

Cet article plonge dans les aspects pratiques des modèles de grande langue (LLM) à réglage fin, en se concentrant sur le codex et en instructGpt comme des exemples principaux. C'est le troisième d'une série explorant les modèles GPT, s'appuyant sur les discussions précédentes sur la pré-formation et la mise à l'échelle.

Le réglage fin est crucial car bien que les LLM pré-formés soient polyvalents, ils ne sont souvent pas des modèles spécialisés adaptés à des tâches spécifiques. En outre, même des modèles puissants comme GPT-3 peuvent lutter contre les instructions complexes et le maintien de la sécurité et des normes éthiques. Cela nécessite des stratégies de réglage fin.
L'article met en évidence deux défis clés du réglage fin: l'adaptation aux nouvelles modalités (comme l'adaptation du Codex à la génération de code) et l'alignement du modèle avec les préférences humaines (comme démontré par InstructGpt). Les deux nécessitent un examen attentif de la collecte de données, de l'architecture du modèle, des fonctions objectives et des mesures d'évaluation.
Codex: affineur pour la génération de code
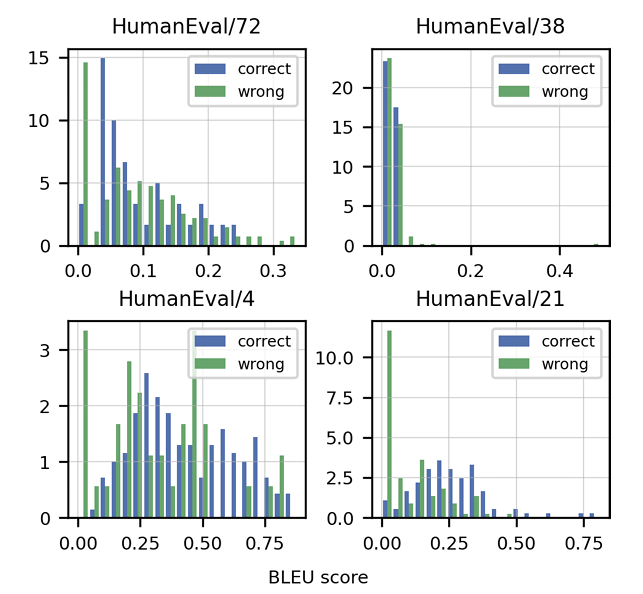
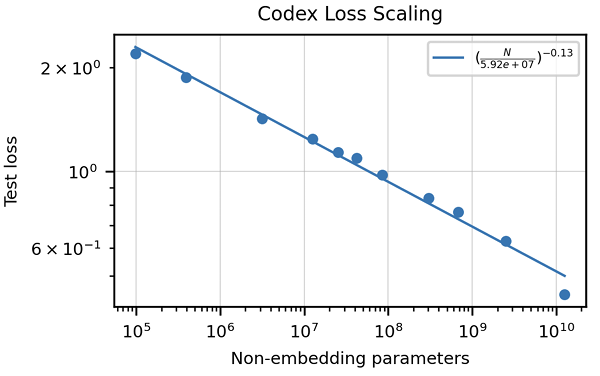
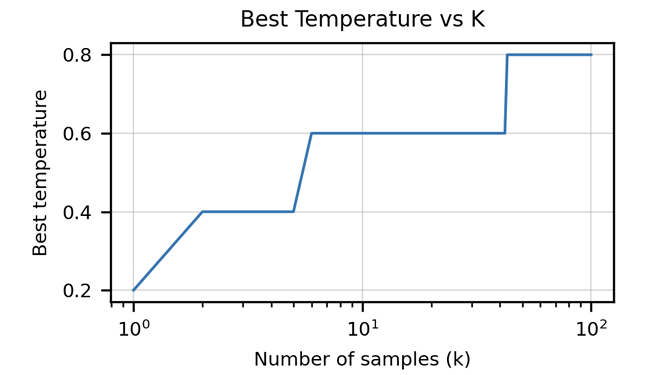
L'article met l'accent sur l'insuffisance des mesures traditionnelles comme le score BLEU pour évaluer la génération de code. Il introduit la "correction fonctionnelle" et la métrique pass @ k , offrant une méthode d'évaluation plus robuste. La création de l'ensemble de données Humaneval, comprenant des problèmes de programmation manuscrits avec des tests unitaires, est également mise en évidence. Les stratégies de nettoyage des données spécifiques au code sont discutées, ainsi que l'importance d'adapter les jetons pour gérer les caractéristiques uniques des langages de programmation (par exemple, codage des espaces blancs). L'article présente des résultats démontrant les performances supérieures de Codex par rapport à GPT-3 sur Humaneval et explore l'impact de la taille et de la température du modèle sur les performances.


instructgpt et chatgpt: alignement avec les préférences humaines
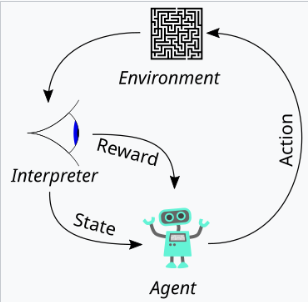
L'article définit l'alignement comme le modèle présentant une utilité, une honnêteté et une insuffisance. Il explique comment ces qualités sont traduites en aspects mesurables comme l'enseignement suivant, taux d'hallucination et biais / toxicité. L'utilisation de l'apprentissage du renforcement de la rétroaction humaine (RLHF) est détaillée, décrivant les trois étapes: collectionner les commentaires humains, former un modèle de récompense et optimiser la politique en utilisant l'optimisation de la politique proximale (PPO). L'article souligne l'importance du contrôle de la qualité des données dans le processus de collecte de rétroaction humaine. Les résultats présentant l'alignement amélioré d'InstructGpt, l'hallucination réduite et l'atténuation des régressions de performance sont présentés.
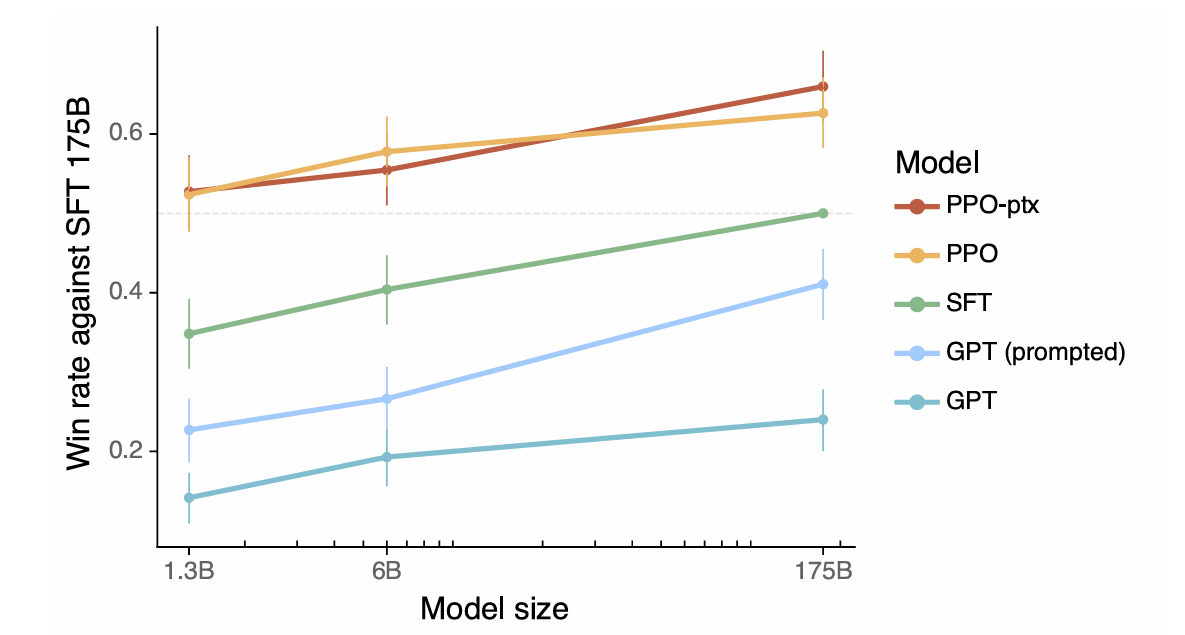

Résumé et meilleures pratiques
L'article conclut en résumant des considérations clés pour les LLM de réglage fin, notamment la définition des comportements souhaités, l'évaluation des performances, la collecte et le nettoyage des données, l'adaptation de l'architecture du modèle et l'atténuation des conséquences négatives potentielles. Il encourage un examen attentif du réglage de l'hyperparamètre et met l'accent sur la nature itérative du processus de réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ralentir la vidéo sur Douyin
Comment ralentir la vidéo sur Douyin
 Comment créer un nouveau dossier dans pycharm
Comment créer un nouveau dossier dans pycharm
 Quels sont les logiciels bureautiques
Quels sont les logiciels bureautiques
 Comment redimensionner des images dans PS
Comment redimensionner des images dans PS
 Comment résoudre le problème d'accès refusé lors du démarrage de Windows 10
Comment résoudre le problème d'accès refusé lors du démarrage de Windows 10
 Les performances des micro-ordinateurs dépendent principalement de
Les performances des micro-ordinateurs dépendent principalement de
 La différence entre a++ et ++a
La différence entre a++ et ++a
 Comment utiliser la fonction dateiff
Comment utiliser la fonction dateiff








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



