

Benchmarks du processeur en profondeur

Les repères GPU en deep Learning ont révolutionné la façon dont nous résolvons des problèmes complexes, de la reconnaissance d'image au traitement du langage naturel. Cependant, alors que la formation de ces modèles s'appuie souvent sur des GPU haute performance, les déploier efficacement dans des environnements liés aux ressources tels que les appareils Edge ou les systèmes avec du matériel limité présente des défis uniques. Les CPU, étant largement disponibles et rentables, servent souvent de squelette pour l'inférence dans de tels scénarios. Mais comment pouvons-nous nous assurer que les modèles déployés sur des processeurs offrent des performances optimales sans compromettre la précision?
Cet article plonge dans la comparaison de l'inférence du modèle d'apprentissage en profondeur sur les processeurs, en se concentrant sur trois mesures critiques: latence, l'utilisation du processeur et l'utilisation de la mémoire. En utilisant un exemple de classification des spam, nous explorons comment les cadres populaires comme Pytorch, Tensorflow, Jax et ONNX Runtime gèrent les charges de travail d'inférence. À la fin, vous aurez une compréhension claire de la façon de mesurer les performances, d'optimiser les déploiements et de sélectionner les bons outils et cadres pour l'inférence basée sur le processeur dans des environnements limités aux ressources.
Impact: L'exécution optimale de l'inférence peut économiser une somme d'argent importante et libérer des ressources pour d'autres charges de travail.
Objectifs d'apprentissage
- Comprendre le rôle des repères du processeur en profondeur dans l'évaluation des performances matérielles pour la formation et l'inférence du modèle d'IA.
- Évaluez Pytorch, TensorFlow, Jax, ONNX Runtime et OpenVino Runtime pour choisir le meilleur pour vos besoins.
- Des outils maîtres comme PSUtil et du temps pour collecter des données de performances précises et optimiser l'inférence.
- Préparer des modèles, exécuter l'inférence et mesurer les performances, en appliquant des techniques à diverses tâches comme la classification des images et la PNL.
- Identifier les goulots d'étranglement, optimiser les modèles et améliorer les performances tout en gérant efficacement les ressources.
Cet article a été publié dans le cadre du Blogathon de la science des données.
Table des matières
- Optimisation de l'inférence avec l'accélération d'exécution
- Modèles de performances d'inférence
- Hypothèses et limitations
- Outils et cadres
- Installer des dépendances
- Énoncé du problème et spécification d'entrée
- Modèles d'architecture et de formats
- Exemples de réseaux supplémentaires pour l'analyse comparative
- Benchmarking Workflow
- Fonction d'analyse comparative définiton
- Modèle d'inférence et effectuer une analyse comparative pour chaque cadre
- Résultats et discussion
- Conclusion
- Questions fréquemment posées
Optimisation de l'inférence avec l'accélération d'exécution
La vitesse d'inférence est essentielle pour l'expérience utilisateur et l'efficacité opérationnelle dans les applications d'apprentissage automatique. L'optimisation d'exécution joue un rôle clé dans l'amélioration de cela en rationalisant l'exécution. L'utilisation de bibliothèques accélérées par le matériel comme l'ONNX Runtime tire parti des optimisations adaptées à des architectures spécifiques, réduisant la latence (temps par inférence).
De plus, des formats de modèle léger tels que ONNX minimisent les frais généraux, permettant une charge et une exécution plus rapides. Optimisé les temps d'exécution exploitent le traitement parallèle pour distribuer le calcul sur les cœurs de processeur disponibles et améliorer la gestion de la mémoire, garantissant de meilleures performances, en particulier sur les systèmes avec des ressources limitées. Cette approche rend les modèles plus rapides et plus efficaces tout en maintenant la précision.
Modèles de performances d'inférence
Pour évaluer les performances de nos modèles, nous nous concentrons sur trois métriques clés:
Latence
- Définition: la latence fait référence au temps nécessaire au modèle pour faire une prédiction après avoir reçu l'entrée. Ceci est souvent mesuré comme le temps passé de l'envoi des données d'entrée à la réception de la sortie (prédiction)
- Importance : Dans les applications en temps réel ou en temps presque réel, une latence élevée entraîne des retards, ce qui peut entraîner des réponses plus lentes.
- Mesure : la latence est généralement mesurée en millisecondes (MS) ou secondes (s). La latence plus courte signifie que le système est plus réactif et efficace, crucial pour les applications nécessitant une prise de décision ou des actions immédiates.
Utilisation du processeur
- Définition : L'utilisation du processeur est le pourcentage de la puissance de traitement du CPU qui est consommée lors de l'exécution des tâches d'inférence. Il vous indique la quantité de ressources de calcul du système utilisées pendant l'inférence du modèle.
- Importance : Utilisation élevée du processeur signifie que la machine pourrait avoir du mal à gérer d'autres tâches simultanément, conduisant à des goulots d'étranglement. L'utilisation efficace des ressources CPU garantit que l'inférence du modèle ne monopolise pas les ressources du système.
- Mesure t: Il est généralement mesuré en pourcentage (%) du total des ressources CPU disponibles. Une utilisation plus faible pour la même charge de travail indique généralement un modèle plus optimisé, en utilisant plus efficacement les ressources CPU.
Utilisation de la mémoire
- Définition: L'utilisation de la mémoire fait référence à la quantité de RAM utilisée par le modèle pendant le processus d'inférence. Il suit la consommation de mémoire par les paramètres du modèle, les calculs intermédiaires et les données d'entrée.
- Importance: L'optimisation de l'utilisation de la mémoire est particulièrement critique lors du déploiement de modèles sur des appareils ou des systèmes à bord de la mémoire limitée. Une consommation élevée de mémoire pourrait conduire à une mémoire surfloe, un traitement plus lent ou des accidents du système.
- Mesure: l'utilisation de la mémoire est mesurée dans les mégaoctets (MB) ou les gigaoctets (GB). Le suivi de la consommation de mémoire à différents stades de l'inférence peut aider à identifier les inefficacités de mémoire ou les fuites de mémoire.
Hypothèses et limitations
Pour maintenir cette étude d'analyse comparative ciblée et pratique, nous avons fait les hypothèses suivantes et fixé quelques limites:
- Contraintes matérielles : les tests sont conçus pour fonctionner sur une seule machine avec des cœurs CPU limités. Alors que le matériel moderne est capable de gérer les charges de travail parallèles, cette configuration reflète les contraintes souvent observées dans les périphériques Edge ou les déploiements à petite échelle.
- Pas de parallélisation multi-systèmes : nous n'avons pas incorporé des configurations informatiques distribuées ou des solutions basées sur des cluster. Les repères reflètent les conditions autonomes des performances, adaptées aux environnements à nœud unique avec des noyaux et une mémoire CPU limités.
- Portée : L'objectif principal est uniquement sur les performances d'inférence du CPU. Bien que l'inférence basée sur le GPU soit une excellente option pour les tâches à forte intensité de ressources, cette analyse comparative vise à fournir des informations sur les configurations CPU uniquement, qui sont plus courantes dans les applications de coûts ou portables.
Ces hypothèses garantissent que les repères restent pertinents pour les développeurs et les équipes travaillant avec du matériel limité aux ressources ou qui ont besoin de performances prévisibles sans la complexité supplémentaire des systèmes distribués.
Outils et cadres
Nous explorerons les outils et les cadres essentiels utilisés pour comparer et optimiser l'inférence du modèle d'apprentissage en profondeur sur les processeurs, fournissant des informations sur leurs capacités d'exécution efficace dans des environnements limités aux ressources.
Outils de profilage
- Python Time (Time Library) : La bibliothèque Time dans Python est un outil léger pour mesurer le temps d'exécution des blocs de code. En enregistrant les horodatages de début et de fin, il aide à calculer le temps pris pour les opérations comme l'inférence du modèle ou le traitement des données.
- PSUTIL (CPU, profilage de mémoire) : PSUTI L est une bibliothèque Python pour la surveillance et le profilage SUTISM. Il fournit des données en temps réel sur l'utilisation du processeur, la consommation de mémoire, les E / S de disque et plus, ce qui le rend idéal pour l'analyse de l'utilisation pendant la formation ou l'inférence du modèle.
Cadres d'inférence
- Tensorflow : un cadre robuste pour l'apprentissage en profondeur qui est largement utilisé pour les tâches de formation et d'inférence. Il offre un fort soutien à divers modèles et stratégies de déploiement.
- Pytorch: Connu pour sa facilité d'utilisation et ses graphiques de calcul dynamiques, Pytorch est un choix populaire pour le déploiement de la recherche et de la production.
- ONNX Runtime : un moteur Open-source et multiplateforme pour exécuter les modèles ONXX (Open Neural Network Exchange), offrant une inférence efficace sur divers matériel et frameworks.
- JAX : Un cadre fonctionnel s'est concentré sur l'informatique numérique haute performance et l'apprentissage automatique, offrant une différenciation automatique et une accélération GPU / TPU.
- OpenVino: Optimisé pour Intel Hardware, OpenVino fournit des outils pour l'optimisation et le déploiement du modèle sur les CPU Intel, les GPU et les VPU.
Spécification matérielle et environnement
Nous utilisons GitHub Codespace (machine virtuelle) avec la configuration ci-dessous:
- Spécification de la machine virtuelle: 2 cœurs, 8 Go de RAM et 32 Go de stockage
- Version Python: 3.12.1
Installer des dépendances
Les versions des packages utilisés sont les suivants et cette primaire comprend cinq bibliothèques d'inférence d'apprentissage en profondeur: TensorFlow, Pytorch, ONNX Runtime, Jax et OpenVino:
! pip install numpy == 1.26.4 ! pip install torch == 2.2.2 ! pip install tensorflow == 2.16.2 ! PIP Installer Onnx == 1.17.0 ! PIP Install onnxruntime == 1.17.0! PIP Installer Jax == 0.4.30 ! Pip installer jaxlib == 0.4.30 ! PIP Installer OpenVino == 2024.6.0 ! PIP installer matplotlib == 3.9.3 ! PIP Installer Matplotlib: 3.4.3 ! Pip Installer Oreiller: 8.3.2 ! PIP Installer PSUtil: 5.8.0
Énoncé du problème et spécification d'entrée
Étant donné que l'inférence du modèle consiste à effectuer quelques opérations matricielles entre les poids du réseau et les données d'entrée, il ne nécessite pas de formation de modèle ou de jeux de données. Pour notre exemple le processus d'analyse comparative, nous avons simulé un cas d'utilisation de classification standard. Cela simule les tâches de classification binaire communes comme la détection de spam et les décisions de demande de prêt (approbation ou refus). La nature binaire de ces problèmes les rend idéaux pour comparer les performances du modèle dans différents cadres. Cette configuration reflète les systèmes du monde réel mais nous permet de nous concentrer sur les performances d'inférence entre les cadres sans avoir besoin de grands ensembles de données ou de modèles pré-formés.
Déclaration de problème
La tâche de l'échantillon consiste à prédire si un échantillon donné est un spam ou non (approbation du prêt ou déni), sur la base d'un ensemble de fonctionnalités d'entrée. Ce problème de classification binaire est efficace sur le calcul, permettant une analyse ciblée des performances d'inférence sans la complexité des tâches de classification multi-classes.
Spécification d'entrée
Pour simuler les données d'e-mail du monde réel, nous avons généré une entrée au hasard. Ces intérêts imitent le type de données qui pourraient être traitées par des filtres de spam mais évitent la nécessité d'éseils de données externes. Ces données d'entrée simulées permettent une analyse comparative sans compter sur des ensembles de données externes spécifiques, ce qui le rend idéal pour tester les temps d'inférence du modèle, l'utilisation de la mémoire et les performances du CPU. Alternativement, vous pouvez utiliser la classification d'images, la tâche NLP ou toute autre tâche d'apprentissage en profondeur pour effectuer ce processus d'analyse comparative.
Modèles d'architecture et de formats
La sélection du modèle est une étape critique dans l'analyse comparative car elle influence directement les performances et les idées d'inférence obtenus du processus de profilage. Comme mentionné dans la section précédente, pour cette étude d'analyse comparative, nous avons choisi un cas d'utilisation de classification standard, qui implique d'identifier si un e-mail donné est un spam ou non. Cette tâche est un problème de classification à deux classes simple qui est efficace sur le calcul mais fournit des résultats significatifs pour la comparaison entre les cadres.
Architecture de modèles pour l'analyse comparative
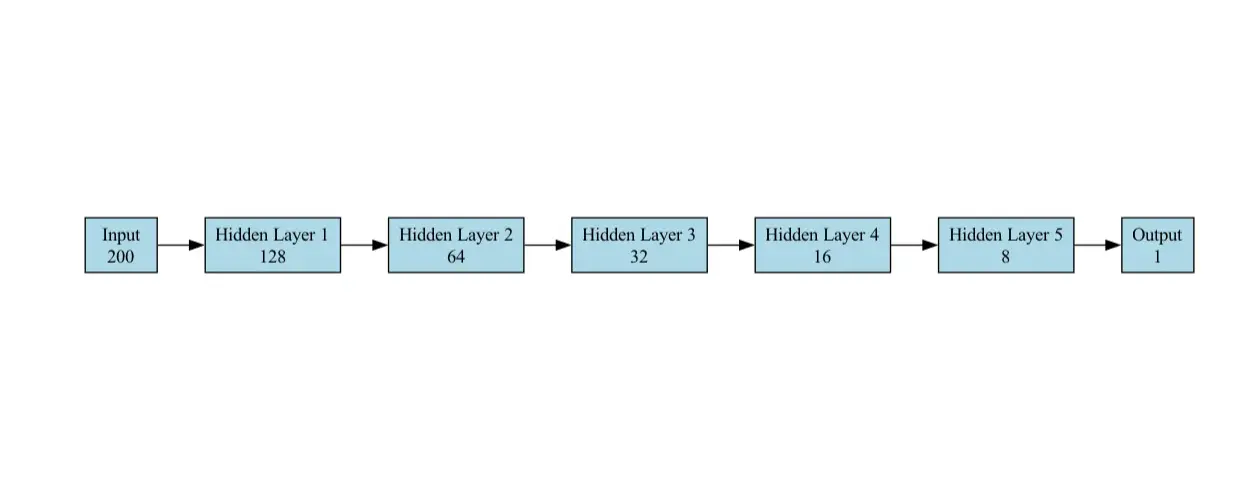
Le modèle de la tâche de classification est un réseau neuronal à action directe (FNN) conçu pour la classification binaire (spam vs non spam). Il se compose des couches suivantes:
- Couche d'entrée : accepte un vecteur de taille 200 (caractéristiques d'intégration). Nous avons fourni un exemple de pytorch, d'autres frameworks suivent exactement la même configuration réseau
self.fc1 = torch.nn.linear (200,128)
- Couches cachées : le réseau a 5 couches cachées, chaque couche successive contenant moins d'unités que la précédente.
self.fc2 = torch.nn.linear (128, 64) self.fc3 = torch.nn.linear (64, 32) self.fc4 = torch.nn.linear (32, 16) self.fc5 = torch.nn.linear (16, 8) self.fc6 = torch.nn.linear (8, 1)
- Couches de sortie : un seul neurone avec une fonction d'activation sigmoïde pour produire une probabilité (0 pour non spam, 1 pour le spam). Nous avons utilisé la couche sigmoïde comme sortie finale pour la classification binaire.
self.sigmoïd = torch.nn.sigmoïd ()
Le modèle est simple mais efficace pour la tâche de classification.
Le diagramme d'architecture du modèle utilisé pour l'analyse comparative dans notre cas d'utilisation est illustré ci-dessous:
Exemples de réseaux supplémentaires pour l'analyse comparative
- Classification d'image: des modèles comme RESNET-50 (complexité moyenne) et MobileNet (léger) peuvent être ajoutés à la suite de référence pour les tâches impliquant la reconnaissance d'image. RESNET-50 offre un équilibre entre la complexité de calcul et la précision, tandis que MobileNet est optimisé pour les environnements à faible ressource.
- Tâches NLP: Distilbert : une variante plus petite et plus rapide du modèle Bert, adapté aux tâches de compréhension du langage naturel.
Formats de modèle
- Formats natifs: chaque cadre prend en charge ses formats de modèle natifs, tels que .pt pour pytorch et .h5 pour TensorFlow.
- Format unifié (ONNX) : Pour assurer la compatibilité entre les cadres, nous avons exporté le modèle Pytorch au format ONNX (Model.onnx). ONNX (Open Neural Network Exchange) agit comme un pont, permettant à des modèles d'être utilisés dans d'autres cadres comme Pytorch, Tensorflow, Jax ou OpenVino sans modifications significatives. Ceci est particulièrement utile pour les tests multi-trames et les scénarios de déploiement du monde réel, où l'interopérabilité est critique.
- Ces formats sont optimisés pour leurs cadres respectifs, ce qui les rend faciles à enregistrer, à charger et à déployer dans ces écosystèmes.
Benchmarking Workflow
Ce flux de travail vise à comparer les performances d'inférence de plusieurs cadres d'apprentissage en profondeur (TensorFlow, Pytorch, Onnx, Jax et OpenVino) à l'aide de la tâche de classification. La tâche consiste à utiliser des données d'entrée générées de manière aléatoire et à analyser chaque cadre pour mesurer le temps moyen pris pour une prédiction.
- Importer des packages Python
- Désactiver l'utilisation du GPU et supprimer la journalisation de TensorFlow
- Préparation des données d'entrée
- Implémentations du modèle pour chaque cadre
- Définition de la fonction d'analyse comparative
- Modèle d'inférence et d'exécution d'analyse comparative pour chaque cadre
- Visualisation et exportation des résultats d'analyse comparative
Importer des packages Python nécessaires
Pour commencer avec les modèles d'apprentissage en profondeur, nous devons d'abord importer les packages Python essentiels qui permettent l'intégration transparente et l'évaluation des performances.
heure d'importation Importer un système d'exploitation Importer Numpy comme NP Importer une torche Importer TensorFlow comme TF à partir de Tensorflow.keras Importation importer onnxruntime comme ort Importer Matplotlib.pyplot en tant que plt à partir de l'image d'importation PIL Importer Putil Importer Jax importer jax.numpy en tant que JNP De OpenVino.Runtime Import Core Importer CSV
Désactiver l'utilisation du GPU et supprimer la journalisation de TensorFlow
os.environ ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU os.environ ["tf_cpp_min_log_level"] = "3" #Suppress TensorFlow Journal
Préparation des données d'entrée
Dans cette étape, nous générons des données d'entrée au hasard pour la classification des spams:
- Dimensionnalité d'un échantillon (caractéristiques de 200 dimesnionales)
- Le nombre de classes (2: spam ou non spam)
Nous générons des données Randome à l'aide de Numpy pour servir de fonctionnalités d'entrée pour les modèles.
# GENERETER DONNÉES MANDIQUES input_data = np.random.rand (1000, 200) .astype (np.float32)
Définition du modèle
Dans cette étape, nous définissons l'architecture NetWrok ou configurons le modèle à partir de chaque cadre d'apprentissage en profondeur (Tensorflow, Pytorch, ONNX, Jax et OpenVino). Chaque cadre nécessite des méthodes spécifiques pour charger des modèles et les configurer pour l'inférence.
- Modèle Pytorch : Dans Pytorch, nous définissons une simple architecture de réseau neuronal simple avec cinq couches entièrement connectées.
- Modèle TensorFlow: Le modèle TensorFlow est défini à l'aide de l'API KERAS et se compose d'un réseau neuronal simple pour la tâche de classification.
- Modèle JAX: Le modèle est initialisé avec les paramètres, et la fonction de prédiction est compilée à l'aide de la compilation JAX juste en temps (JIT) pour une exécution efficace.
- Modèle ONNX: Pour ONNX, nous exportons un modèle de Pytorch. Après avoir exporté au format ONNX, nous chargeons le modèle en utilisant le onnxruntime. API des déductions. Cela nous permet d'exécuter l'inférence sur le modèle sur différentes spécifications matérielles.
- Modèle OpenVino : OpenVino est utilisé pour exécuter des modèles optimisés et de déploiement, en particulier ceux formés à l'aide d'autres cadres (comme Pytorch ou TensorFlow). Nous chargeons le modèle ONNX et le compilons avec l'exécution d'OpenVino.
Pytorch
classe pytorchmodel (torch.nn.module):
def __init __ (soi):
super (pytorchmodel, self) .__ init __ ()
self.fc1 = torch.nn.linear (200, 128)
self.fc2 = torch.nn.linear (128, 64)
self.fc3 = torch.nn.linear (64, 32)
self.fc4 = torch.nn.linear (32, 16)
self.fc5 = torch.nn.linear (16, 8)
self.fc6 = torch.nn.linear (8, 1)
self.sigmoïd = torch.nn.sigmoïd ()
Def en avant (self, x):
x = torch.relu (self.fc1 (x))
x = torch.relu (self.fc2 (x))
x = torch.relu (self.fc3 (x))
x = torch.relu (self.fc4 (x))
x = torch.relu (self.fc5 (x))
x = self.sigmoïd (self.fc6 (x))
retour x
# Créer un modèle Pytorch
pytorch_model = pytorchmodel ()Tensorflow
Tensorflow_model = tf.keras.Sesedentiel ([
Entrée (forme = (200,)),
tf.keras.layers.dense (128, activation = 'relu'),
tf.keras.layers.dense (64, activation = 'relu'),
tf.keras.layers.dense (32, activation = 'relu'),
tf.keras.layers.dense (16, activation = 'relu'),
tf.keras.layers.dense (8, activation = 'relu'),
tf.keras.layers.dense (1, activation = 'sigmoïd')
])
Tensorflow_Model.Compile ()Jax
def jax_model (x):
x = jax.nn.relu (jnp.dot (x, jnp.ones ((200, 128)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((128, 64)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((64, 32)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((32, 16)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((16, 8)))))
x = jax.nn.sigmoïd (jnp.dot (x, jnp.ones ((8, 1)))))
retour xOnnx
# Convertir le modèle pytorch en onnx
dummy_input = torch.randn (1, 200)
onnx_model_path = "modèle.onnx"
torch.onnx.export (
pytorch_model,
dummy_input,
onnx_model_path,
export_params = true,
opset_version = 11,
input_names = ['input'],
Output_Names = ['Output'],
dynamic_axes = {'input': {0: 'batch_size'}, 'out': {0: 'batch_size'}}
)
onnx_Session = Ort.InferencesSession (onnx_model_path)Openvino
# Définition du modèle OpenVino Core = Core () openVino_Model = core.read_model (modèle = "modèle.onnx") compilé_model = core.compile_model (openvino_model, device_name = "cpu")
Fonction d'analyse comparative définiton
Cette fonction exécute des tests d'analyse comparative sur différents cadres en prenant trois arguments: Predict_function, Input_data et num_runs. Par défaut, il exécute 1 000 fois mais il peut être augmenté selon les exigences.
def benchmark_model (Predict_function, input_data, num_runs = 1000):
start_time = time.time ()
process = pUtil.process (os.getpid ())
cpu_usage = []
Memory_Usage = []
pour _ dans la plage (num_runs):
Predict_function (Input_data)
cpu_usage.append (process.cpu_percent ())
mémoire_usage.append (process.memory_info (). rss)
end_time = time.time ()
avg_latency = (end_time - start_time) / num_runs
avg_cpu = np.mean (cpu_usage)
avg_memory = np.mean (mémoire_usage) / (1024 * 1024) # converti en MB
retourner avg_latency, avg_cpu, avg_memoryModèle d'inférence et effectuer une analyse comparative pour chaque cadre
Maintenant que nous avons chargé les modèles, il est temps de comparer les performances de chaque cadre. Le processus d'analyse comparative effectue une inférence sur les données d'entrée générées.
Pytorch
# Modèle de pytorch de référence
def pytorch_predict (input_data):
pytorch_model (torch.tensor (input_data))
pytorch_latency, pytorch_cpu, pytorch_memory = benchmark_model (lambda x: pytorch_predict (x), input_data)Tensorflow
# Modèle de TensorFlow de référence
def Tensorflow_Predict (Input_data):
TensorFlow_Model (Input_data)
TENSORFLOW_LATENCY, TENSORFLOW_CPU, TENSORFLOW_MEMORY = BENCHMARK_MODEL (Lambda X: Tensorflow_Predict (x), Input_data)Jax
# Benchmark Jax modèle
def jax_predict (input_data):
jax_model (jnp.array (input_data))
jax_latency, jax_cpu, jax_memory = benchmark_model (lambda x: jax_predict (x), input_data)Onnx
# Benchmark ONNX Modèle
def onnx_predict (input_data):
# Processus des entrées par lots
pour i dans la plage (input_data.shape [0]):
single_input = input_data [i: i 1] # Extraire une entrée unique
onnx_session.run (aucun, {onnx_session.get_inputs () [0] .name: single_input})
onnx_latency, onnx_cpu, onnx_memory = benchmark_model (lambda x: onnx_predict (x), input_data)Openvino
# Modèle OpenVino Benchmark
def openVino_Predict (input_data):
# Processus des entrées par lots
pour i dans la plage (input_data.shape [0]):
single_input = input_data [i: i 1] # Extraire une entrée unique
compilé_model.infer_new_request ({0: single_input})
OpenVino_Latency, OpenVino_CPU, OpenVino_Memory = Benchmark_Model (Lambda X: OpenVino_Predict (x), Input_data)
Résultats et discussion
Ici, nous discutons des résultats de l'analyse comparative des performances des cadres d'apprentissage en profondeur mentionnés précédemment. Nous les comparons sur - latence, l'utilisation du processeur et l'utilisation de la mémoire. Nous avons inclus des données tabulaires et un tracé pour une comparaison rapide.
Comparaison de latence
| Cadre | Latence (MS) | Latence relative (contre Pytorch) |
| Pytorch | 1.26 | 1.0 (ligne de base) |
| Tensorflow | 6.61 | ~ 5,25 × |
| Jax | 3.15 | ~ 2,50 × |
| Onnx | 14.75 | ~ 11,72 × |
| Openvino | 144.84 | ~ 115 × |
Connaissances:
- Pytorch mène le cadre le plus rapide avec une latence ~ 1,26 ms .
- Tensorflow a une latence de ~ 6,61 ms , environ 5,25 × temps de Pytorch.
- Jax se trouve entre Pytorch et Tensorflow dans la latence absolue.
- Onnx est également relativement lent, à ~ 14,75 ms .
- OpenVino est le plus lent de cette expérience, à ~ 145 ms (115 × plus lent que le pytorch).
Utilisation du processeur
| Cadre | Utilisation du processeur (%) | Utilisation relative du processeur 1 |
| Pytorch | 99,79 | ~ 1,00 |
| Tensorflow | 112.26 | ~ 1.13 |
| Jax | 130.03 | ~ 1.31 |
| Onnx | 99,58 | ~ 1,00 |
| Openvino | 99.32 | 1,00 (ligne de base) |
Connaissances:
- Jax utilise le CPU le plus ( ~ 130% ), ~ 31% plus élevé qu'OpenVino.
- TensorFlow est à ~ 112% , plus que Pytorch / onnx / OpenVino mais toujours inférieur à Jax.
- Pytorch, ONNX et OpenVino ont tous, ~ 99-100% d'utilisation du processeur.
Utilisation de la mémoire
| Cadre | Mémoire (MB) | Utilisation relative de la mémoire (vs Pytorch) |
| Pytorch | ~ 959,69 | 1.0 (ligne de base) |
| Tensorflow | ~ 969.72 | ~ 1,01 × |
| Jax | ~ 1033.63 | ~ 1,08 × |
| Onnx | ~ 1033,82 | ~ 1,08 × |
| Openvino | ~ 1040.80 | ~ 1,08–1,09 × |
Connaissances:
- Pytorch et Tensorflow ont une utilisation similaire de la mémoire autour de ~ 960-970 Mo
- Jax, Onnx et OpenVino utilisent environ 1 030–1 040 Mo de mémoire, soit environ 8 à 9% de plus que Pytorch.
Voici l'intrigue comparant les performances des frameworks d'apprentissage en profondeur:

Conclusion
Dans cet article, nous avons présenté un flux de travail complexe pour évaluer les performances d'inférence de grands cadres d'apprentissage en profondeur - Tensorflow, Pytorch, ONNX, Jax et OpenVino - en utilisant une tâche de classification de spam comme référence. En analysant les mesures clés telles que la latence, l'utilisation du processeur et la consommation de mémoire, les résultats ont mis en évidence les compromis entre les cadres et leur pertinence pour différents scénarios de déploiement.
Pytorch a démontré les performances les plus équilibrées, excellant dans une faible latence et une utilisation efficace de la mémoire, ce qui le rend idéal pour des applications sensibles à la latence comme les prédictions et les systèmes de recommandation en temps réel. TensorFlow a fourni une solution du sol moyen avec une consommation de ressources modérément plus élevée. Jax a présenté un débit de calcul élevé, mais au prix de l'augmentation de l'utilisation du processeur, ce qui pourrait être un facteur limitant pour les environnements limités aux ressources. Pendant ce temps, ONNX et OpenVino ont pris du retard de latence, les performances d'OpenVino sont particulièrement entravées par l'absence d'accélération matérielle.
Ces résultats soulignent l'importance d'aligner la sélection du cadre avec les besoins de déploiement. Que l'optimisation de la vitesse, de l'efficacité des ressources ou du matériel spécifique de comprendre les compromis est essentiel pour un déploiement de modèle efficace dans des environnements réels.
Principaux à retenir
- Les repères du processeur en profondeur fournissent des informations critiques sur les performances du processeur, en aidant à sélectionner un matériel optimal pour les tâches d'IA.
- Tirer parti des références processeurs en profondeur assure une formation et une inférence efficaces en identifiant les processeurs hautement performants.
- A réalisé la meilleure latence (1,26 ms) et maintenu une utilisation efficace de la mémoire, idéale pour les applications en temps réel et limitées en ressources.
- Latence équilibrée (6,61 ms) avec une utilisation légèrement plus élevée du processeur, adaptée aux tâches nécessitant des compromis de performance modérés.
- Livré une latence concurrentielle (3,15 ms) mais au prix de l'utilisation excessive du processeur ( 130% ), limitant son utilité dans des configurations contraints.
- A montré une latence plus élevée (14,75 ms), mais son support multiplateforme le rend flexible pour les déploiements multi-cadres.
Questions fréquemment posées
Q1. Pourquoi Pytorch est-il préféré pour les applications en temps réel?A. Le graphique de calcul dynamique de Pytorch et le pipeline d'exécution efficace permettent une inférence à faible latence (1,26 ms), ce qui le rend bien adapté à des applications telles que les systèmes de recommandation et les prédictions en temps réel.
Q2. Qu'est-ce qui a affecté les performances d'OpenVino dans cette étude?A. Les optimisations d'OpenVino sont conçues pour le matériel Intel. Sans cette accélération, sa latence (144,84 ms) et l'utilisation de la mémoire (1040,8 Mo) étaient moins compétitives par rapport à d'autres cadres.
Q3. Comment choisir un cadre pour les environnements liés aux ressources?A. Pour les configurations CPU uniquement, Pytorch est le plus efficace. TensorFlow est une alternative forte pour les charges de travail modérées. Évitez les cadres comme JAX à moins que l'utilisation plus élevée du processeur soit acceptable.
Q4. Quel rôle le matériel joue-t-il dans les performances du framework?A. Les performances du cadre dépend fortement de la compatibilité matérielle. Par exemple, OpenVino excelle sur les CPU Intel avec des optimisations spécifiques au matériel, tandis que Pytorch et TensorFlow fonctionnent de manière cohérente sur des configurations variées.
Q5. Les résultats d'analyse comparative peuvent-ils diffuser avec des modèles ou des tâches complexes?A. Oui, ces résultats reflètent une simple tâche de classification binaire. Les performances pourraient varier avec des architectures complexes comme Resnet ou des tâches comme la NLP ou d'autres, où ces cadres peuvent tirer parti d'optimisations spécialisées.
Les médias présentés dans cet article ne sont pas détenus par l'analytique vidhya et sont utilisés à la discrétion de l'auteur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1653
1653
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
Hé là, codant ninja! Quelles tâches liées au codage avez-vous prévues pour la journée? Avant de plonger plus loin dans ce blog, je veux que vous réfléchissiez à tous vos malheurs liés au codage - les énumérez. Fait? - Let & # 8217
 AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
Le paysage de l'IA de cette semaine: un tourbillon de progrès, de considérations éthiques et de débats réglementaires. Les principaux acteurs comme Openai, Google, Meta et Microsoft ont déclenché un torrent de mises à jour, des nouveaux modèles révolutionnaires aux changements cruciaux de LE
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
La récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
 GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
GPT-4O VS OpenAI O1: Le nouveau modèle Openai vaut-il le battage médiatique?
Apr 13, 2025 am 10:18 AM
Introduction Openai a publié son nouveau modèle basé sur l'architecture «aux fraises» très attendue. Ce modèle innovant, connu sous le nom d'O1, améliore les capacités de raisonnement, lui permettant de réfléchir à des problèmes Mor
 Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Un guide complet des modèles de langue de vision (VLMS)
Apr 12, 2025 am 11:58 AM
Introduction Imaginez vous promener dans une galerie d'art, entourée de peintures et de sculptures vives. Maintenant, que se passe-t-il si vous pouviez poser une question à chaque pièce et obtenir une réponse significative? Vous pourriez demander: «Quelle histoire racontez-vous?
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Lire l'index de l'IA 2025: L'AI est-elle votre ami, ennemi ou copilote?
Apr 11, 2025 pm 12:13 PM
Le rapport de l'indice de l'intelligence artificielle de 2025 publié par le Stanford University Institute for Human-oriented Artificial Intelligence offre un bon aperçu de la révolution de l'intelligence artificielle en cours. Interprétons-le dans quatre concepts simples: cognition (comprendre ce qui se passe), l'appréciation (voir les avantages), l'acceptation (défis face à face) et la responsabilité (trouver nos responsabilités). Cognition: l'intelligence artificielle est partout et se développe rapidement Nous devons être très conscients de la rapidité avec laquelle l'intelligence artificielle se développe et se propage. Les systèmes d'intelligence artificielle s'améliorent constamment, obtenant d'excellents résultats en mathématiques et des tests de réflexion complexes, et il y a tout juste un an, ils ont échoué lamentablement dans ces tests. Imaginez des problèmes de codage complexes de résolution de l'IA ou des problèmes scientifiques au niveau des diplômés - depuis 2023
