

Ce tutoriel démontre le réglage fin du modèle LLAMA 3.1-8B-IT pour l'analyse des sentiments de la santé mentale. Nous personnaliserons le modèle pour prédire l'état de santé mentale du patient à partir des données de texte, fusionner l'adaptateur avec le modèle de base et déployer le modèle complet sur le moyeu de face étreint. Surtout, n'oubliez pas que les considérations éthiques sont primordiales lors de l'utilisation de l'IA dans les soins de santé; Cet exemple est à des fins illustratives uniquement.
Nous couvrirons l'accès aux modèles LLAMA 3.1 via Kaggle, en utilisant la bibliothèque Transformers pour l'inférence et le processus de réglage fin lui-même. Une compréhension préalable de la fin de LLM (voir notre "un guide d'introduction aux LLMS de réglage fin") est bénéfique.

Image par auteur
Comprendre lama 3.1
Llama 3.1, Meta AI Multiplengual Language Model (LLM), excelle dans la compréhension et la génération des langues. Disponible en versions 8b, 70b et 405b, il est construit sur une architecture auto-régressive avec des transformateurs optimisés. Formé sur diverses données publiques, il prend en charge huit langues et possède une durée de contexte de 128k. Sa licence commerciale est facilement accessible, et elle surpasse plusieurs concurrents dans divers repères.
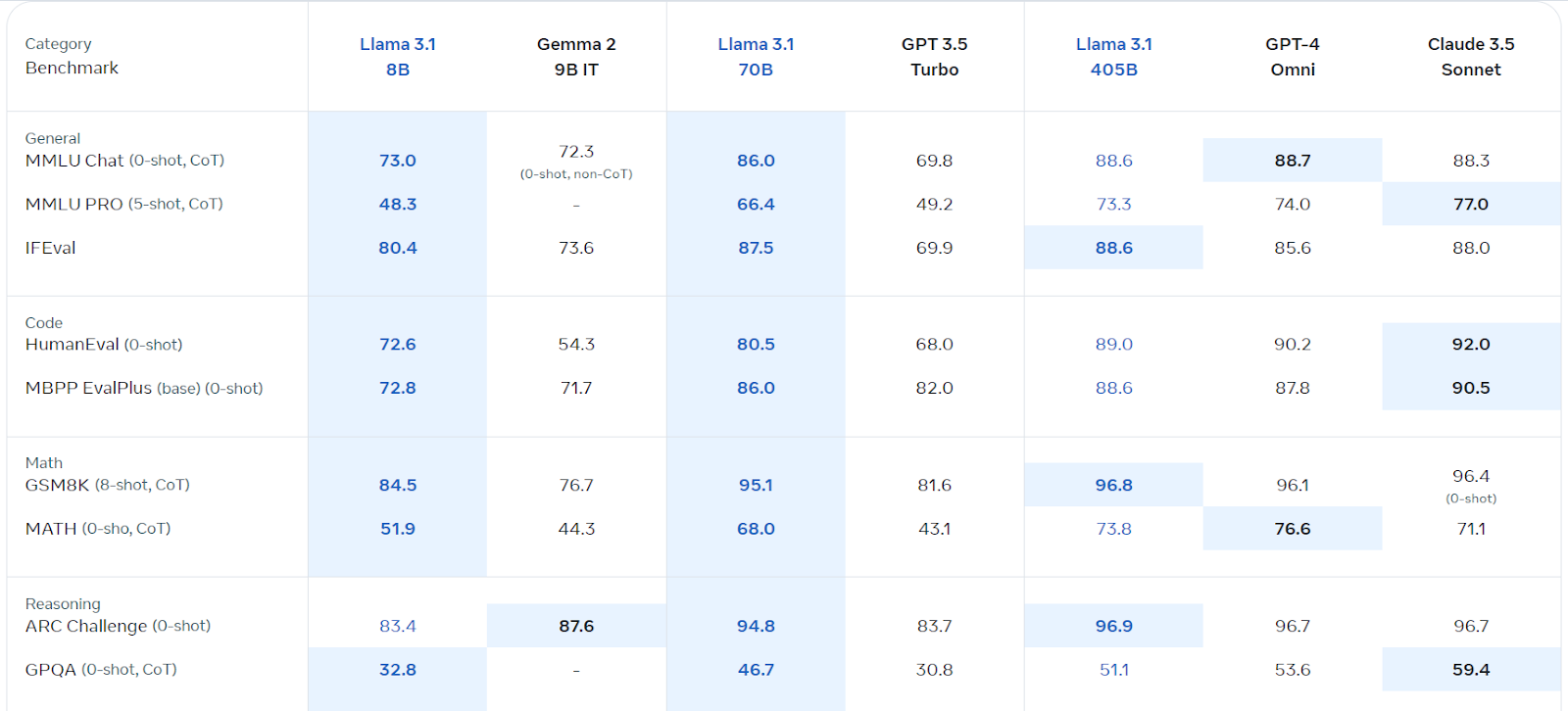
Source: Llama 3.1 (meta.com)
Accéder et utiliser Llama 3.1 sur Kaggle
Nous tirons parti des GPU / TPU gratuits de Kaggle. Suivez ces étapes:
%pip install -U transformers accelerate). from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, return_dict=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto")messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"]) 
LALAME FIEUX 3.1 pour la classification de la santé mentale
Configuration: Démarrez un nouvel ordinateur portable Kaggle avec Llama 3.1, installez les packages requis (bitsandbytes, transformers, accelerate, peft, trl), et ajoutez le jeu de données "analyse du sentiment pour la santé mentale". Configurer des poids et des biais (en utilisant votre clé API).
Traitement des données: Chargez l'ensemble de données, nettoyez-le (en supprimant les catégories ambiguës: "suicidaire", "stress", "trouble de la personnalité"), shuffle et division en ensembles de formation, d'évaluation et de test (en utilisant 3000 échantillons pour l'efficacité). Créer des invites incorporant des instructions et des étiquettes.
Chargement du modèle: Chargez le modèle LLAMA-3.1-8B-Istruct en utilisant la quantification 4 bits pour l'efficacité de la mémoire. Chargez le jeton et définissez l'ID de jeton de pad.
Évaluation de la pré-fin: Créer des fonctions pour prédire les étiquettes et évaluer les performances du modèle (précision, rapport de classification, matrice de confusion). Évaluez les performances de référence du modèle avant de faire des réglages.
Fonction de fin: Configurer LORA en utilisant les paramètres appropriés. Configurez les arguments de formation (ajustez au besoin pour votre environnement). Former le modèle en utilisant SFTTrainer. Surveiller les progrès en utilisant des poids et des biais.
Évaluation post-fin de la fin: réévaluez les performances du modèle après le réglage fin.
Fusion et économie: Dans un nouveau cahier Kaggle, fusionnez l'adaptateur affiné avec le modèle de base en utilisant PeftModel.from_pretrained() et model.merge_and_unload(). Testez le modèle fusionné. Enregistrez et poussez le modèle final et le tokenizer sur le Hub Hub.
par vos chemins de fichier réels. Le code complet et les explications détaillées sont disponibles dans la réponse originale et plus longue. Cette version condensée fournit un aperçu de haut niveau et des extraits de code clés. Prioriser toujours les considérations éthiques lorsque vous travaillez avec des données sensibles. /kaggle/input/...
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



