

AI est partout.
Il est difficile de ne pas interagir au moins une fois par jour avec un modèle grand langage (LLM). Les chatbots sont là pour rester. Ils sont dans vos applications, ils vous aident à mieux écrire, ils composent les e-mails, ils lisent les e-mails… eh bien, ils font beaucoup.
Et je ne pense pas que ce soit mauvais. En fait, mon opinion est l'inverse - du moins jusqu'à présent. Je défends et plaide pour l'utilisation de l'IA dans notre vie quotidienne parce que, d'accord, cela rend tout beaucoup plus facile.
Je n'ai pas à passer du temps à lire un document pour trouver des problèmes de ponctuation ou un type. AI fait ça pour moi. Je ne perds pas de temps à écrire cet e-mail de suivi chaque lundi. AI fait ça pour moi. Je n'ai pas besoin de lire un contrat énorme et ennuyeux quand j'ai une IA pour résumer les principaux plats à emporter et les points d'action!
Ce ne sont que quelques-unes des grandes utilisations de l'IA. Si vous souhaitez en savoir plus sur les cas d'utilisation de LLMS pour nous faciliter la vie, j'ai écrit un livre entier à leur sujet.
Maintenant, en pensant comme un scientifique des données et en regardant le côté technique, tout n'est pas aussi brillant et brillant.
LLMS sont parfaits pour plusieurs cas d'utilisation généraux qui s'appliquent à quiconque ou à une entreprise. Par exemple, le codage, le résumé ou la réponse aux questions sur le contenu général créé jusqu'à la date de coupure de la formation. Cependant, en ce qui concerne les applications commerciales spécifiques, dans un seul but, ou quelque chose de nouveau qui n'a pas fait la date de coupure, c'est à ce moment que les modèles ne seront pas aussi utiles s'ils sont utilisés hors de la boîte - ce qui signifie qu'ils ne connaîtront pas la réponse. Ainsi, il faudra des ajustements.
Formation Un modèle LLM peut prendre des mois et des millions de dollars. Ce qui est encore pire, c'est que si nous n'adaptons pas et ne réglons pas le modèle à notre objectif, il y aura des résultats ou des hallucinations insatisfaisants (lorsque la réponse du modèle n'a pas de sens compte tenu de notre requête).
Alors, quelle est la solution, alors? Dépenser beaucoup d'argent à recycler le modèle pour inclure nos données?
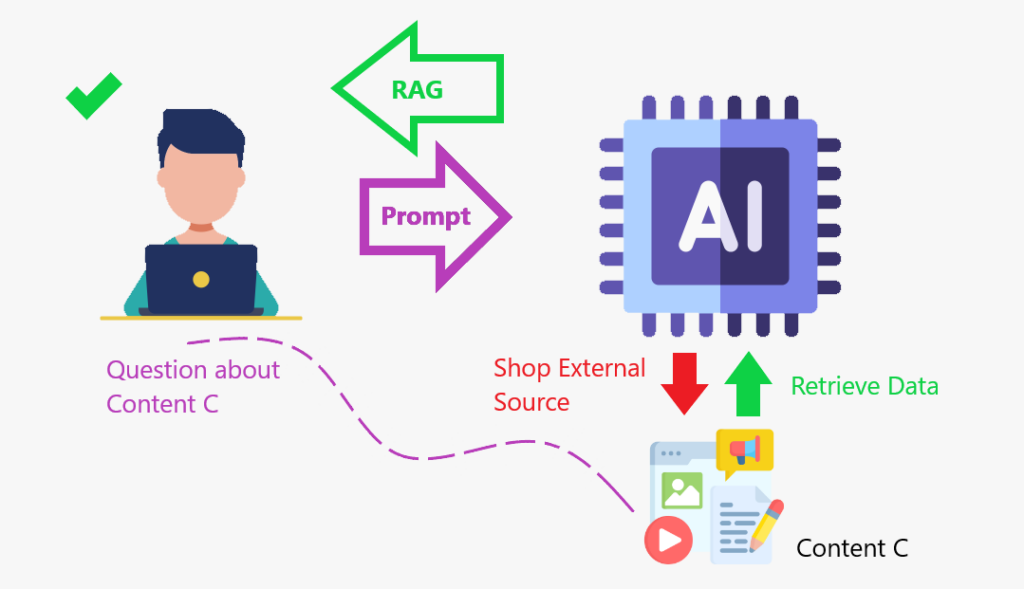
pas vraiment. C'est à ce moment que la génération (RAG) (RAG) de la récupération devient utile.
Rag est un cadre qui combine l'obtention d'informations à partir d'une base de connaissances externe avec des modèles de gros langues (LLM). Il aide les modèles d'IA à produire des réponses plus précises et pertinentes.
Apprenez-en plus sur le chiffon ensuite.
Permettez-moi de vous raconter une histoire pour illustrer le concept.
J'adore les films. Pendant un certain temps dans le passé, je savais quels films étaient en compétition pour la meilleure catégorie de films aux Oscars ou aux meilleurs acteurs et actrices. Et je saurais certainement lequel a obtenu la statue de cette année. Mais maintenant, je suis tout rouillé sur ce sujet. Si vous me demandiez qui était en compétition, je ne le saurais pas. Et même si j'essayais de vous répondre, je vous donnerais une réponse faible.
Donc, pour vous fournir une réponse de qualité, je ferai ce que tout le monde fait: rechercher les informations en ligne, les obtenir, puis la donner. Ce que je viens de faire est la même idée que le chiffon: j'ai obtenu des données d'une base de données externe pour vous donner une réponse.
Lorsque nous améliorons le LLM avec un Store de contenu où il peut aller et récupérer les données à augmenter (augmenter) sa base de connaissances, c'est-à-dire le cadre de chiffon en action.
Rag, c'est comme créer un magasin de contenu où le modèle peut améliorer ses connaissances et répondre plus précisément.
résumer:
Maintenant que nous savons quel est le framework de chiffon, comprenons pourquoi nous devrions l'utiliser.
Voici quelques-uns des avantages:
Comme expliqué précédemment, j'aime dire qu'avec le framework de chiffon, nous donnons un moteur de recherche interne pour le contenu que nous voulons qu'il ajoute à la base de connaissances.
Eh bien. Tout cela est très intéressant. Mais voyons une application de chiffon. Nous apprendrons à créer un assistant de lecteur PDF PDF alimenté par AI.
Il s'agit d'une application qui permet aux utilisateurs de télécharger un document PDF et de poser des questions sur son contenu à l'aide d'outils de traitement du langage naturel (NLP) alimenté par AI.
décomposons les étapes pour une meilleure compréhension:
Préparer un magasin de contenu pour le LLM prendra quelques mesures, comme nous venons de le voir. Alors, commençons par créer une fonction qui peut charger un fichier et la diviser en morceaux de texte pour une récupération efficace.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunksEnsuite, nous commencerons à créer notre application Streamlit, et nous utiliserons cette fonction dans le script suivant.
Nous commencerons à importer les modules nécessaires dans Python. La plupart d'entre eux proviendront des packages de Langchain.
FAISS est utilisé pour la récupération de documents; Openaiembeddings transforme les morceaux de texte en scores numériques pour un meilleur calcul de similitude par le LLM; Chatopenai est ce qui nous permet d'interagir avec l'API OpenAI; CREATE_RETRRIEVAL_CHAIN est ce que fait réellement le chiffon, récupérant et augmentant le LLM avec ces données; create_stuff_documents_chain colle le modèle et le chatpromptTemplate.
Remarque: vous devrez générer une clé OpenAI pour pouvoir exécuter ce script. Si c'est la première fois que vous créez votre compte, vous obtenez des crédits gratuits. Mais si vous l'avez depuis un certain temps, il est possible que vous deviez ajouter 5 dollars de crédits pour pouvoir accéder à l'API d'Openai. Une option consiste à utiliser l'intégration de l'étreinte.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Ce premier extrait de code créera le titre de l'application, créera une boîte pour le téléchargement de fichiers et préparera le fichier à ajouter à la fonction load_document ().
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")Les machines comprennent mieux les nombres que le texte, donc en fin de compte, nous devrons fournir au modèle une base de données de nombres qu'il peut comparer et vérifier la similitude lors de l'exécution d'une requête. C'est là que les intégres seront utiles pour créer le vector_db, dans ce prochain morceau de code.
# Generate embeddings # Embeddings are numerical vector representations of data, typically used to capture relationships, similarities, # and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), # recommender systems, and search engines. embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002") # Can also use HuggingFaceEmbeddings # from langchain_huggingface.embeddings import HuggingFaceEmbeddings # embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create vector database containing chunks and embeddings vector_db = FAISS.from_documents(chunks, embeddings)
Ensuite, nous créons un objet Retriever pour naviguer dans le vector_db.
# Create a document retriever retriever = vector_db.as_retriever() llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY)
Ensuite, nous créerons le System_Prompt, qui est un ensemble d'instructions sur le LLM sur la façon de répondre, et nous créerons un modèle d'invite, en le préparant à être ajouté au modèle une fois que nous aurons obtenu la contribution de l'utilisateur.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunksEn continuant, nous créons le noyau du framework RAG, collant ensemble l'objet Retriever et l'invite. Cet objet ajoute des documents pertinents à partir d'une source de données (par exemple, une base de données vectorielle) et le rend prêt à être traité à l'aide d'un LLM pour générer une réponse.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Enfin, nous créons la question de la variable pour l'entrée utilisateur. Si cette boîte de questions est remplie d'une requête, nous la transmettons à la chaîne, qui appelle le LLM pour traiter et retourner la réponse, qui sera imprimée sur l'écran de l'application.
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")Voici une capture d'écran du résultat.
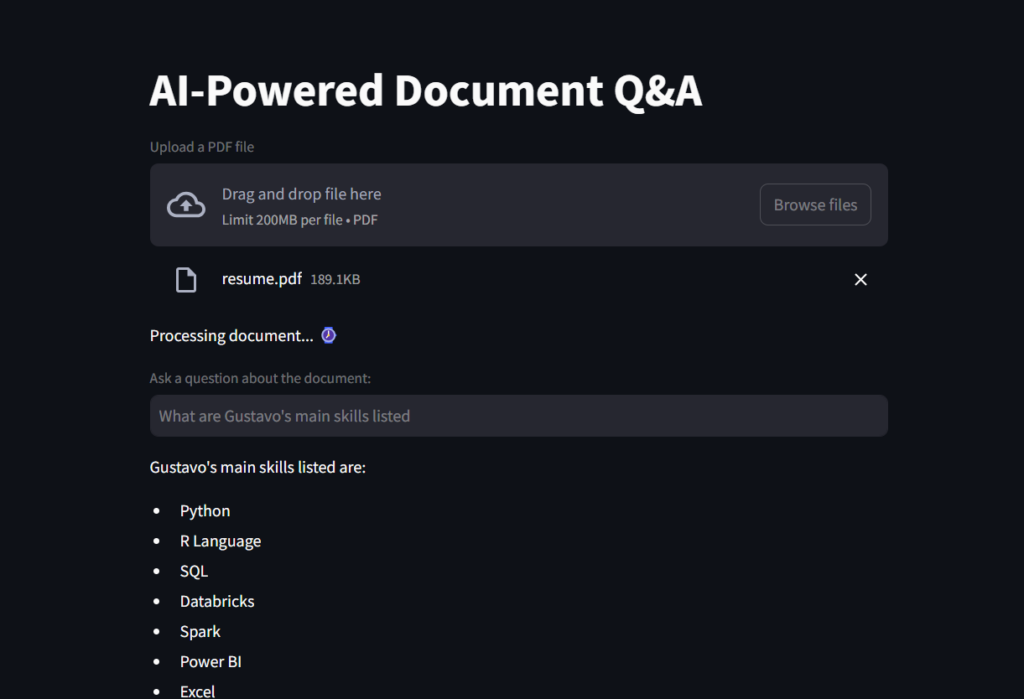
Et c'est un GIF pour vous de voir l'assistant AI du lecteur de fichiers en action!

Dans ce projet, nous avons appris ce qu'est le framework RAG et comment il aide le LLM à mieux fonctionner et aussi bien avec des connaissances spécifiques.
L'IA peut être alimentée avec les connaissances d'un manuel d'instructions, des bases de données d'une entreprise, des fichiers financiers ou des contrats, puis de régler de façon affinée pour répondre avec précision aux requêtes de contenu spécifiques au domaine. La base de connaissances est augmentée avec un magasin de contenu.
Pour récapituler, c'est ainsi que fonctionne le cadre:
1️⃣ Requête utilisateur → Le texte d'entrée est reçu.
2️⃣ Récupérer les documents pertinents → Recherche une base de connaissances (par exemple, une base de données, magasin vectoriel).
3️⃣ Contexte d'augmentation → Des documents récupérés sont ajoutés à l'entrée.
4️⃣ générer une réponse → Un LLM traite l'entrée combinée et produit une réponse.
https://github.com/gurezende/basic-rag
Si vous avez aimé ce contenu et que vous souhaitez en savoir plus sur mon travail, voici mon site Web, où vous pouvez également trouver tous mes contacts.
https://gustavorsantos.me
https://cloud.google.com/Use-Cases/Retrieval-augmented-Generation
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://youtu.be/t-d1ofcdw1m?si=g0uwfh5-wznmu0nw
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-your-own-openai-api-key
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre le compte de service WeChat et le compte officiel
La différence entre le compte de service WeChat et le compte officiel
 Comment illuminer le moment des amis proches de Douyin
Comment illuminer le moment des amis proches de Douyin
 Comment gérer le ralentissement de l'ordinateur et la lenteur des réponses
Comment gérer le ralentissement de l'ordinateur et la lenteur des réponses
 esd en iso
esd en iso
 Introduction aux fichiers de configuration php
Introduction aux fichiers de configuration php
 Comment nettoyer le lecteur C lorsqu'il devient rouge
Comment nettoyer le lecteur C lorsqu'il devient rouge
 Comment gérer les caractères chinois tronqués sous Linux
Comment gérer les caractères chinois tronqués sous Linux
 monfreemp3
monfreemp3








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



