

Kimi K1.5: Un modèle de raisonnement AI génératif remodelant le paysage
Les récentes percées dans l'apprentissage par renforcement (RL) et les modèles de langues importants (LLM) ont culminé dans la création de Kimi K1.5, un modèle prêt à révolutionner le raisonnement générateur d'IA. Cet article plonge dans les caractéristiques clés de Kimi K1.5, les innovations et l'impact potentiel, tirant des informations sur la recherche qui l'accompagne.
Table des matières:
Qu'est-ce que Kimi K1.5?
Kimi K1.5 représente un bond en avant substantiel dans la mise à l'échelle de RL avec des LLM. Contrairement aux modèles conventionnels s'appuyant sur des méthodes complexes comme la recherche de Monte Carlo Tree, il utilise une approche rationalisée centrée sur la prédiction autorégressive et les techniques RL. Sa conception lui permet de gérer les tâches multimodales, présentant des performances exceptionnelles dans des références comme Math Vista et Live Code Bench.
Kimi K1.5 Formation
La formation de Kimi K1.5 est un processus en plusieurs étapes conçu pour améliorer le raisonnement via RL et l'intégration multimodale:
pré-entraînement: Le modèle est pré-entraîné sur un vaste ensemble de données multimodal de haute qualité englobant du texte (anglais, chinois, code, mathématiques, connaissances générales) et données visuelles, rigoureusement filtrées pour la pertinence et la diversité.
Affinement fin supervisé (SFT): Cela implique deux phases: Vanilla SFT en utilisant ~ 1 million d'exemples sur diverses tâches, et SFT de la chain de ce qui concerne (COT) pour la formation de voies de raisonnement complexes.
Apprentissage par renforcement (RL): Un ensemble invite soigneusement organisé entraîne la formation RL. Le modèle apprend à générer des solutions à travers une séquence d'étapes de raisonnement, guidée par un modèle de récompense évaluant la précision de la réponse. La descente de miroir en ligne optimise la politique.
Déployages partiels: Pour gérer efficacement les contextes longs, Kimi K1.5 utilise des déploiements partiels, économisant des parties inachevées pour la continuation ultérieure.
Pénalité de longueur et échantillonnage: Une pénalité de longueur encourage les réponses concises, tandis que le programme d'échantillonnage et la priorité des stratégies d'échantillonnage concentrent la formation sur les tâches plus faciles en premier.
Évaluation et itération: Évaluation continue contre les références guides les mises à jour du modèle itératif.
Kimi K1.5 Présentation du système et diagrammes de déploiement partiel:

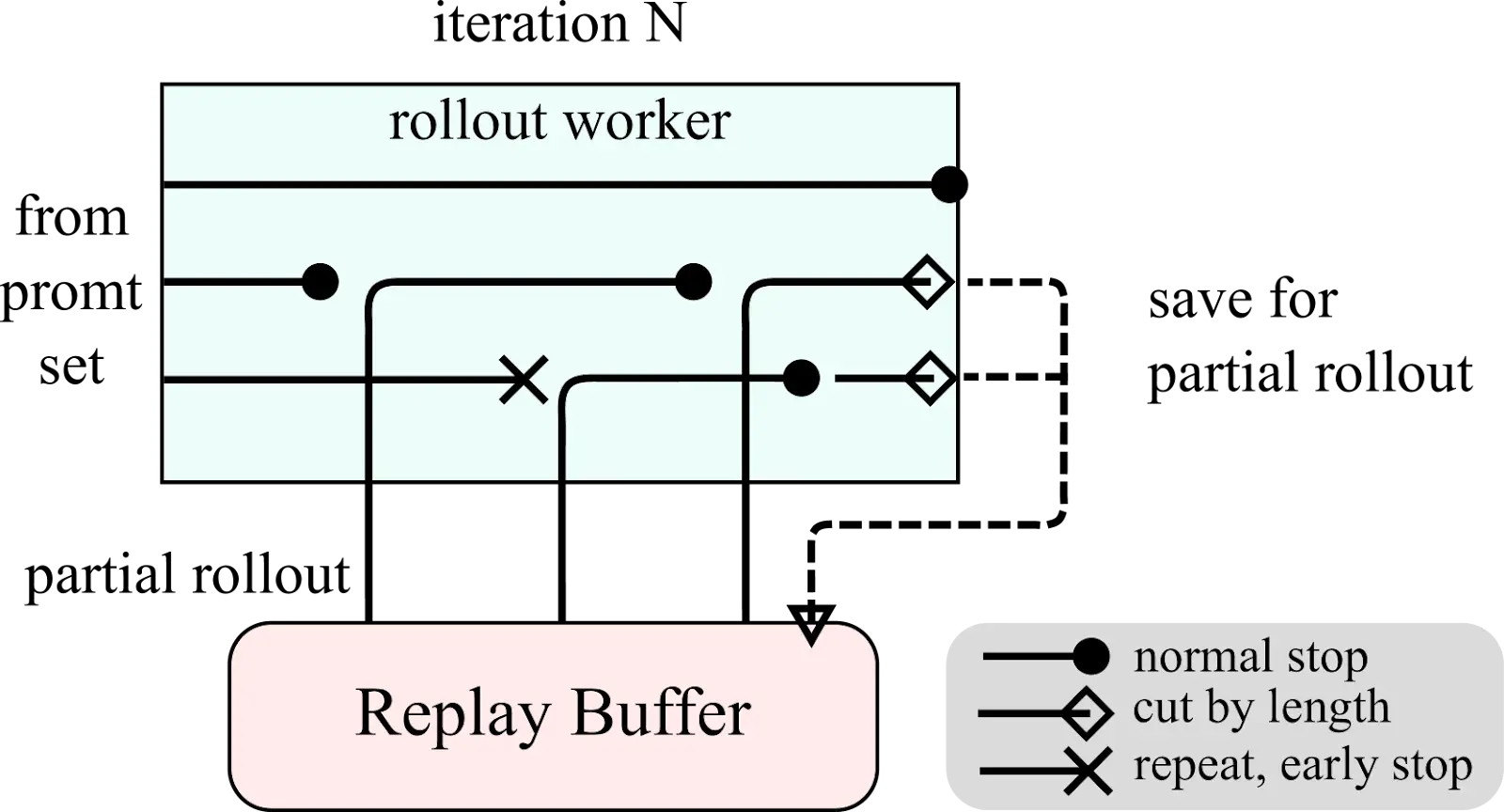
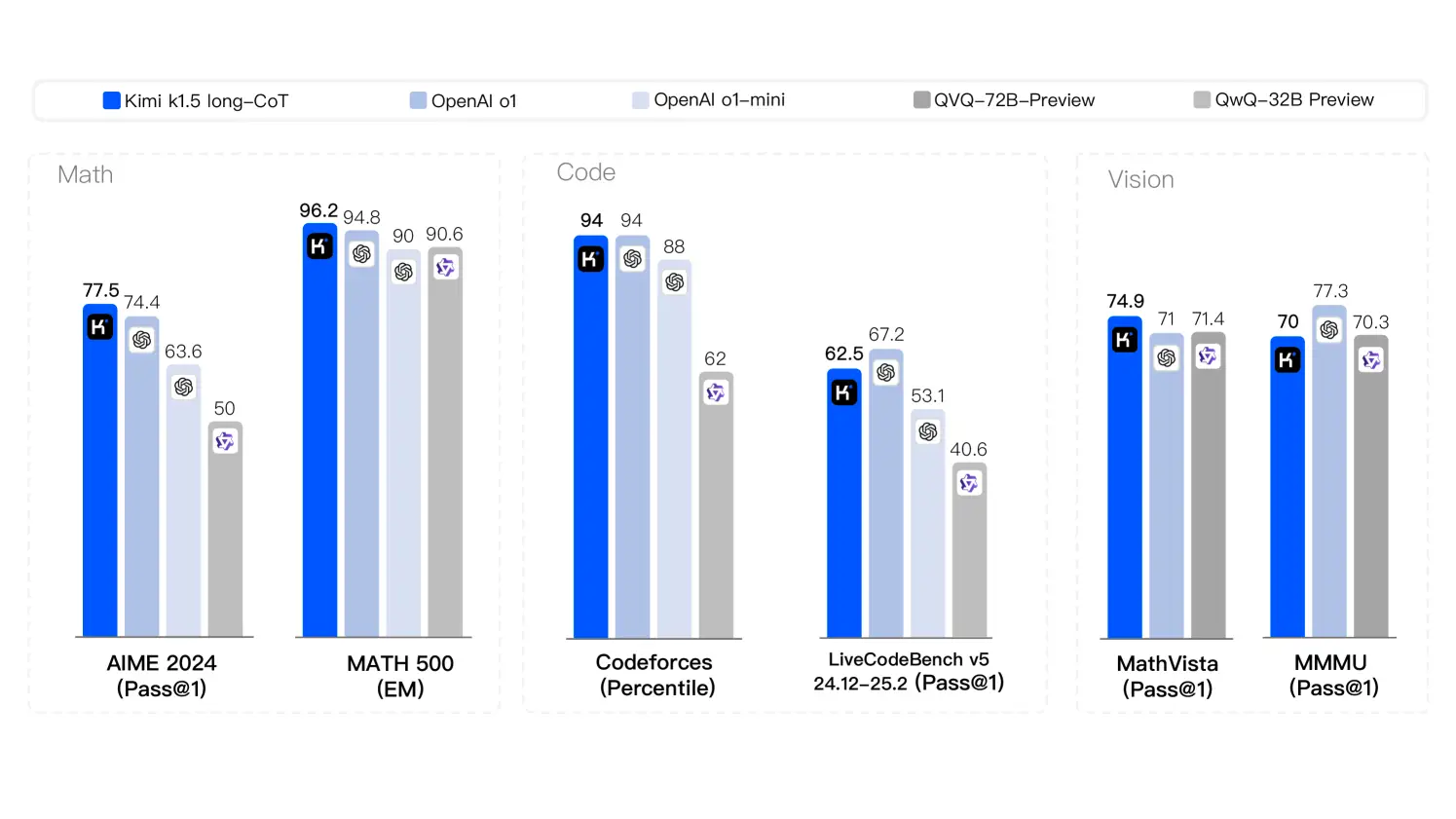
Kimi K1.5 Benchmarks
Kimi K1.5 démontre des performances de pointe dans diverses tâches:
Diagramme des stratégies de raisonnement:
Kimi K1.5 Innovations clés
Kimi K1.5 contre Deepseek R1
Kimi K1.5 et Deepseek R1 représentent différentes approches du développement de LLM. L'architecture rationalisée de Kimi K1.5, la RL intégrée et la manipulation du contexte long la distinguent-elles des méthodes plus traditionnelles de Deepseek R1. Les différences ont un impact sur leurs performances sur les tâches complexes et lourdes de contexte.
Accès à Kimi K1.5 via API
L'accès à l'API nécessite un enregistrement sur la console de gestion de Kimi. Un exemple de l'extrait de code Python montre l'interaction API:
# ... (API key setup and message preparation) ...
stream = client.chat.completions.create(
model="kimi-k1.5-preview",
messages=messages,
temperature=0.3,
stream=True,
max_tokens=8192,
)
# ... (streaming response handling) ...Conclusion
Kimi K1.5 représente une progression significative du raisonnement générateur d'IA, simplifiant la conception de RL tout en obtenant des résultats de pointe. Ses innovations dans la mise à l'échelle du contexte et la gestion des données multimodales la positionnent comme un modèle de premier plan avec de grandes implications dans diverses industries.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 CDMA télécom
CDMA télécom
 qu'est-ce que json
qu'est-ce que json
 Application officielle de l'échange euro-italien
Application officielle de l'échange euro-italien
 vc6.0
vc6.0
 Que dois-je faire si la vidéo Web ne peut pas être ouverte ?
Que dois-je faire si la vidéo Web ne peut pas être ouverte ?
 Comment insérer une vidéo en HTML
Comment insérer une vidéo en HTML
 Comment résoudre l'erreur d'analyse
Comment résoudre l'erreur d'analyse
 Win10 ne prend pas en charge la solution de configuration de disque du micrologiciel Uefi
Win10 ne prend pas en charge la solution de configuration de disque du micrologiciel Uefi








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



