
 Périphériques technologiques
IA
Boupperie de la génération de texte de la génération de texte pour LLMS - Un changeur de jeu dans l'IA
Périphériques technologiques
IA
Boupperie de la génération de texte de la génération de texte pour LLMS - Un changeur de jeu dans l'IA
Boupperie de la génération de texte de la génération de texte pour LLMS - Un changeur de jeu dans l'IA

Exploiter la puissance de l'étreinte inférence de génération de texte de la face (TGI): votre serveur LLM local
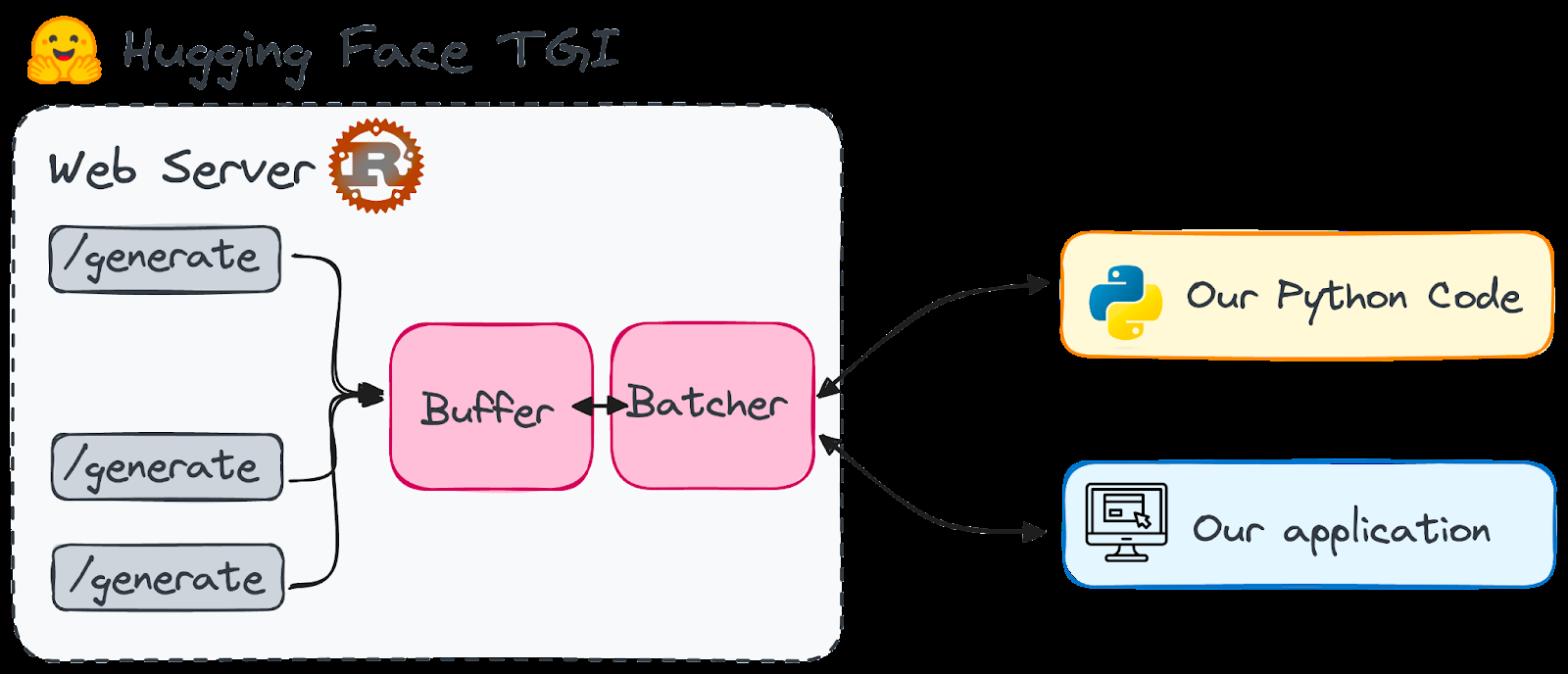
Les modèles de grandes langues (LLM) révolutionnent l'IA, en particulier dans la génération de texte. Cela a conduit à une augmentation des outils conçus pour simplifier le déploiement LLM. L'inférence de génération de texte de Hugging Face (TGI) se démarque, offrant un cadre puissant prêt pour la production pour exécuter LLMS localement en tant que service. Ce guide explore les capacités de TGI et montre comment en tirer parti pour la génération de texte AI sophistiquée.
comprendre le visage étreint tgi
TGI, un cadre de rouille et de python, permet le déploiement et la portion de LLMS sur votre machine locale. Licencié sous HFOILV1.0, il convient à une utilisation commerciale comme outil supplémentaire. Ses principaux avantages incluent:

- Génération de texte haute performance: TGI optimise les performances en utilisant le parallélisme du tenseur et le lot dynamique pour des modèles comme Starcoder, Bloom, GPT-Neox, Llama et T5.
- Utilisation efficace des ressources: Lot continu et code optimisé minimiser la consommation de ressources tout en gérant plusieurs demandes simultanément.
- Flexibilité: Il prend en charge les fonctionnalités de sécurité et de sécurité telles que le filigrane, la déformation logit pour le contrôle des biais et les séquences d'arrêt.
TGI possède des architectures optimisées pour une exécution plus rapide de LLMS comme Llama, Falcon7b et Mistral (voir la documentation pour la liste complète).
Pourquoi choisir l'étreinte Face TGI?
Le visage étreint est un centre central pour les LLM open source. Auparavant, de nombreux modèles étaient trop à forte intensité de ressources pour un usage local, nécessitant des services cloud. Cependant, des progrès comme Qlora et GPTQ quantification ont rendu certains LLM gérables sur les machines locales.
TGI résout le problème du temps de démarrage LLM. En gardant le modèle prêt, il fournit des réponses instantanées, éliminant de longs temps d'attente. Imaginez avoir un point de terminaison facilement accessible à une gamme de modèles de langage de haut niveau.
La simplicité de TGI est remarquable. Il est conçu pour le déploiement transparent d'architectures de modèle rationalisées et alimente plusieurs projets en direct, notamment:

- Chat étreint
- openassistant
- nat.dev
Remarque importante: TGI est actuellement incompatible avec les Mac GPU basés sur ARM (M1 et plus tard).
Configuration de l'étreinte Face Tgi
Deux méthodes sont présentées: à partir de zéro et à l'aide de Docker (recommandé pour la simplicité).
Méthode 1: à partir de zéro (plus complexe)
- Installez la rouille:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh - Créez un environnement virtuel Python:
conda create -n text-generation-inference python=3.9 && conda activate text-generation-inference - Installer ProtoC (version 21.12 Recommandé): (nécessite
sudo) Instructions omises par la concision, reportez-vous au texte d'origine. - Clone Le référentiel GitHub:
git clone https://github.com/huggingface/text-generation-inference.git - Installez TGI:
cd text-generation-inference/ && BUILD_EXTENSIONS=False make install
Méthode 2: Utilisation de Docker (recommandé)
- Assurez-vous que Docker est installé et en cours d'exécution.
- (Vérifiez d'abord la compatibilité) Exécutez la commande docker (exemple en utilisant Falcon-7B):
volume=$PWD/data && sudo docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:0.9 --model-id tiiuae/falcon-7b-instruct --num-shard 1 --quantize bitsandbytesRemplacer"all"par"0"si vous utilisez un seul GPU.
en utilisant TGI dans les applications
Après avoir lancé TGI, interagissez avec lui en utilisant les demandes de poste au point final /generate (ou /stream pour le streaming). Des exemples utilisant Python et Curl sont fournis dans le texte d'origine. La bibliothèque text-generation python (pip install text-generation) simplifie l'interaction.
Conseils pratiques et apprentissage plus approfondi
- Comprendre les principes fondamentaux de LLM: Familiarisez-vous avec la tokenisation, les mécanismes d'attention et l'architecture du transformateur.
- Optimisation du modèle: Apprenez à préparer et à optimiser les modèles, notamment la sélection du bon modèle, la personnalisation des tokeniseurs et le réglage fin.
- Stratégies de génération: Explorez différentes stratégies de génération de texte (recherche gourmand, recherche de faisceau, échantillonnage supérieur).
Conclusion
Hugging Face TGI offre un moyen convivial de déployer et d'héberger les LLM localement, offrant des avantages tels que la confidentialité des données et le contrôle des coûts. Tout en nécessitant un matériel puissant, les progrès récents le rendent possible pour de nombreux utilisateurs. Une exploration plus approfondie des concepts et ressources LLM avancés (mentionnés dans le texte original) est fortement recommandé pour l'apprentissage continu.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1654
1654
 14
1413
52
1306
25
1252
29
1225
24
14
1413
52
1306
25
1252
29
1225
24

 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
Hé là, codant ninja! Quelles tâches liées au codage avez-vous prévues pour la journée? Avant de plonger plus loin dans ce blog, je veux que vous réfléchissiez à tous vos malheurs liés au codage - les énumérez. Fait? - Let & # 8217
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
La récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
 AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
Le paysage de l'IA de cette semaine: un tourbillon de progrès, de considérations éthiques et de débats réglementaires. Les principaux acteurs comme Openai, Google, Meta et Microsoft ont déclenché un torrent de mises à jour, des nouveaux modèles révolutionnaires aux changements cruciaux de LE
 GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
Introduction Openai a publié son nouveau modèle basé sur l'architecture «aux fraises» très attendue. Ce modèle innovant, connu sous le nom d'O1, améliore les capacités de raisonnement, lui permettant de réfléchir à des problèmes Mor
 Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Introduction Imaginez vous promener dans une galerie d'art, entourée de peintures et de sculptures vives. Maintenant, que se passe-t-il si vous pouviez poser une question à chaque pièce et obtenir une réponse significative? Vous pourriez demander: «Quelle histoire racontez-vous?
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Le rapport de l'indice de l'intelligence artificielle de 2025 publié par le Stanford University Institute for Human-oriented Artificial Intelligence offre un bon aperçu de la révolution de l'intelligence artificielle en cours. Interprétons-le dans quatre concepts simples: cognition (comprendre ce qui se passe), l'appréciation (voir les avantages), l'acceptation (défis face à face) et la responsabilité (trouver nos responsabilités). Cognition: l'intelligence artificielle est partout et se développe rapidement Nous devons être très conscients de la rapidité avec laquelle l'intelligence artificielle se développe et se propage. Les systèmes d'intelligence artificielle s'améliorent constamment, obtenant d'excellents résultats en mathématiques et des tests de réflexion complexes, et il y a tout juste un an, ils ont échoué lamentablement dans ces tests. Imaginez des problèmes de codage complexes de résolution de l'IA ou des problèmes scientifiques au niveau des diplômés - depuis 2023
