
 Périphériques technologiques
IA
Maîtriser le chiffon multimodal avec le sommet Ai et les Gémeaux pour le contenu
Périphériques technologiques
IA
Maîtriser le chiffon multimodal avec le sommet Ai et les Gémeaux pour le contenu
Maîtriser le chiffon multimodal avec le sommet Ai et les Gémeaux pour le contenu

La génération augmentée de récupération multimodale (RAG) a révolutionné l'accès des modèles de langue (LLM) et utilise des données externes, allant au-delà des limitations traditionnelles du texte uniquement. La prévalence croissante des données multimodales nécessite d'intégrer le texte et les informations visuelles pour une analyse complète, en particulier dans des domaines complexes comme la finance et la recherche scientifique. Le RAG multimodal y parvient en permettant aux LLM de traiter à la fois le texte et les images, conduisant à une meilleure récupération des connaissances et à un raisonnement plus nuancé. Cet article détaille la construction d'un système de chiffons multimodal à l'aide des modèles Gémeaux de Google, du sommet AI et de Langchain, vous guidant à travers chaque étape: configuration de l'environnement, prétraitement des données, génération d'intégration et création d'un moteur de recherche de documents robuste.
Objectifs d'apprentissage clés
- Saisissez le concept de chiffon multimodal et son importance dans l'amélioration des capacités de récupération des données.
- comprendre comment les Gémeaux traitent et intègrent des données textuelles et visuelles.
- Apprenez à tirer parti des capacités de Vertex AI pour construire des modèles d'IA évolutifs adaptés aux applications en temps réel.
- Explorez le rôle de Langchain dans l'intégration de LLMS de manière transparente aux sources de données externes.
- Développer des cadres efficaces qui utilisent des informations textuelles et visuelles pour des réponses précises et consacrées au contexte.
- Appliquer ces techniques à des cas d'utilisation pratiques tels que la génération de contenu, les recommandations personnalisées et les assistants de l'IA.
Cet article fait partie du blogathon de la science des données.
Table des matières
- Rag multimodal: un aperçu complet
- Les technologies de base utilisées
- L'architecture du système expliquée
- Construire un système de chiffon multimodal avec Vertex Ai, Gemini et Langchain
- Étape 1: Configuration de l'environnement
- Étape 2: Google Cloud Project Détails
- Étape 3: Vertex Ai Initialisation du SDK
- Étape 4: Importation de bibliothèques nécessaires
- Étape 5: Spécifications du modèle
- Étape 6: Ingestion de données
- Étape 7: Création et déploiement d'un sommet de recherche de vecteur de sommet et point de terminaison
- Étape 8: Retriever Création et chargement de document
- Étape 9: Construction de la chaîne avec Retriever et Gemini LLM
- Étape 10: Test de modèle
- Applications du monde réel
- Conclusion
- Les questions fréquemment posées
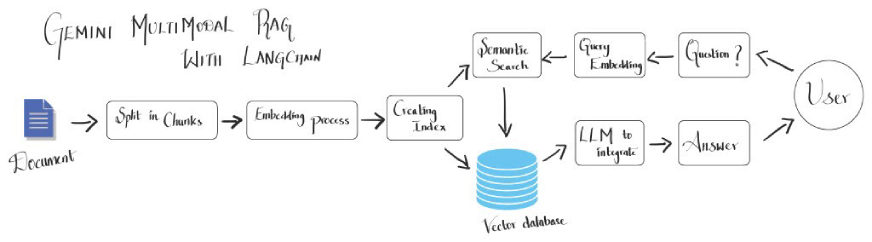
Rag multimodal: un aperçu complet
Les systèmes de chiffons multimodaux combinent des informations visuelles et textuelles pour fournir des sorties plus riches et plus contextuelles. Contrairement aux LLM traditionnelles à base de texte, les systèmes de chiffons multimodaux sont conçus pour ingérer et traiter le contenu visuel tel que les graphiques, les graphiques et les images. Cette capacité à double transformation est particulièrement bénéfique pour l'analyse des ensembles de données complexes où les éléments visuels sont aussi informatifs que le texte, tels que des rapports financiers, des publications scientifiques ou des manuels techniques.
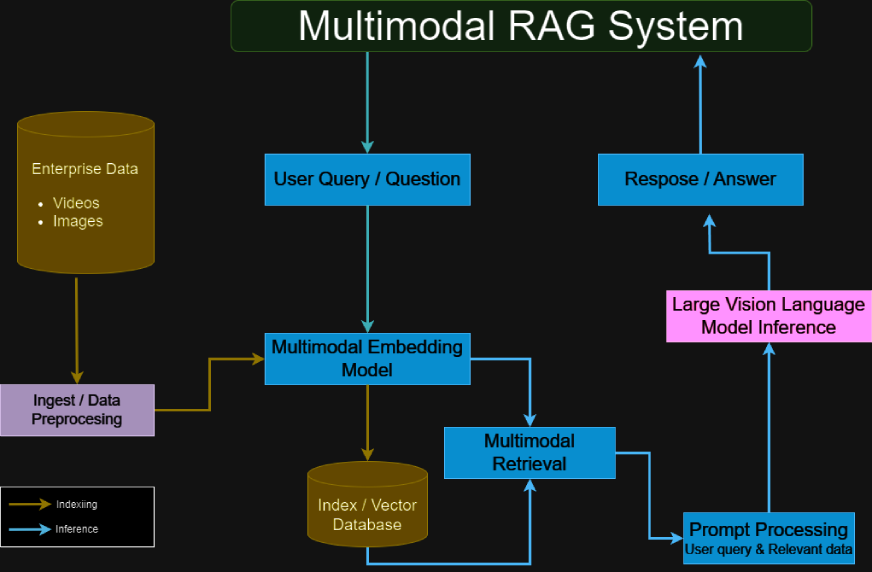
En traitant à la fois du texte et des images, le modèle acquiert une compréhension plus profonde des données, ce qui entraîne des réponses plus précises et perspicaces. Cette intégration atténue le risque de générer des informations trompeuses ou factuellement incorrectes (un problème courant dans l'apprentissage automatique), conduisant à des résultats plus fiables pour la prise de décision et l'analyse.
Les technologies de base utilisées
Cette section résume les technologies clés utilisées:
- Gémeaux de Google DeepMind: Une puissante suite AI générative conçue pour les tâches multimodales, capable de traiter et de générer de la texte et d'images. .
- Vertex AI: Une plate-forme complète pour développer, déploier et mettre à l'échelle des modèles d'apprentissage automatique, avec une fonction de recherche de vecteurs robuste pour une récupération efficace de données multimodales.
- Langchain: un cadre qui simplifie l'intégration des LLM avec divers outils et sources de données, facilitant la connexion entre les modèles, les incorporations et les ressources externes.
- Framework de génération (RAG) de la récupération (RAG): Un cadre qui combine des modèles basés sur la récupération et basés sur la génération pour améliorer la précision de la réponse en récupérant le contexte pertinent à partir de sources externes avant de générer des sorties, idéales pour gérer le contenu multimodal.
- Openai's Dall · e: (facultatif) Un modèle de génération d'image qui convertit le texte en invite en contenu visuel, améliorant les sorties de chiffon multimodales avec des images contextuellement pertinentes.
- Transformers pour le traitement multimodal: L'architecture sous-jacente pour gérer les types d'entrée mixtes, permettant un traitement efficace et une génération de réponse impliquant à la fois des données de texte et visuelles.
L'architecture du système expliquée
Un système de chiffon multimodal comprend généralement:
- Gémeaux pour le traitement multimodal: gère les entrées de texte et d'image, en extraction des informations détaillées de chaque modalité.
- Vertex Ai Vector Recherche: fournit une base de données vectorielle pour une gestion efficace de la gestion et de la récupération des données.
- Langchain MultivectorRetriever: agit comme intermédiaire, récupérant les données pertinentes de la base de données vectorielle basée sur les requêtes utilisateur.
- Intégration du cadre de chiffon: combine des données récupérées avec les capacités génératives du LLM pour créer des réponses précises et riches en contexte.
- Encodeur multimodal-décodeur: Processus et fusibles du contenu textuel et visuel, garantissant que les deux types de données contribuent efficacement à la sortie.
- Transformers pour la gestion des données hybrides: utilise des mécanismes d'attention pour aligner et intégrer les informations de différentes modalités.
- Pipelines de réglage fin: Procédures de formation personnalisées (facultatives) qui optimisent les performances du modèle basées sur des ensembles de données multimodaux spécifiques pour une précision améliorée et une compréhension contextuelle.
(Les sections restantes, les étapes 1 à 10, les applications pratiques, la conclusion et les FAQ, suivraient un modèle similaire de reformulation et de restructuration pour maintenir la signification d'origine tout en évitant la répétition textuelle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
Hé là, codant ninja! Quelles tâches liées au codage avez-vous prévues pour la journée? Avant de plonger plus loin dans ce blog, je veux que vous réfléchissiez à tous vos malheurs liés au codage - les énumérez. Fait? - Let & # 8217
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
La récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
 AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
Le paysage de l'IA de cette semaine: un tourbillon de progrès, de considérations éthiques et de débats réglementaires. Les principaux acteurs comme Openai, Google, Meta et Microsoft ont déclenché un torrent de mises à jour, des nouveaux modèles révolutionnaires aux changements cruciaux de LE
 GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
Introduction Openai a publié son nouveau modèle basé sur l'architecture «aux fraises» très attendue. Ce modèle innovant, connu sous le nom d'O1, améliore les capacités de raisonnement, lui permettant de réfléchir à des problèmes Mor
 Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Introduction Imaginez vous promener dans une galerie d'art, entourée de peintures et de sculptures vives. Maintenant, que se passe-t-il si vous pouviez poser une question à chaque pièce et obtenir une réponse significative? Vous pourriez demander: «Quelle histoire racontez-vous?
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Le rapport de l'indice de l'intelligence artificielle de 2025 publié par le Stanford University Institute for Human-oriented Artificial Intelligence offre un bon aperçu de la révolution de l'intelligence artificielle en cours. Interprétons-le dans quatre concepts simples: cognition (comprendre ce qui se passe), l'appréciation (voir les avantages), l'acceptation (défis face à face) et la responsabilité (trouver nos responsabilités). Cognition: l'intelligence artificielle est partout et se développe rapidement Nous devons être très conscients de la rapidité avec laquelle l'intelligence artificielle se développe et se propage. Les systèmes d'intelligence artificielle s'améliorent constamment, obtenant d'excellents résultats en mathématiques et des tests de réflexion complexes, et il y a tout juste un an, ils ont échoué lamentablement dans ces tests. Imaginez des problèmes de codage complexes de résolution de l'IA ou des problèmes scientifiques au niveau des diplômés - depuis 2023
