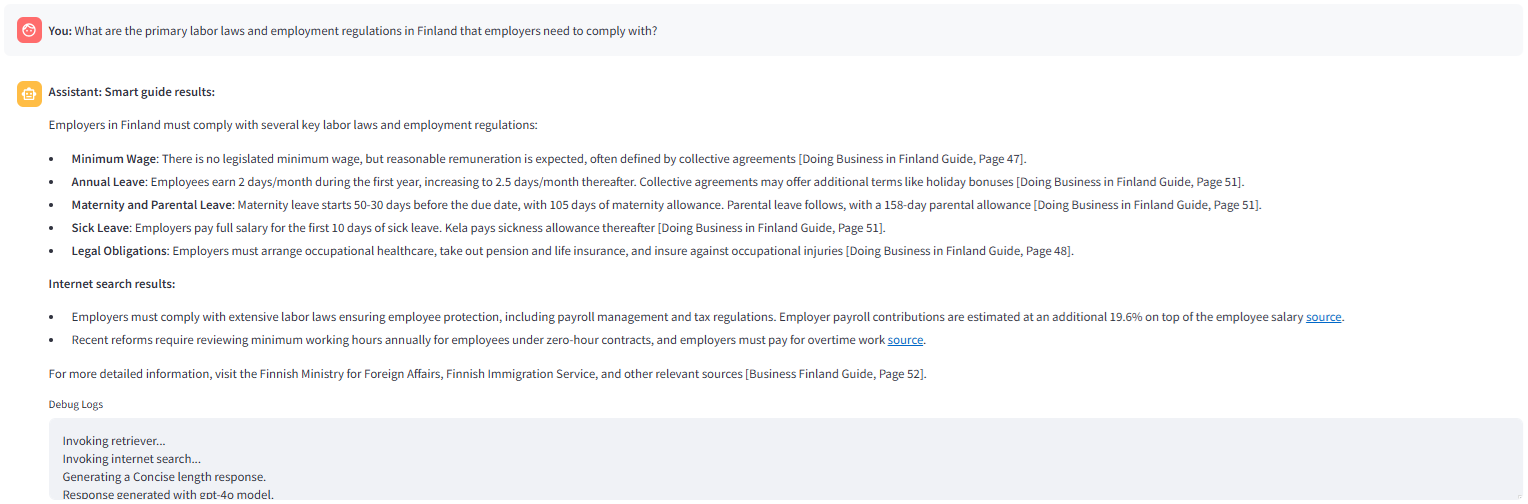
Cette application peut être améliorée dans plusieurs directions, par exemple,
C'est tout le monde! Si vous avez aimé l'article, veuillez applaudir l'article (plusieurs fois ? ), Écrivez un commentaire et suivez-moi sur Medium et LinkedIn.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle est la différence entre RabbitMQ et Kafka
Quelle est la différence entre RabbitMQ et Kafka
 Quelle devise est l'USDT ?
Quelle devise est l'USDT ?
 Windows 11 mon ordinateur transfert vers le tutoriel de bureau
Windows 11 mon ordinateur transfert vers le tutoriel de bureau
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Quelle est la différence entre USB-C et TYPE-C
Quelle est la différence entre USB-C et TYPE-C
 Tutoriel d'utilisation de Kindeditor
Tutoriel d'utilisation de Kindeditor
 Qu'est-ce que la recherche Spotlight ?
Qu'est-ce que la recherche Spotlight ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



