

Réseaux de neurones récurrents (RNN) sont un type puissant de réseau de neurones artificiels (ANN) utilisé dans des applications comme Siri et la recherche vocale de Google d'Apple et de Google. Leur capacité unique à conserver les entrées passées via la mémoire interne les rend idéales pour des tâches telles que la prédiction du cours des actions, la génération de texte, la transcription et la traduction automatique. Contrairement aux réseaux de neurones traditionnels où les entrées et les sorties sont indépendantes, les sorties RNN dépendent des éléments précédents dans une séquence. De plus, les RNN partagent les paramètres à travers les couches du réseau, l'optimisation des ajustements de poids et de biais pendant la descendance du gradient.
![Recurrent Network Tutorial (RNN) <p> Le diagramme ci-dessus illustre un RNN de base. Dans un scénario de prévision du cours de l'action utilisant des données comme [45, 56, 45, 49, 50, ...], chaque entrée (x0 à xt) intègre des valeurs passées. Par exemple, X0 serait de 45, X1 serait de 56, et ces valeurs contribueraient à prédire l'élément de séquence suivante. </p> <h2> comment les RNN fonctionnent </h2> <p> dans les RNN, les cycles d'information à travers une boucle, faisant de la sortie une fonction des entrées actuelles et précédentes. </p> <p> <Img src =](https://img.php.cn/upload/article/000/000/000/174165793495192.jpg)
La couche d'entrée (x) traite les comprestiques de l'entrée, la compréhension initiale à la couche moyenne (A), qui comprend plusieurs compressions cachées, la compréhension initiale (A) poids et biais. Ces paramètres sont partagés sur la couche cachée, créant une seule couche bouclée au lieu de plusieurs couches distinctes. Les RNN utilisent la rétropropagation à travers le temps (BPTT) au lieu de la rétro-propagation traditionnelle pour calculer les gradients. BPTT résume les erreurs à chaque étape de temps en raison des paramètres partagés.
RNN offrent une flexibilité dans les longueurs d'entrée et de sortie, contrairement aux réseaux d'alimentation avec des entrées et sorties uniques. Cette adaptabilité permet aux RNN de gérer diverses tâches, notamment la génération de musique, l'analyse des sentiments et la traduction automatique. Il existe quatre principaux types:
Networks Convolutional Networks (CNNNS) Traitement des données spatiales (comme les images), couramment utilisées dans la vision par ordinateur. Les réseaux de neurones simples luttent avec les dépendances de pixels d'image, tandis que les CNN, avec leurs couches convolutionnelles, relu, poolling et entièrement connectées, excellent dans ce domaine.
Différences de clés:
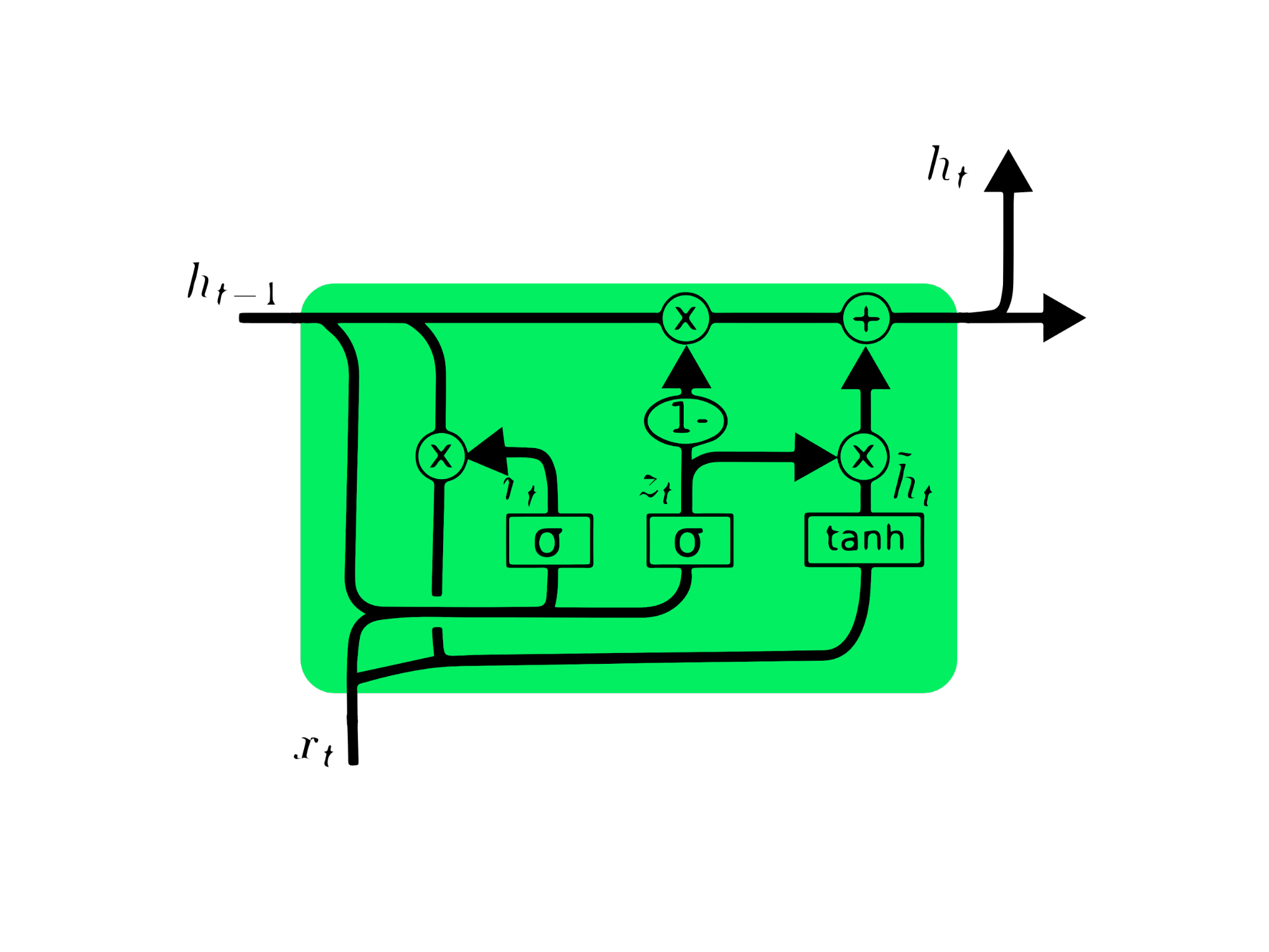
Les RNN simples sont confrontés à deux défis principaux liés aux gradients:
Les solutions incluent la réduction des couches cachées ou l'utilisation d'architectures avancées comme LSTM et GRU.
Les RNN simples souffrent de limitations de mémoire à court terme. LSTM et GRU abordent ceci en permettant la rétention d'informations sur des périodes prolongées.
 P>
P>
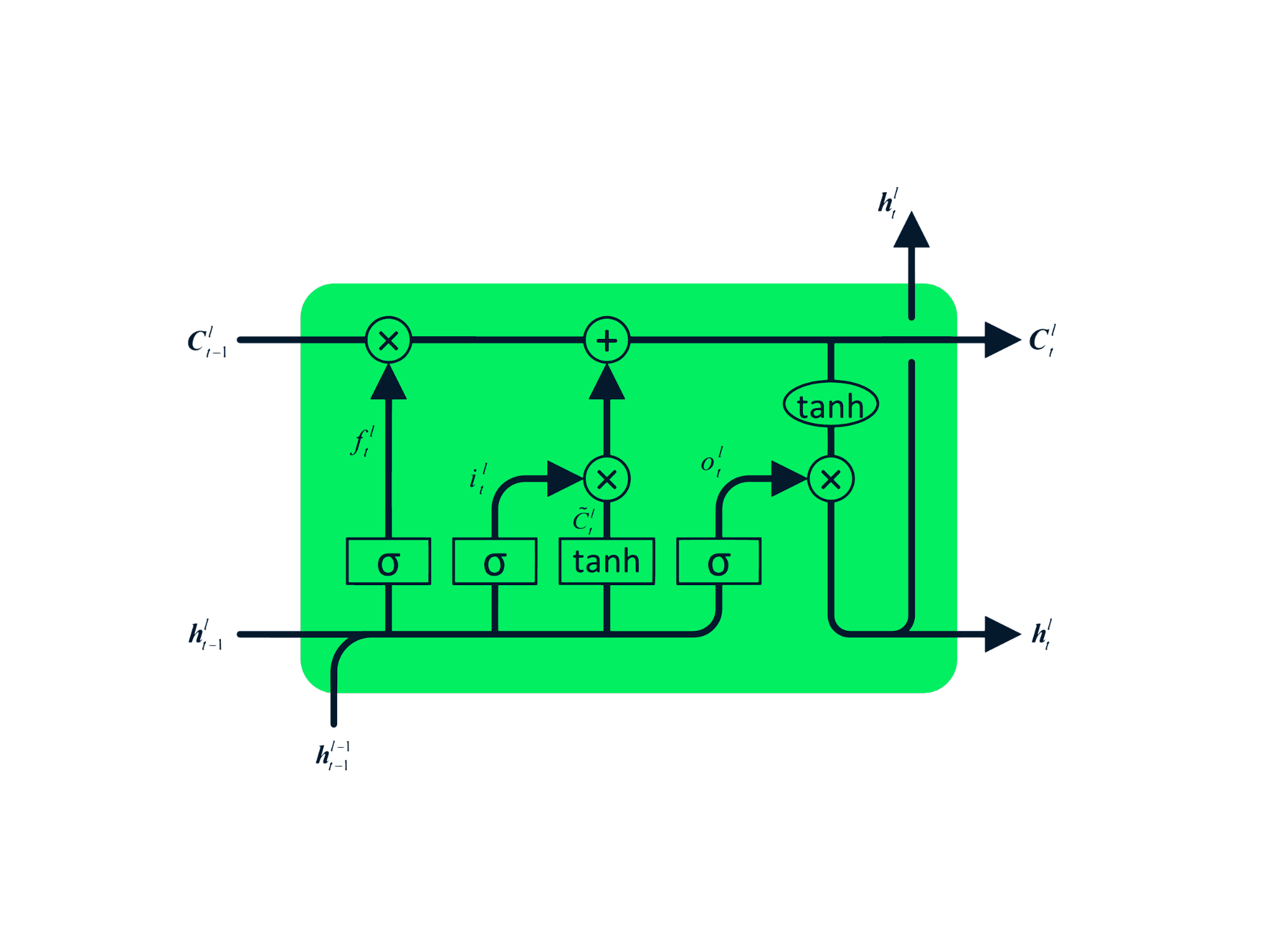
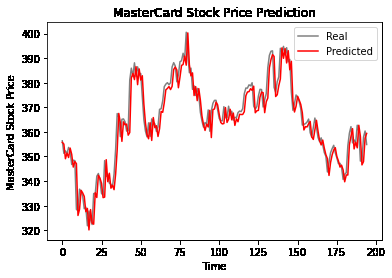
 Prédiction utilisant LSTM & amp; GRU
Prédiction utilisant LSTM & amp; GRU
Cette section détaille un projet utilisant LSTM et GRU pour prédire les cours des actions MasterCard. Le code utilise des bibliothèques comme Pandas, Numpy, Matplotlib, Scikit-Learn et Tensorflow.
(L'exemple de code détaillé de l'entrée d'origine est omis ici pour Brevity. Les étapes de base sont résumées ci-dessous. Prétraitement: Divisez les données en ensembles de formation et de test, à l'échelle de Minmaxscaler et de remodeler pour l'entrée du modèle.
N'oubliez pas de remplacer https://www.php.cn/link/cc6a6632b380f3f6a1c54b1222cd96c2 et https://www.php.cn/link/8708107b2ff5de15d0244471ae041fdb avec des liens réels vers les cours pertinents. Les URL d'image sont supposées être correctes et accessibles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction à l'utilisation de la fonction stickline
Introduction à l'utilisation de la fonction stickline
 Que fait Python ?
Que fait Python ?
 Comment utiliser l'éditeur d'atomes
Comment utiliser l'éditeur d'atomes
 Étapes WeChat
Étapes WeChat
 qu'est-ce que la programmation Python
qu'est-ce que la programmation Python
 Les performances des micro-ordinateurs dépendent principalement de
Les performances des micro-ordinateurs dépendent principalement de
 Quel échange est EDX ?
Quel échange est EDX ?
 Quelles sont les commandes de nettoyage de disque ?
Quelles sont les commandes de nettoyage de disque ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



