

Le paysage rapide en évolution des modèles de grands langues (LLMS) pour le codage présente aux développeurs une multitude de choix. Cette analyse compare les principaux LLM accessibles via des API publiques, en se concentrant sur leurs prouesses de codage, mesurées par des repères comme les scores ELO humainval et réel. Que vous créiez des projets personnels ou que vous intégriez l'IA dans votre flux de travail, la compréhension des forces et des faiblesses de ces modèles est cruciale pour la prise de décision éclairée.
Les défis de la comparaison LLM:
La comparaison directe est difficile en raison des mises à jour fréquentes du modèle (même les mineures ont un impact significatif sur les performances), la stochasticité inhérente des LLM conduisant à des résultats incohérents et des biais potentiels dans la conception et le rapport de référence. Cette analyse représente une comparaison les meilleurs effets basée sur les données actuellement disponibles.
Métriques d'évaluation: Scores Humaneval et ELO:
Cette analyse utilise deux mesures clés:
Présentation des performances:

Les modèles d'Openai sont régulièrement en tête à la fois Humaneval et Elo Classs, présentant des capacités de codage supérieures. Le modèle o1-min surpasse étonnamment le modèle O1 plus grand
O1 dans les deux métriques. Les meilleurs modèles des autres sociétés présentent des performances comparables, bien que la traîne Openai. 
Benchmark vs Discgences de performance du monde réel:

Un décalage significatif existe entre les scores Humaneval et ELO. Certains modèles, comme Mistral, Mistral Large , fonctionnent mieux sur Humaneval que dans l'utilisation du monde réel (sur-ajustement potentiel), tandis que d'autres, tels que Google
Gemini 1.5 Pro , montrent la tendance opposée ( sous-estimation dans les repères). Cela met en évidence les limites de compter uniquement sur les repères. Les modèles Alibaba et Mistral surviennent souvent des références, tandis que les modèles de Google semblent sous-estimés en raison de leur accent sur l'évaluation équitable. Les méta-modèles démontrent un équilibre cohérent entre la référence et les performances du monde réel. 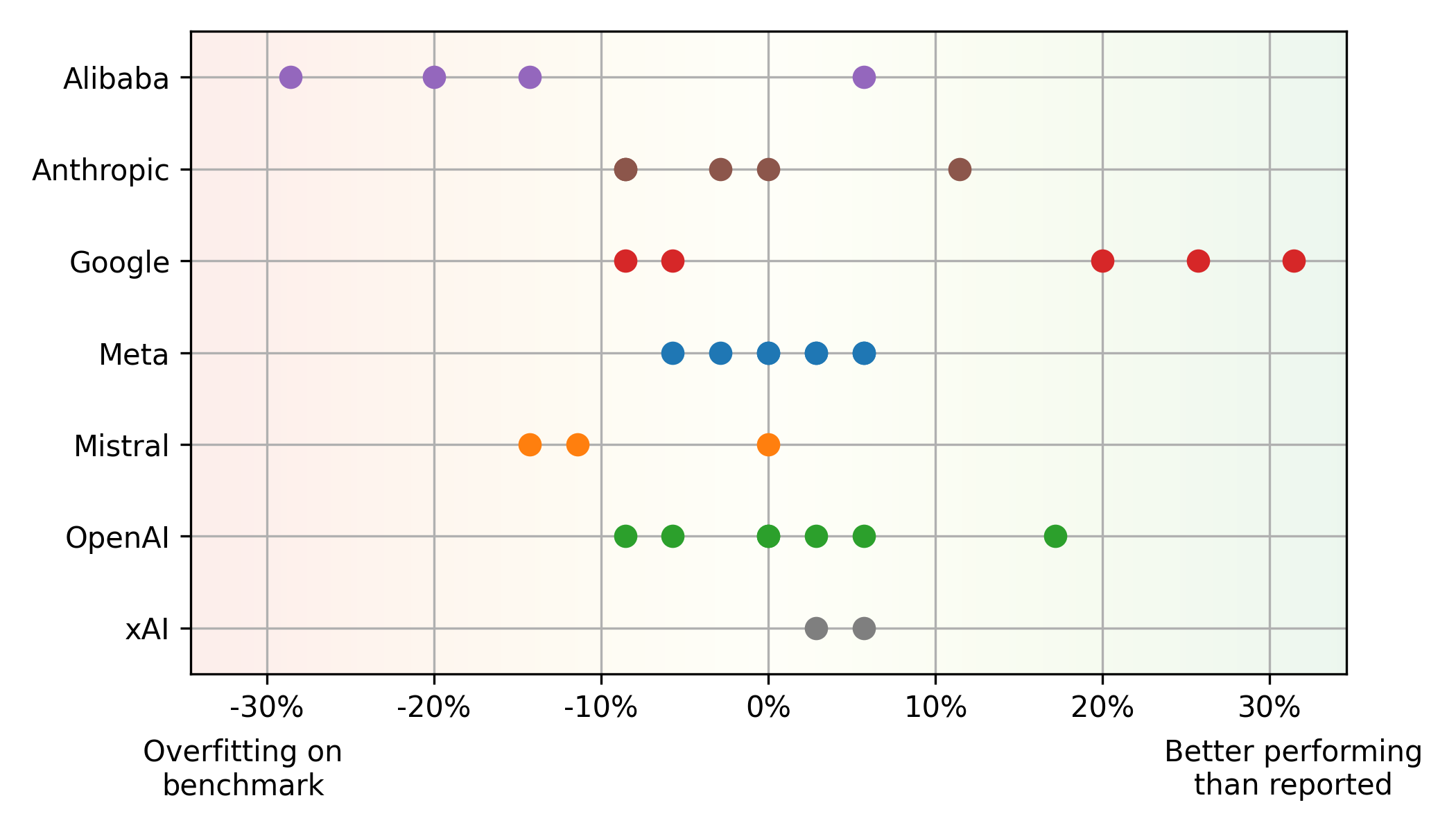
Équilibrer les performances et le prix:


Le Front Pareto (équilibre optimal des performances et des prix) propose principalement des modèles OpenAI (hautes performances) et Google (valeur pour l'argent). Les modèles Llama open-source de META, au prix basé sur les moyennes du fournisseur de cloud, montrent également une valeur compétitive.
Informations supplémentaires:



LLMS améliorent régulièrement les performances et la diminution du coût. Les modèles propriétaires maintiennent la domination, bien que les modèles open-source rattrape leur retard. Même les mises à jour mineures affectent considérablement les performances et / ou les prix.
Conclusion:
Le paysage CODING LLM est dynamique. Les développeurs doivent évaluer régulièrement les derniers modèles, en considérant à la fois les performances et les coûts. Comprendre les limites des références et hiérarchiser diverses mesures d'évaluation est crucial pour faire des choix éclairés. Cette analyse fournit un instantané de l'état actuel, et la surveillance continue est essentielle pour rester en avance dans ce domaine en évolution rapide.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment implémenter la messagerie instantanée sur le front-end
Comment implémenter la messagerie instantanée sur le front-end
 La différence entre Sass et moins
La différence entre Sass et moins
 Comment résoudre l'erreur d'application WerFault.exe
Comment résoudre l'erreur d'application WerFault.exe
 Solution d'erreur inattendue IIS 0x8ffe2740
Solution d'erreur inattendue IIS 0x8ffe2740
 La différence entre les cours Python et les cours C+
La différence entre les cours Python et les cours C+
 Y a-t-il une grande différence entre le langage C et Python ?
Y a-t-il une grande différence entre le langage C et Python ?
 Le système d'exploitation Hongmeng de Huawei est-il Android ?
Le système d'exploitation Hongmeng de Huawei est-il Android ?
 Win10 suspend les mises à jour
Win10 suspend les mises à jour








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



