

Dans ce blog, nous créerons une application d'explication de code multilingue pour présenter les capacités de Llama 3.3, en particulier ses forces de raisonnement, suivant les instructions, le codage et le support multilingue.
Cette application permettra aux utilisateurs de:
L'application sera construite en utilisant:
Nous allons passer directement à la construction de notre application Llama 3.3, mais si vous souhaitez d'abord un aperçu du modèle, consultez ce guide sur Llama 3.3. Commençons!
Pour commencer, nous allons diviser cela en quelques étapes. Tout d'abord, nous couvrirons comment accéder à Llama 3.3 à l'aide de la face de câlins, configurer votre compte et obtenir les autorisations nécessaires. Ensuite, nous allons créer l'environnement du projet et installer les dépendances requises.
Une façon d'accéder à Llama 3.3 est via Hugging Face, l'une des plates-formes les plus populaires pour l'hébergement de modèles d'apprentissage automatique. Pour utiliser LLAMA 3.3 via API d'inférence de Hugging Face, vous aurez besoin:
Avec l'accès au modèle sécurisé, configurons l'environnement de l'application. Tout d'abord, nous allons créer un dossier pour ce projet. Ouvrez votre terminal, accédez à l'endroit où vous souhaitez créer votre dossier de projet et exécutez:
mkdir multilingual-code-explanation cd multilingual-code-explanation
Ensuite, nous allons créer un fichier appelé app.py pour maintenir le code: toucher app.pynow, nous créons un environnement, et nous l'activons:
python3 -m venv venv source venv/bin/activate’
Maintenant que l'environnement est prêt, installons les bibliothèques nécessaires. Assurez-vous que vous exécutez Python 3.8. Dans le terminal, exécutez la commande suivante pour installer Streamlit, Demandes et Embring Face Libraries:
pip install streamlit requests transformers huggingface-hub
Maintenant, vous devriez avoir:
Maintenant que la configuration est terminée, nous sommes prêts à créer l'application! Dans la section suivante, nous commencerons à coder l'étape par étape de l'application d'explication de code multilingue.
Le backend communique avec l'API Face étreint pour envoyer l'extrait de code et recevoir l'explication.
Tout d'abord, nous devons importer la bibliothèque de demandes. Cette bibliothèque nous permet d'envoyer des demandes HTTP aux API. En haut de votre fichier app.py, écrivez:
mkdir multilingual-code-explanation cd multilingual-code-explanation
Pour interagir avec l'API LLAMA 3.3 hébergée sur le visage étreint, vous avez besoin:
python3 -m venv venv source venv/bin/activate’
dans le code ci-dessus:
Maintenant, nous allons écrire une fonction pour envoyer une demande à l'API. La fonction sera:
pip install streamlit requests transformers huggingface-hub
L'invite dit à Llama 3.3 d'expliquer l'extrait de code dans la langue souhaitée.
Avertissement: j'ai expérimenté différentes invites pour trouver celle qui a produit la meilleure sortie, donc il y avait certainement un élément d'ingénierie rapide impliquée!
Ensuite, la charge utile est définie. Pour l'entrée, nous spécifions que l'invite est envoyée au modèle. Dans les paramètres, MAX_NEW_TOKENS contrôle la longueur de réponse, tandis que la température ajuste le niveau de créativité de la sortie.
La fonction remanie.post () envoie les données à la face étreinte. Si la réponse est réussie (status_code == 200), le texte généré est extrait. S'il y a une erreur, un message descriptif est renvoyé.
Enfin, il y a des étapes pour nettoyer et formater correctement la sortie. Cela garantit qu'il est bien présenté, ce qui améliore considérablement l'expérience utilisateur.
Le frontend est l'endroit où les utilisateurs interagiront avec l'application. Streamlit est une bibliothèque qui crée des applications Web interactives avec juste du code Python et rend ce processus simple et intuitif. C'est ce que nous allons utiliser pour construire le frontend de notre application. J'aime vraiment le rationalisation pour construire des démos et POC!
En haut de votre fichier app.py, ajoutez:
mkdir multilingual-code-explanation cd multilingual-code-explanation
Nous utiliserons set_page_config () pour définir le titre et la mise en page de l'application. Dans le code ci-dessous:
python3 -m venv venv source venv/bin/activate’
Pour aider les utilisateurs à comprendre comment utiliser l'application, nous allons ajouter des instructions à la barre latérale: dans le code ci-dessous:
pip install streamlit requests transformers huggingface-hub
Nous allons ajouter le titre principal et le sous-titre à la page:
import requests
Maintenant, pour permettre aux utilisateurs de coller du code et de choisir leur langue préférée, nous avons besoin de champs d'entrée. Parce que le texte du code est susceptible d'être plus long que le nom de la langue, nous choisissons une zone de texte pour le code et une entrée de texte pour la langue:
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}Nous ajoutons maintenant un bouton pour générer l'explication. Si l'utilisateur entre dans le code et la langue, puis clique sur le bouton Générer l'explication, une réponse est générée.
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"Lorsque le bouton est cliqué, l'application:
Pour conclure, ajoutons un pied de page:
import streamlit as st
Il est temps d'exécuter l'application! Pour lancer votre application, exécutez ce code dans le terminal:
st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")
L'application s'ouvrira dans votre navigateur, et vous pouvez commencer à jouer avec!

Maintenant que nous avons construit notre application d'explication de code multilingue, il est temps de tester le fonctionnement du modèle. Dans cette section, nous utiliserons l'application pour traiter quelques extraits de code et évaluer les explications générées dans différentes langues.
Pour notre premier test, commençons par un script Python qui calcule le factoriel d'un nombre en utilisant Recursion. Voici le code que nous utiliserons:
st.sidebar.title("How to Use the App")
st.sidebar.markdown("""
1. Paste your code snippet into the input box.
2. Enter the language you want the explanation in (e.g., English, Spanish, French).
3. Click 'Generate Explanation' to see the results.
""")
st.sidebar.divider()
st.sidebar.markdown(
"""
<div >
Made with ♡ by Ana
</div>
""",
unsafe_allow_html=True
)Ce script définit une fonction récursive factorielle (n) qui calcule le factoriel d'un numéro donné. Pour NUM = 5, la fonction calculera 5 × 4 × 3 × 2 × 1, ce qui en résulte 120. Le résultat est imprimé à l'écran à l'aide de l'instruction PRINT (). Voici la sortie lorsque nous générons une explication en espagnol:
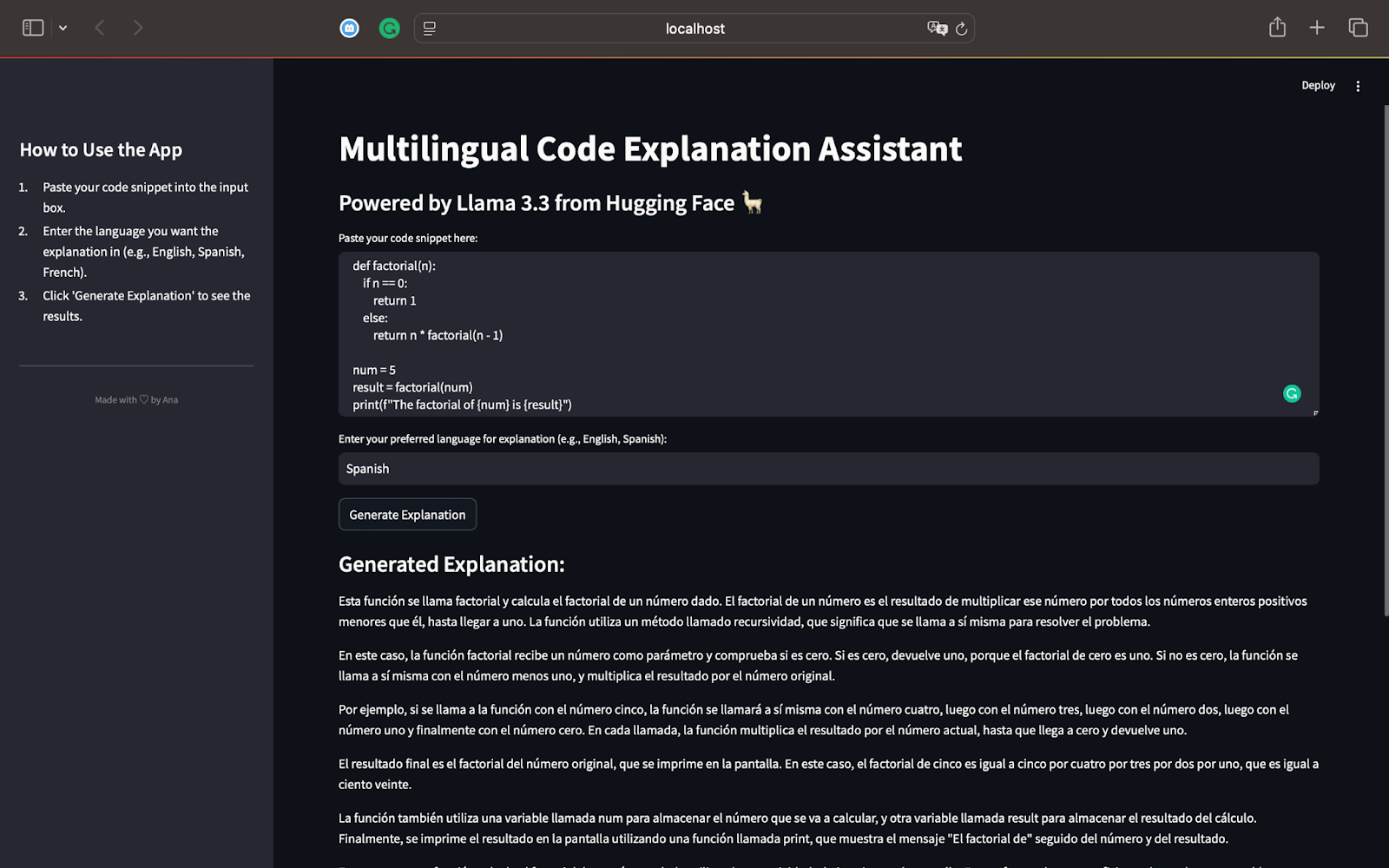

En tant que conférencier espagnol, je peux confirmer que l'explication identifie correctement que le code calcule le factoriel d'un nombre en utilisant la récursivité. Il explique comment la récursivité fonctionne étape par étape, la décomposant en termes simples.
Le modèle explique le processus de récursivité et montre comment la fonction s'appelle avec des valeurs décroissantes de n jusqu'à ce qu'elle atteigne 0.
L'explication est entièrement en espagnol, comme demandé, démontrant les capacités multilingues de Llama 3.3.
L'utilisation de phrases simples rend le concept de récursivité facile à suivre, même pour les lecteurs qui ne connaissent pas la programmation.
Il résume et mentionne comment la récursivité fonctionne pour d'autres entrées comme 3 et l'importance de la récursivité en tant que concept efficace de résolution de problèmes dans la programmation.
Ce premier test met en évidence la puissance de Llama 3.3:
Maintenant que nous avons testé un script Python, nous pouvons passer à d'autres langages de programmation comme JavaScript ou SQL. Cela nous aidera à explorer davantage les capacités de Llama 3.3 à travers le raisonnement, le codage et le support multilingue.
Dans ce test, nous évaluerons dans quelle mesure l'application d'explication du code multilingue gère une fonction JavaScript et génère une explication en français.
Nous utilisons l'extrait de code JavaScript suivant dans lequel j'ai intentionnellement choisi des variables ambiguës pour voir à quel point le modèle gère ceci:
mkdir multilingual-code-explanation cd multilingual-code-explanation
cet extrait de code définit une fonction récursive x (a) qui calcule le factoriel d'un numéro donné a. La condition de base vérifie si A === 1. Si c'est le cas, il renvoie 1. Sinon, la fonction s'appelle avec A - 1 et multiplie le résultat par a. La constante Y est définie sur 6, donc la fonction x calcule 6 × 5 × 4 × 3 × 2 × 1. Fnally, le résultat est stocké dans la variable Z et affiché à l'aide de Console.log. Voici la sortie et la traduction en anglais:

Remarque: vous pouvez voir qu'il semble que la réponse est soudainement recadrée, mais c'est parce que nous avons limité la sortie à 500 jetons!
Après avoir traduit cela, j'ai conclu que l'explication identifie correctement que la fonction x (a) est récursive. Il décompose le fonctionnement de la récursivité, expliquant le cas de base (a === 1) et le boîtier récursif (a * x (a - 1)). L'explication montre explicitement comment la fonction calcule le factoriel de 6 et mentionne les rôles de Y (la valeur d'entrée) et Z (le résultat). Il note également comment Console.log est utilisé pour afficher le résultat.
L'explication est entièrement en français, comme demandé. Les termes techniques tels que «récursif» (récursif), «Facteurrielle» (factoriel) et «produit» (produit) sont utilisés correctement. Et pas seulement cela, il identifie que ce code calcule le factoriel d'un nombre de manière récursive.
L'explication évite le jargon trop technique et simplifie la récursivité, ce qui le rend accessible aux lecteurs nouveaux en programmation.
Ce test démontre que Llama 3.3:
Maintenant que nous avons testé l'application avec Python et JavaScript, passons à le tester avec une requête SQL pour évaluer davantage ses capacités multilingues et de raisonnement.
Dans ce dernier test, nous évaluerons comment l'application d'explication de code multilingue gère une requête SQL et génère une explication en allemand. Voici l'extrait SQL utilisé:
mkdir multilingual-code-explanation cd multilingual-code-explanation
Cette requête sélectionne la colonne ID et calcule la valeur totale (sum (b.value)) pour chaque ID. Il lit les données de deux tableaux: Table_X (aliasé en A) et Table_y (aliasé comme b). Ensuite, utilise une condition de jointure pour connecter les lignes où a.ref_id = b.ref. Il filtre les lignes où B.Flag = 1 et regroupe les données par A.Id. La clause a filtre les groupes pour inclure uniquement ceux où la somme de B.Value est supérieure à 1000. Enfin, il ordonne les résultats de Total_amount en ordre décroissant.
Après avoir appuyé sur le bouton d'explication Générer, c'est ce que nous obtenons:

L'explication générée est concise, précise et bien structurée. Chaque clause SQL clé (sélectionnez, de, jointure, où, groupe par, ayant et ordre par) est clairement expliquée. De plus, la description correspond à l'ordre d'exécution dans SQL, qui aide les lecteurs à suivre la logique de requête étape par étape.
L'explication est entièrement en allemand, comme demandé.
Les termes SQL clés (par exemple, "filtert", "GruppIert", "trient") sont utilisés avec précision dans le contexte. L'explication identifie que le fait d'être utilisé pour filtrer les résultats groupés, qui est une source courante de confusion pour les débutants. Il explique également l'utilisation des alias (AS) pour renommer les tables et les colonnes pour plus de clarté.
L'explication évite la terminologie trop complexe et se concentre sur la fonction de chaque clause. Cela permet aux débutants de comprendre comment fonctionne la requête.
Ce test démontre que Llama 3.3:
Nous avons testé l'application avec des extraits de code dans Python, JavaScript et SQL, générant des explications en espagnol, français et allemand. Dans chaque test:
Avec ce test, nous avons confirmé que l'application que nous avons créée est polyvalente, fiable et efficace pour expliquer le code dans différents langages de programmation et langages naturels.
Félicitations! Vous avez construit un assistant d'explication de code multilingue entièrement fonctionnel en utilisant Streamlit et Llama 3.3 de l'étreinte Face.
Dans ce tutoriel, vous avez appris:
Ce projet est un excellent point de départ pour explorer les capacités de Llama 3.3 dans le raisonnement de code, le support multilingue et le contenu pédagogique. N'hésitez pas à créer votre propre application pour continuer à explorer les fonctionnalités puissantes de ce modèle!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



