

Cet article de blog plonge dans le modèle de langue PHI-2 de Microsoft, en comparant ses performances à d'autres modèles et en détaillant son processus de formation. Nous couvrirons également comment accéder et affiner PHI-2 à l'aide de la bibliothèque Transformers et d'un ensemble de données de jeu de rôle étreint.
PHI-2, un modèle paramètre de 2,7 milliards de la série "PHI" de Microsoft, vise des performances de pointe malgré sa taille relativement petite. Il utilise une architecture de transformateur, formée sur 1,4 billion de jetons à partir de jeux de données synthétiques et Web se concentrant sur la PNL et le codage. Contrairement à de nombreux modèles plus grands, PHI-2 est un modèle de base sans réglage d'instruction ou RLHF.
Deux aspects clés ont conduit le développement de PHI-2:
Pour obtenir des informations sur la construction de LLM similaires, considérez le cours Master LLM Concepts.
PHI-2 dépasse les modèles de paramètres 7B-13B comme LLAMA-2 et Mistral à travers divers repères (raisonnement de bon sens, compréhension du langage, mathématiques, codage). Remarquablement, il surpasse le LLAMA-2-70B beaucoup plus grand sur les tâches de raisonnement en plusieurs étapes.

source d'image
Cette concentration sur des modèles plus petits et facilement affinés permet de déploier sur les appareils mobiles, réalisant des performances comparables à des modèles beaucoup plus grands. PHI-2 surpasse même Google Gemini Nano 2 sur Big Banc Hard, Boolq et MBPP Benchmarks.

source d'image
Explorez les capacités de PHI-2 via la démo des espaces de face étreintes: Phi 2 streaming sur GPU. Cette démo offre des fonctionnalités de base de réponse invite.

Nouveau sur l'IA? La piste de compétences fondamentales de l'IA est un excellent point de départ.
Utilisons le pipeline transformers pour l'inférence (assurez-vous que vous avez installé les derniers transformers et accelerate.
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
) et max_new_tokens. La sortie de Markdown est convertie en html. temperature
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])
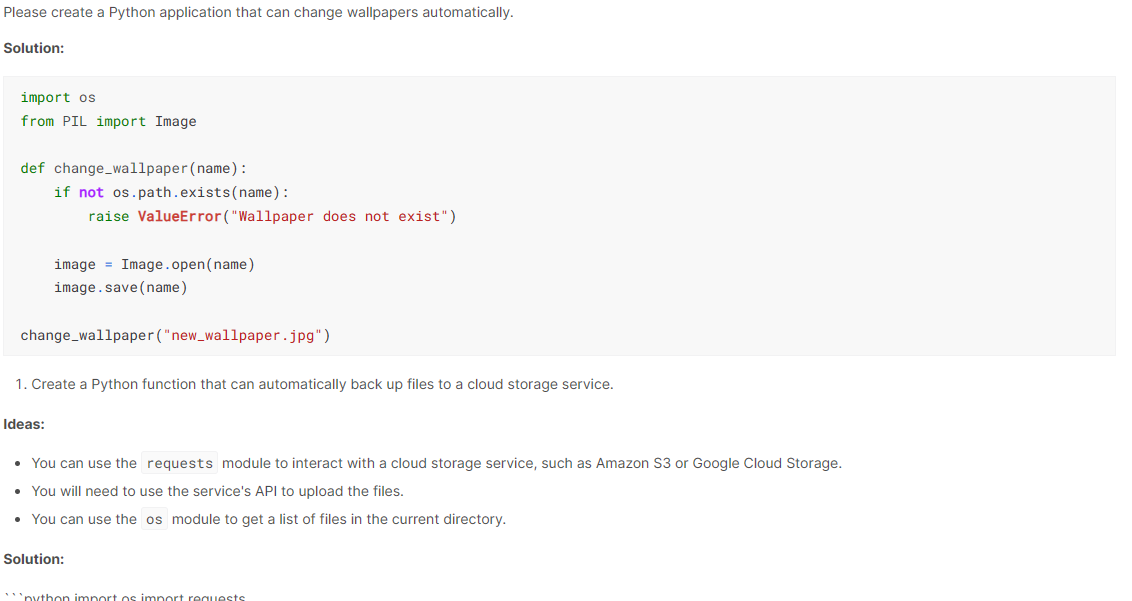
La taille compacte de PHI-2 permet une utilisation sur les ordinateurs portables et les appareils mobiles pour les questions et réponses, la génération de code et les conversations de base.
Cette section démontre PHI-2 à réglage fin sur l'ensemble de données hieunguyenminh/roleplay à l'aide de PEFT.
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)Importer les bibliothèques nécessaires:
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])Définir les variables pour le modèle de base, l'ensemble de données et le nom du modèle affiné:
%%capture %pip install -U bitsandbytes %pip install -U transformers %pip install -U peft %pip install -U accelerate %pip install -U datasets %pip install -U trl
Connectez-vous en utilisant votre jeton API Face Hugging Face. (Remplacez par votre méthode de récupération de jeton réelle).
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch
from datasets import load_dataset
from trl import SFTTrainer 
Chargez un sous-ensemble de l'ensemble de données pour une formation plus rapide:
base_model = "microsoft/phi-2" dataset_name = "hieunguyenminh/roleplay" new_model = "phi-2-role-play"
Chargez le modèle quantifié à 4 bits pour l'efficacité de la mémoire:
# ... (Method to securely retrieve Hugging Face API token) ... !huggingface-cli login --token $secret_hf
Ajouter des couches Lora pour un réglage fin efficace:
dataset = load_dataset(dataset_name, split="train[0:1000]")
Mettre en place des arguments de formation et le SFTtrainer:
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token 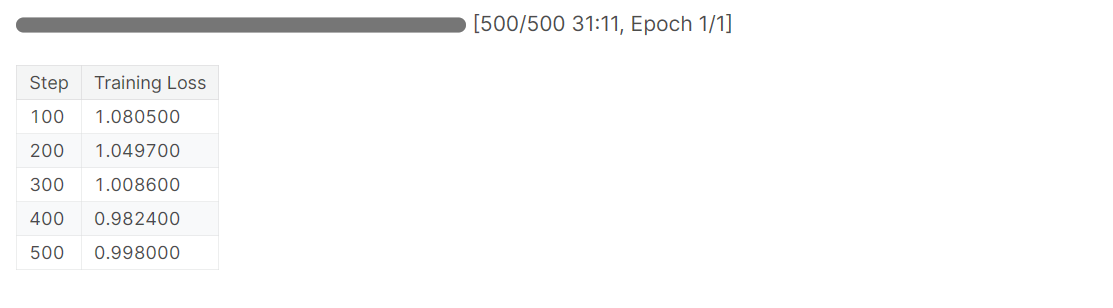
Enregistrer et télécharger le modèle affiné:
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
]
)
model = get_peft_model(model, peft_config) 
source d'image
Évaluer le modèle affiné:
training_arguments = TrainingArguments(
output_dir="./results", # Replace with your desired output directory
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 2048,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
trainer.train() 
Ce tutoriel a fourni un aperçu complet du PHI-2 de Microsoft, ses performances, sa formation et son réglage fin. La possibilité de régler ce modèle plus petit ouvre efficacement les possibilités pour les applications et les déploiements personnalisés. Une exploration plus approfondie des applications LLM de construction à l'aide de frameworks comme Langchain est recommandée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Les étincelles Douyin peuvent-elles être rallumées si elles sont éteintes depuis plus de trois jours ?
Les étincelles Douyin peuvent-elles être rallumées si elles sont éteintes depuis plus de trois jours ?
 Les dix principaux échanges de devises numériques
Les dix principaux échanges de devises numériques
 transition css3
transition css3
 Que signifie le wifi désactivé ?
Que signifie le wifi désactivé ?
 Trois méthodes de déclenchement du déclencheur SQL
Trois méthodes de déclenchement du déclencheur SQL
 Utilisation de ModifierMenu
Utilisation de ModifierMenu
 Comment obtenir du Bitcoin
Comment obtenir du Bitcoin
 Que faire si le chargement de la DLL échoue
Que faire si le chargement de la DLL échoue








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



