

dévoiler la magie derrière les grands modèles de langue (LLMS): une exploration en deux parties
Les modèles de langues importants (LLM) semblent souvent magiques, mais leur fonctionnement interne est étonnamment systématique. Cette série en deux parties démystifie les LLM, expliquant leur construction, leur formation et leur raffinement dans les systèmes d'IA que nous utilisons aujourd'hui. Inspirée par la vidéo YouTube perspicace (et longue!) D'Andrej Karpathy, cette version condensée fournit les concepts principaux dans un format plus accessible. Alors que la vidéo de Karpathy est fortement recommandée (800 000 vues en seulement 10 jours!), Cette lecture de 10 minutes distille les principaux plats à retenir des 1,5 premières heures.
Partie 1: Des données brutes au modèle de base
LLM Le développement implique deux phases cruciales: pré-formation et post-formation.
1. Pré-formation: enseigner la langue
Avant de générer du texte, un LLM doit apprendre la structure du langage. Ce processus de pré-formation intensif en calcul implique plusieurs étapes:
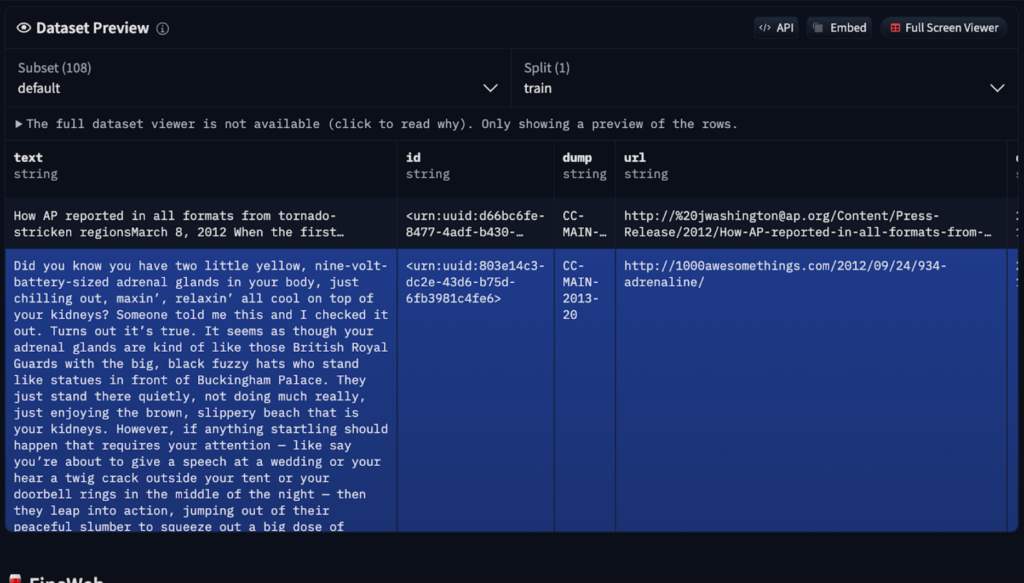
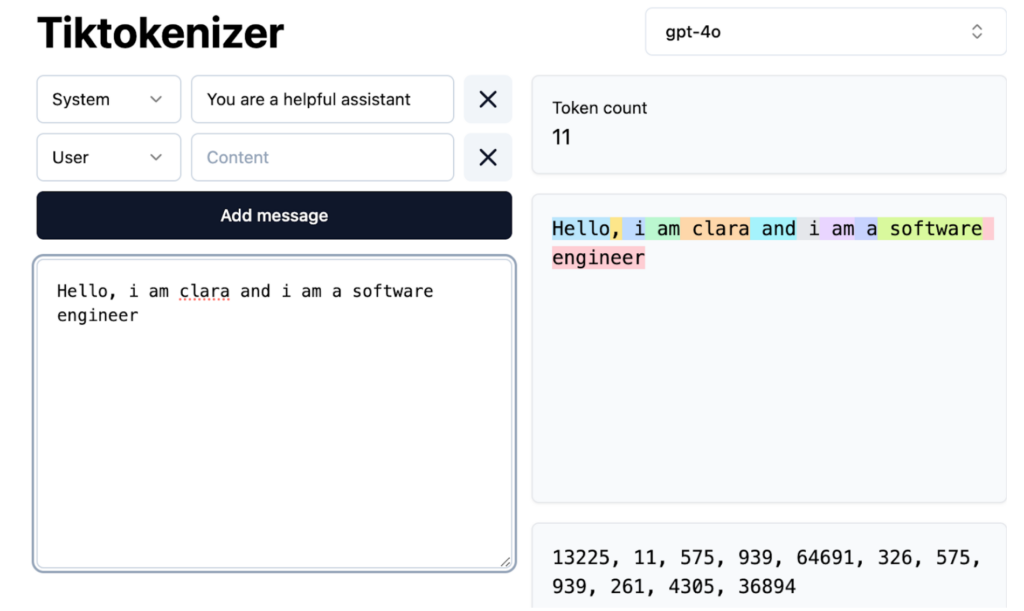
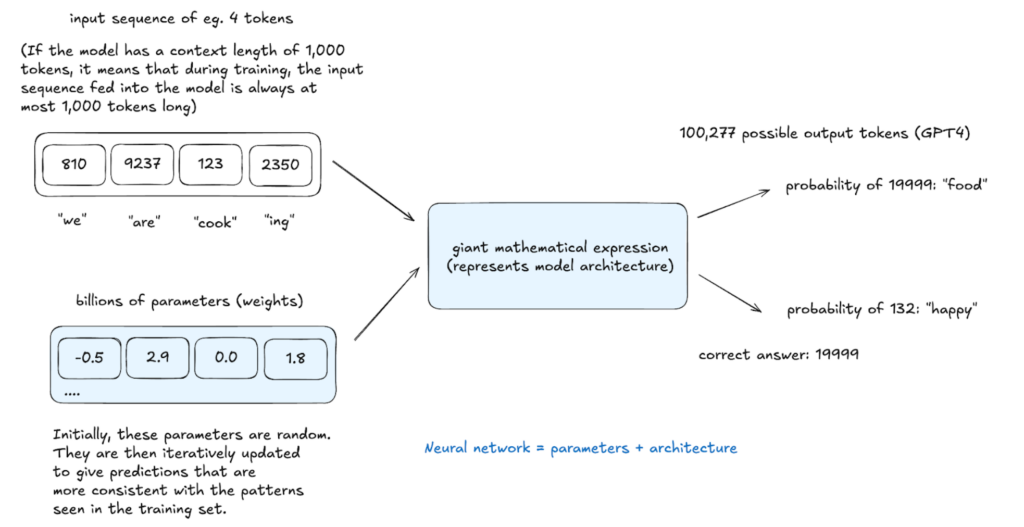
Le modèle de base résultant comprend les relations de mots et les modèles statistiques mais manque d'optimisation des tâches réelles. Il fonctionne comme une saisie semi-automatique avancée, prédisant en fonction de la probabilité mais avec des capacités de suivi des instructions limitées. L'apprentissage dans le contexte, en utilisant des exemples dans des invites, peut être utilisé, mais une formation supplémentaire est nécessaire.
2. Post-entraînement: raffinage pour une utilisation pratique
Les modèles de basesont raffinés par la post-formation à l'aide d'ensembles de données plus petits et spécialisés. Ce n'est pas une programmation explicite mais une instruction plutôt implicite à travers des exemples structurés.
Les méthodes de post-formation comprennent:
Les jetons spéciaux sont introduits pour délimiter la saisie des utilisateurs et les réponses AI.
Inférence: génération de texte
L'inférence, effectuée à tout stade, évalue l'apprentissage du modèle. Le modèle attribue des probabilités à des jetons et des échantillons à proximité potentiels de cette distribution, créant du texte non explicitement dans les données de formation mais statistiquement cohérente avec elle. Ce processus stochastique permet des sorties variées de la même entrée.
Hallucinations: aborder les fausses informations
Hallucinations, où les LLM génèrent de fausses informations, découlent de leur nature probabiliste. Ils ne "connaissent" pas "les faits mais prédisent des séquences de mots probables. Les stratégies d'atténuation comprennent:
LLMS Accès aux connaissances à travers de vagues souvenirs (modèles de la pré-formation) et de la mémoire de travail (informations dans la fenêtre de contexte). Les invites du système peuvent établir une identité de modèle cohérente.
Conclusion (partie 1)
Cette partie a exploré les aspects fondamentaux du développement de LLM. La partie 2 se plongera dans l'apprentissage du renforcement et examinera les modèles de pointe. Vos questions et suggestions sont les bienvenues!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Recommandation de classement des logiciels de détection de matériel informatique
Recommandation de classement des logiciels de détection de matériel informatique
 Méthode de saisie des symboles dérivés
Méthode de saisie des symboles dérivés
 Nom de domaine de site Web gratuit
Nom de domaine de site Web gratuit
 Classement des dix principales plateformes de trading formelles
Classement des dix principales plateformes de trading formelles
 Suffixe du nom du fichier de modification par lots Linux
Suffixe du nom du fichier de modification par lots Linux
 méthode d'ouverture du fichier cdr
méthode d'ouverture du fichier cdr
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend
 introduction à la commande route add
introduction à la commande route add








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



