

Les progrès rapides de l'AI repoussent les limites des capacités de la machine, dépassant les attentes d'il y a quelques années à peine. Les grands modèles de raisonnement (LRMS, illustrés par OpenAI-O1) sont des systèmes sophistiqués s'attaquant aux problèmes complexes grâce à une approche étape par étape. Ces modèles ne résolvent pas seulement les problèmes; Ils raisonnent méthodiquement, employant un renforcement d'apprentissage à affiner leur logique et à produire des solutions détaillées et cohérentes. Ce processus délibéré, souvent appelé «pensée lente», améliore la clarté logique. Cependant, une limitation significative demeure: les lacunes de connaissances. Les LRM peuvent rencontrer des incertitudes qui propagent les erreurs, compromettant la précision finale. Les solutions traditionnelles comme l'augmentation de la taille du modèle et les ensembles de données en expansion, bien que utiles, ont des limitations, et même les méthodes de génération (RAG) de la récupération (RAG) luttent avec un raisonnement très complexe.
Search-O1, un cadre développé par des chercheurs de l'Université Renmin de Chine et de l'Université Tsinghua, aborde ces limites. Il intègre de manière transparente les instructions de tâche, les questions et les connaissances récupérées dynamiquement dans une chaîne de raisonnement cohérente, facilitant les solutions logiques. Search-O1 augmente les LRM avec un mécanisme de chiffon agentique et un module de moments de moments pour affiner les informations récupérées.
Contrairement aux modèles traditionnels qui luttent avec des connaissances incomplètes ou des méthodes de chiffon de base qui récupèrent souvent des informations excessives et non pertinentes, Search-O1 introduit un module crucial module de moments dans les documents . Ce module distille les données étendues en étapes concises et logiques, assurant la précision et la cohérence.
Le cadre fonctionne de manière itérative, de recherche dynamiquement et d'extraction de documents pertinents, de les transformer en étapes de raisonnement précises et de affiner le processus jusqu'à ce qu'une solution complète soit obtenue. Il dépasse le raisonnement traditionnel (entravé par les lacunes de connaissances) et les méthodes de chiffon de base (qui perturbent le flux de raisonnement). Grâce à un Mécanisme agentique Pour l'intégration des connaissances et le maintien de la cohérence, Search-O1 assure un raisonnement fiable et précis, établissant une nouvelle norme pour la résolution de problèmes complexes en IA.
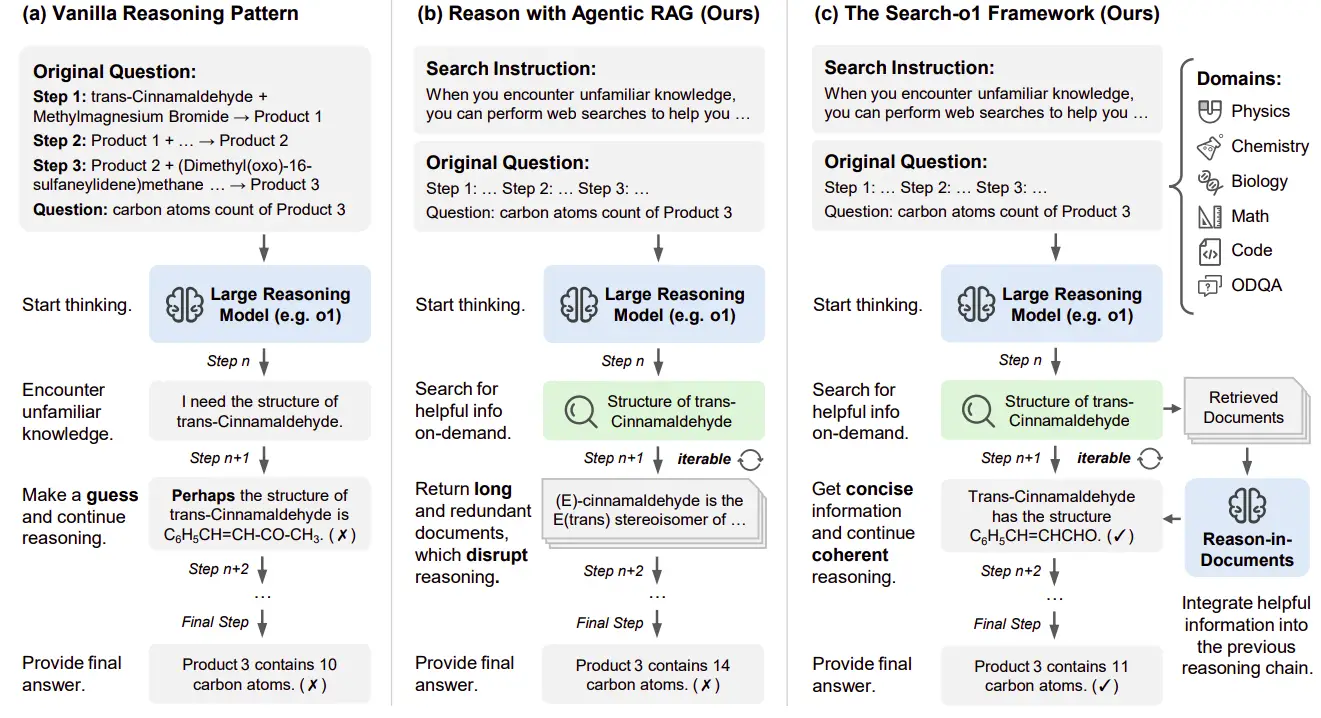
Search-O1 comble les lacunes de connaissances dans les LRM en intégrant de manière transparente la récupération des connaissances externes sans perturber le flux logique. La recherche a comparé trois approches: le raisonnement traditionnel, le chiffon agentique et le framework Search-O1.
déterminer le nombre d'atomes de carbone dans le produit final d'une réaction chimique en trois étapes en sert d'exemple. Les méthodes traditionnelles luttent lors de la rencontre des lacunes de connaissances, comme le manque de structure de trans-Cinnamaldéhyde . Sans informations précises, le modèle repose sur des hypothèses, ce qui entraîne potentiellement des erreurs.
Le chiffon agentique permet une récupération autonome des connaissances. S'il est incertain quant à la structure d'un composé, il génère des requêtes spécifiques (par exemple, "Structure de trans-Cinnamaldéhyde "). Cependant, l'incorporation directe des documents récupérés longs, souvent non pertinents, perturbe le processus de raisonnement et réduit la cohérence due à des informations verbales et tangentielles.
Search-O1 améliore le chiffon agentique avec le module de raisons de documents. Ce module affine des documents récupérés en étapes de raisonnement concises, intégrant de manière transparente les connaissances externes tout en préservant le flux logique. Compte tenu de la requête actuelle, des documents récupérés et de la chaîne de raisonnement en évolution, il génère des étapes cohérentes et interconnectées de manière itérative jusqu'à ce qu'une réponse concluante soit atteinte.
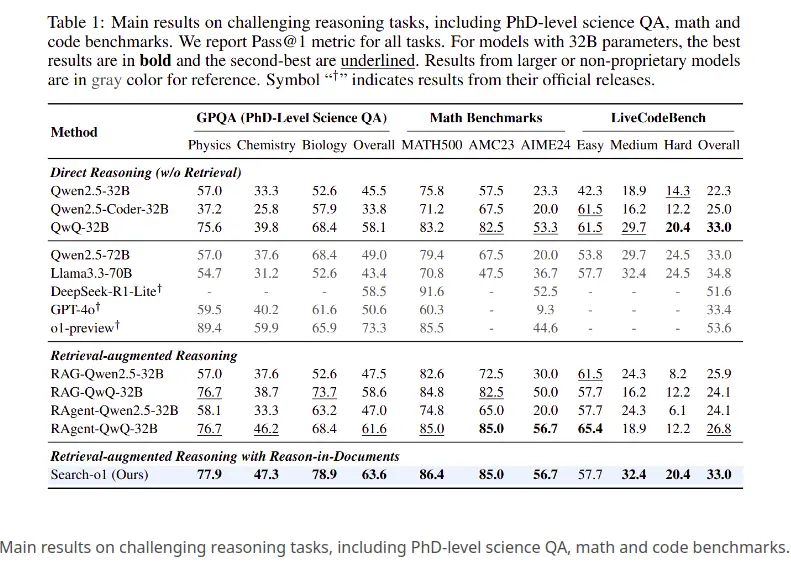
Trois tâches de raisonnement difficiles ont été évaluées:
Résultats de clés :
Étude de cas de chimie à partir de l'ensemble de données GPQA
Le modèle a conclu que le produit final contient 11 atomes de carbone (en commençant par 9, en ajoutant un de la réaction de Grignard, et un autre à l'étape finale). La réponse est 11.
Search-O1 représente une progression significative dans les LRM, abordant l'insuffisance des connaissances. En intégrant le chiffon agentique et le module de raisons en matière de documents, il permet un raisonnement itératif transparent qui intègre des connaissances externes tout en maintenant une cohérence logique. Ses performances supérieures dans divers domaines établissent une nouvelle norme pour la résolution complexe de problèmes dans l'IA. Cette innovation améliore la précision du raisonnement et ouvre des voies pour la recherche dans les systèmes de récupération, l'analyse des documents et la résolution intelligente de problèmes, combler l'écart entre la recherche de connaissances et le raisonnement logique. Search-O1 établit une base robuste pour l'avenir de l'IA, permettant des solutions plus efficaces à des défis complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 xrp Ripple Dernières nouvelles
xrp Ripple Dernières nouvelles
 méthode d'appel du service Web
méthode d'appel du service Web
 package de mise à niveau mcafee
package de mise à niveau mcafee
 Comment cracker le cryptage d'un fichier zip
Comment cracker le cryptage d'un fichier zip
 Comment ouvrir le fichier dmp
Comment ouvrir le fichier dmp
 Qu'est-ce qui fait que l'écran de l'ordinateur devient jaune ?
Qu'est-ce qui fait que l'écran de l'ordinateur devient jaune ?
 L'expression régulière ne contient pas
L'expression régulière ne contient pas
 Comment verrouiller l'écran sur oppo11
Comment verrouiller l'écran sur oppo11








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



