

Snowpark: Apprentissage automatique dans la database avec flocon de neige
L'apprentissage automatique traditionnel implique souvent de déplacer des ensembles de données massifs des bases de données aux environnements de formation de modèle. Ceci est de plus en plus inefficace avec les grands ensembles de données d'aujourd'hui. SnowFlake Snowpark aborde cela en permettant un traitement en database. Snowpark fournit des bibliothèques et des temps d'exécution pour exécuter du code (Python, Java, Scala) directement dans le nuage de Snowflake, minimisant le mouvement des données et améliorant la sécurité.
Pourquoi choisir Snowpark?
Snowpark offre plusieurs avantages clés:
Début: un guide étape par étape
Ce tutoriel démontre la construction d'un modèle réglé par hyperparamètre en utilisant des neiges.
Configuration de l'environnement virtuel: Créez un environnement conda et installez les bibliothèques nécessaires (snowflake-snowpark-python, pandas, pyarrow, numpy, matplotlib, seaborn, ipykernel).
Ingestion de données: Importez des données d'échantillonnage (par exemple, l'ensemble de données des diamants Seaborn) dans une table de flocon de neige. (Remarque: Dans les scénarios du monde réel, vous travaillerez généralement avec les bases de données de flocon de neige existantes.)
Création de session Snowpark: Établissez une connexion à Snowflake en utilisant vos informations d'identification (nom de compte, nom d'utilisateur, mot de passe) stocké en toute sécurité dans un fichier config.py (ajouté à .gitignore).
Chargement des données: Utilisez la session de neige pour accéder et charger les données dans un snowpark dataframe.
Comprendre les données de données de neige
Snowpark DataFrames fonctionne paresseusement, créant une représentation logique des opérations avant de les traduire en requêtes SQL optimisées. Cela contraste avec l'exécution impatient de Pandas, offrant des gains de performances significatifs, en particulier avec les grands ensembles de données.
Quand utiliser des données de données neigeuses:
Utilisez des données de données de neige pour de grands ensembles de données où le transfert de données vers votre machine locale n'est pas pratique. Pour les ensembles de données plus petits, les pandas peuvent être suffisants. La méthode to_pandas() permet la conversion entre les neiges et Pandas DataFrames. La méthode Session.sql() fournit une alternative pour exécuter directement les requêtes SQL.
Snowpark dataframe Transformation Fonctions:
Les fonctions de transformation de Snowpark (importées comme F de snowflake.snowpark.functions) fournissent une interface puissante pour la manipulation des données. Ces fonctions sont utilisées avec des méthodes .select(), .filter() et .with_column().
Analyse des données exploratoires (EDA):
EDA peut être effectué en échantillonnant des données de la fragmentation des données de neige, en les convertissant en un Pandas DataFrame et en utilisant des bibliothèques de visualisation comme Matplotlib et SeaBorn. Alternativement, les requêtes SQL peuvent générer des données pour les visualisations.
Formation du modèle d'apprentissage automatique:
Nettoyage des données: Assurer que les types de données sont corrects et gérer tous les besoins de prétraitement (par exemple, les colonnes de renommage, les types de données de casting, le nettoyage des caractéristiques du texte).
Prétraitement: Utilisez Snowflake ML Pipeline avec OrdinalEncoder et StandardScaler pour prétraiter les données. Enregistrez le pipeline en utilisant joblib.
Formation du modèle: Former un modèle XGBOost (XGBRegressor) en utilisant les données prétraitées. Divisez les données en ensembles de formation et de test en utilisant random_split().
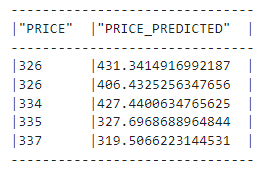
Évaluation du modèle: Évaluer le modèle à l'aide de mesures comme RMSE (mean_squared_error de snowflake.ml.modeling.metrics).
Tunage hyperparamètre: Utiliser RandomizedSearchCV pour optimiser les hyperparamètres du modèle.
Économie du modèle: Enregistrez le modèle formé et ses métadonnées vers le registre du modèle de Snowflake en utilisant la classe Registry.
Inférence: Effectuez l'inférence sur les nouvelles données en utilisant le modèle enregistré du registre.
Conclusion:
Snowpark fournit un moyen puissant et efficace d'effectuer l'apprentissage automatique dans la catabase. Son évaluation paresseuse, son intégration avec des bibliothèques familières et son registre de modèles en font un outil précieux pour gérer de grands ensembles de données. N'oubliez pas de consulter l'API Snowpark et les guides de développeur ML pour des fonctionnalités et des fonctionnalités plus avancées.












Remarque: Les URL de l'image sont conservées à partir de l'entrée. Le formatage est ajusté pour une meilleure lisibilité et une meilleure écoute. Les détails techniques sont conservés, mais la langue est rendue plus concise et accessible à un public plus large.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Utilisation de uniqueResult
Utilisation de uniqueResult
 La base de données phpstudy ne peut pas démarrer la solution
La base de données phpstudy ne peut pas démarrer la solution
 Comment trouver la valeur maximale et minimale d'un élément de tableau en Java
Comment trouver la valeur maximale et minimale d'un élément de tableau en Java
 Introduction à la signification de javascript
Introduction à la signification de javascript
 Comment gérer les téléchargements de fichiers bloqués dans Windows 10
Comment gérer les téléchargements de fichiers bloqués dans Windows 10
 Quelles sont les fonctions de fenêtrage ?
Quelles sont les fonctions de fenêtrage ?
 Comment vider l'espace des documents cloud WPS lorsqu'il est plein ?
Comment vider l'espace des documents cloud WPS lorsqu'il est plein ?
 La différence entre rom et bélier
La différence entre rom et bélier








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



