

Formation de grands modèles de langue: de TRPO à Grpo

Deepseek: une plongée profonde dans l'apprentissage du renforcement pour LLMS
Le succès récent de Deepseek, réalisant des performances impressionnantes à des coûts inférieurs, met en évidence l'importance des méthodes de formation du modèle grand langage (LLM). Cet article se concentre sur l'aspect d'apprentissage du renforcement (RL), Explore Trpo, PPO et les algorithmes GRPO plus récents. Nous minimiserons les mathématiques complexes pour la rendre accessible, en supposant une familiarité de base avec l'apprentissage automatique, l'apprentissage en profondeur et les LLM.
Trois piliers de la formation LLM

La formation LLM implique généralement trois phases clés:
- Pré-formation: Le modèle apprend à prédire le jeton suivant dans une séquence à partir de jetons précédents en utilisant un ensemble de données massif.
- Fonction d'adaptation supervisée (SFT): Les données ciblées affinent le modèle, l'alignant avec des instructions spécifiques.
- Apprentissage par renforcement (RLHF): Cette étape, l'objectif de cet article, affine davantage les réponses à mieux faire correspondre les préférences humaines grâce à une rétroaction directe.
Fondamentaux d'apprentissage du renforcement

L'apprentissage du renforcement implique un agent interagir avec un environnement . L'agent existe dans un État spécifique , en prenant actions pour passer à de nouveaux États. Chaque action se traduit par une récompense de l'environnement, guidant les actions futures de l'agent. Pensez à un robot naviguant dans un labyrinthe: sa position est l'état, les mouvements sont des actions, et atteindre la sortie fournit une récompense positive.
rl dans les LLMS: un look détaillé

Dans la formation LLM, les composants sont:
- Agent: le LLM lui-même.
- Environnement: Facteurs externes comme les invites utilisateur, les systèmes de rétroaction et les informations contextuelles.
- Actions: Les jetons génèrent le LLM en réponse à une requête.
- État: la requête actuelle et les jetons générés (réponse partielle).
- Récompenses: Habituellement déterminées par un modèle de récompense distinct formé sur des données annotées par l'homme, des réponses de classement aux scores d'attribution. Les réponses de meilleure qualité reçoivent des récompenses plus élevées. Des récompenses plus simples et basées sur des règles sont possibles dans des cas spécifiques, tels que Deepseekmath.
La politique détermine l'action à prendre. Pour un LLM, il s'agit d'une distribution de probabilité sur les jetons possibles, utilisés pour goûter le jeton suivant. La formation RL ajuste les paramètres de la politique (poids du modèle) pour favoriser les jetons à récompense plus élevé. La politique est souvent représentée comme:
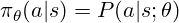
Le cœur de RL est de trouver la politique optimale. Contrairement à l'apprentissage supervisé, nous utilisons des récompenses pour guider les ajustements de politique.
trpo (optimisation des politiques de la région de confiance)

trpo utilise une fonction d'avantage, analogue à la fonction de perte dans l'apprentissage supervisé, mais dérivé de récompenses:
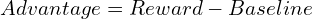
trpo maximise un objectif de substitution, contraint d'empêcher les écarts de politique importants de l'itération précédente, assurant la stabilité:
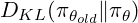
PPO (optimisation de la politique proximale)
PPO, désormais préféré pour les LLM comme Chatgpt et Gemini, simplifie Trpo en utilisant un objectif de substitution coupé, limitant implicitement les mises à jour de la politique et améliorant l'efficacité de calcul. La fonction d'objectif PPO est:

grpo (optimisation de la politique relative du groupe)
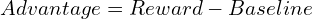
GRPO rationalise la formation en éliminant le modèle de valeur séparé. Pour chaque requête, il génère un groupe de réponses et calcule l'avantage en tant que score Z basé sur leurs récompenses:
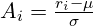
Cela simplifie le processus et est bien adapté à la capacité de LLMS à générer plusieurs réponses. GRPO intègre également un terme de divergence KL, en comparant la politique actuelle à une politique de référence. La formulation GRPO finale est:

Conclusion
L'apprentissage du renforcement, en particulier le PPO et le GRPO plus récent, est crucial pour la formation LLM moderne. Chaque méthode s'appuie sur les fondamentaux de RL, offrant différentes approches pour équilibrer la stabilité, l'efficacité et l'alignement humain. Le succès de Deepseek tire parti de ces progrès, ainsi que d'autres innovations. L'apprentissage du renforcement est sur le point de jouer un rôle de plus en plus dominant dans la progression des capacités LLM.
Références: (Les références restent les mêmes, juste reformatées pour une meilleure lisibilité)
- [1] "Fondations des modèles de grande langue", 2025. https://www.php.cn/link/fbf8ca43dcc014c2c94549d6b8ca0375
- [2] "Apprentissage par renforcement". Enaris. Disponible sur: https://www.php.cn/link/20e169b48c8f869887e2bbe1c5c3ea65
- [3] Y. Gokhale. «Introduction à LLMS et à la partie générative AI 5: RLHF» [4] L. Weng. «Un aperçu de l'apprentissage par renforcement», 2018. Disponible sur: https://www.php.cn/link/fc42bad715bcb9767ddd95a239552434 [5] "Deepseek-R1: la capacité de raisonnement d'incitation dans les LLM via l'apprentissage par renforcement", 2025.
- https://www.php.cn/link/d0ae1e3078807c85d78d64f4ded5cdcb > [6] "Deepseekmath: repousser les limites du raisonnement mathématique dans les modèles de langage ouvert", 2025.
- https://www.php.cn/link/f8b18593cdbb1ce289330560a44e33aa > [7] "Trust Region Policy Optimization", 2017.
- https://www.php.cn/link/77a44d5cfb595b3545d61aa742268c9b
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1671
1671
 14
1428
52
1331
25
1276
29
1256
24
14
1428
52
1331
25
1276
29
1256
24

 Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Tout en travaillant sur une IA agentique, les développeurs se retrouvent souvent à naviguer dans les compromis entre la vitesse, la flexibilité et l'efficacité des ressources. J'ai exploré le cadre de l'IA agentique et je suis tombé sur Agno (plus tôt c'était Phi-
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
La version comprend trois modèles distincts, GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano, signalant une évolution vers des optimisations spécifiques à la tâche dans le paysage du modèle grand langage. Ces modèles ne remplacent pas immédiatement les interfaces orientées utilisateur comme
 Au-delà du drame de lama: 4 nouvelles références pour les modèles de grande langue
Apr 14, 2025 am 11:09 AM
Au-delà du drame de lama: 4 nouvelles références pour les modèles de grande langue
Apr 14, 2025 am 11:09 AM
Benchmarks en difficulté: une étude de cas de lama Début avril 2025, Meta a dévoilé sa suite de modèles Llama 4, avec des métriques de performance impressionnantes qui les ont placés favorablement contre des concurrents comme GPT-4O et Claude 3.5 Sonnet. Au centre du launc
 Nouveau cours court sur les modèles d'intégration par Andrew Ng
Apr 15, 2025 am 11:32 AM
Nouveau cours court sur les modèles d'intégration par Andrew Ng
Apr 15, 2025 am 11:32 AM
Déverrouiller la puissance des modèles d'intégration: une plongée profonde dans le nouveau cours d'Andrew Ng Imaginez un avenir où les machines comprennent et répondent à vos questions avec une précision parfaite. Ce n'est pas de la science-fiction; Grâce aux progrès de l'IA, cela devient un R
 Comment les jeux de TDAH, les outils de santé et les chatbots d'IA transforment la santé mondiale
Apr 14, 2025 am 11:27 AM
Comment les jeux de TDAH, les outils de santé et les chatbots d'IA transforment la santé mondiale
Apr 14, 2025 am 11:27 AM
Un jeu vidéo peut-il faciliter l'anxiété, se concentrer ou soutenir un enfant atteint de TDAH? Au fur et à mesure que les défis de la santé augmentent à l'échelle mondiale - en particulier chez les jeunes - les innovateurs se tournent vers un outil improbable: les jeux vidéo. Maintenant l'un des plus grands divertissements du monde Indus
 Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simuler les lancements de fusée avec Rocketpy: un guide complet Cet article vous guide à travers la simulation des lancements de fusées haute puissance à l'aide de Rocketpy, une puissante bibliothèque Python. Nous couvrirons tout, de la définition de composants de fusée à l'analyse de Simula
 Google dévoile la stratégie d'agent la plus complète au cloud prochain 2025
Apr 15, 2025 am 11:14 AM
Google dévoile la stratégie d'agent la plus complète au cloud prochain 2025
Apr 15, 2025 am 11:14 AM
Gemini comme fondement de la stratégie d'IA de Google Gemini est la pierre angulaire de la stratégie d'agent AI de Google, tirant parti de ses capacités multimodales avancées pour traiter et générer des réponses à travers le texte, les images, l'audio, la vidéo et le code. Développé par Deepm
