

yolov11: une plongée profonde dans l'architecture et la mise en œuvre d'un modèle de détection d'objets de pointe
Les modèlesyolo (vous ne regardez une fois) que les modèles sont réputés pour leur efficacité et leur précision dans les tâches de vision par ordinateur, y compris la détection d'objets, la segmentation, l'estimation de la pose, etc. Cet article se concentre sur l'architecture et la mise en œuvre de la dernière itération, Yolov11, en utilisant Pytorch. Alors que les ultralytiques, les créateurs, hiérarchisent l'application pratique sur les articles de recherche formels, nous disséquerons sa conception et construire un modèle fonctionnel.
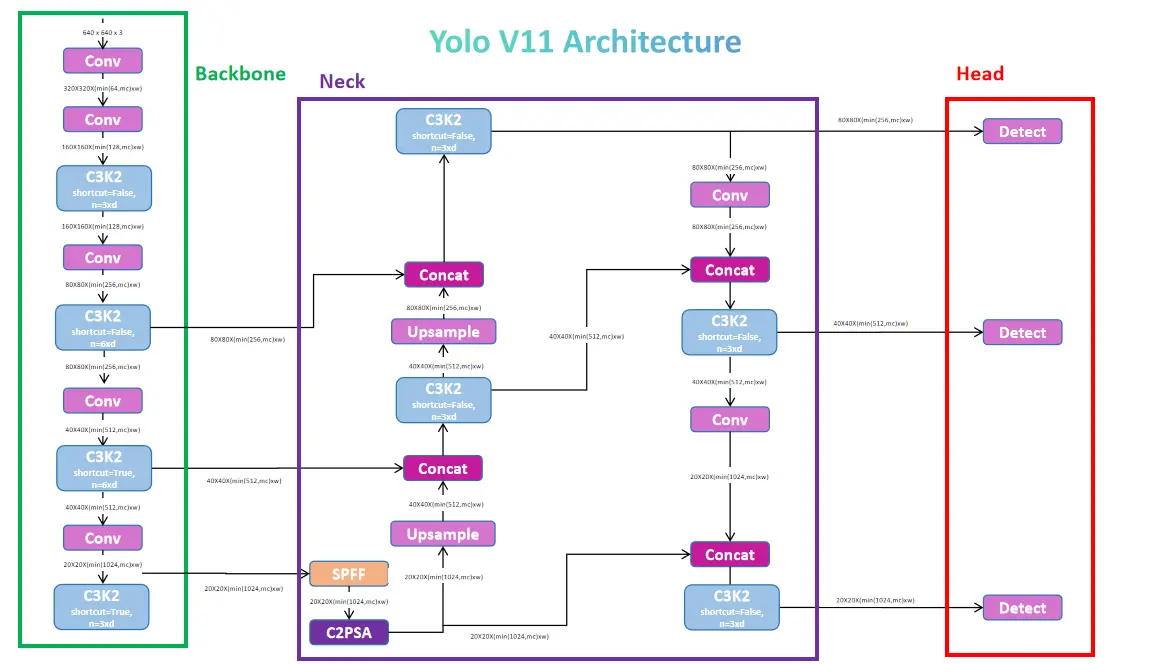
Comprendre l'architecture de Yolov11
yolov11, comme ses prédécesseurs, utilise une architecture en trois parties: squelette, cou et tête.
Détroélectricité: Extrait les fonctionnalités utilisant des blocs à base d'étranglement efficaces (C3K2, un raffinement du C2F de Yolov8). Cette colonne vertébrale, tirant parti de Darknet et DarkFPN, produit trois cartes de fonctionnalités (P3, P4, P5) représentant différents niveaux de détail.
cou: traite la sortie du squelette, fusionnant les caractéristiques à travers les échelles en utilisant l'échantillonnage et la concaténation. Un composant crucial est le bloc C2PSA, incorporant des modules d'attention spatiale partielle (PSA) pour améliorer la mise au point sur les informations spatiales pertinentes dans les caractéristiques de bas niveau.
tête: gère les prédictions spécifiques à la tâche. Pour la détection d'objets, il comprend:
Blocs de construction de base: Couches de convolution et de goulot d'étranglement
Le modèle s'appuie fortement sur:


Fixé sur l'implémentation du code (pytorch)
Les extraits de code suivants illustrent les composants clés:
(Simplifié pour la concision; reportez-vous à l'article d'origine pour le code complet.)
# Simplified Conv Block
class Conv(nn.Module):
def __init__(self, in_ch, out_ch, activation, ...):
# ... (Initialization code) ...
def forward(self, x):
return activation(self.norm(self.conv(x)))
# Simplified Bottleneck Block (Residual)
class Residual(nn.Module):
def __init__(self, ch, e=0.5):
# ... (Initialization code) ...
def forward(self, x):
return x + self.conv2(self.conv1(x))
# Simplified SPPF
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
# ... (Initialization code) ...
def forward(self, x):
# ... (MaxPooling and concatenation) ...
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
# ... (Other key blocks: C3K, C3K2, PSA, Attention, PSABlock, DFL) ...Construction et test du modèle
Le modèle complet Yolov11 est construit en combinant le squelette, le cou et la tête. Différentes tailles de modèle (nano, petite, moyenne, grande, xlARGE) sont obtenues en ajustant des paramètres comme la profondeur et la largeur. Le code fourni comprend une classe YOLOv11 pour faciliter cela.
Les tests de modèle avec un tenseur d'entrée aléatoire démontrent la structure de sortie (cartes de fonctionnalités en mode d'entraînement, prédictions concaténées en mode d'évaluation). Un traitement ultérieur (suppression non maximale) est nécessaire pour obtenir des détections d'objets finales.
Conclusion
yolov11 représente une progression significative de la détection d'objets, offrant une architecture puissante et efficace. Sa conception priorise les applications pratiques, ce qui en fait un outil précieux pour les projets d'IA du monde réel. L'architecture détaillée et les extraits de code fournissent une base solide pour la compréhension et le développement ultérieur. N'oubliez pas de consulter l'article d'origine pour le code complet et exécutable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Utilisation de uniqueResult
Utilisation de uniqueResult
 La base de données phpstudy ne peut pas démarrer la solution
La base de données phpstudy ne peut pas démarrer la solution
 Comment trouver la valeur maximale et minimale d'un élément de tableau en Java
Comment trouver la valeur maximale et minimale d'un élément de tableau en Java
 Introduction à la signification de javascript
Introduction à la signification de javascript
 Comment gérer les téléchargements de fichiers bloqués dans Windows 10
Comment gérer les téléchargements de fichiers bloqués dans Windows 10
 Quelles sont les fonctions de fenêtrage ?
Quelles sont les fonctions de fenêtrage ?
 Comment vider l'espace des documents cloud WPS lorsqu'il est plein ?
Comment vider l'espace des documents cloud WPS lorsqu'il est plein ?
 La différence entre rom et bélier
La différence entre rom et bélier








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



