

Évaluation des performances des modèles de petits langues

Cet article explore les avantages des modèles de petits langues (SLM) sur leurs homologues plus grands, en se concentrant sur leur efficacité et leur aptitude aux environnements liés aux ressources. Les SLM, avec moins de 10 milliards de paramètres, offrent une efficacité de vitesse et de ressources cruciale pour l'informatique Edge et les applications en temps réel. Cet article détaille leur création, leurs applications et leur implémentation à l'aide d'Olllama sur Google Colab.
Ce guide couvre:
- Comprendre les SLM: Apprenez les caractéristiques déterminantes des SLM et leurs principales différences par rapport aux LLM.
- Techniques de création de SLM: explorez les méthodes de distillation, d'élagage et de quantification des connaissances utilisées pour créer des SLM efficaces à partir de LLMS.
- Évaluation des performances: Comparez les performances de divers SLM (LLAMA 2, Microsoft PHI, Qwen 2, Gemma 2, Mistral 7B) à travers une analyse comparative de leurs sorties.
- Implémentation pratique: un guide étape par étape pour exécuter des SLM sur Google Colab à l'aide d'Olllama.
- Applications de SLMS: Découvrez les diverses applications où les SLM excellaient, y compris les chatbots, les assistants virtuels et les scénarios informatiques Edge.
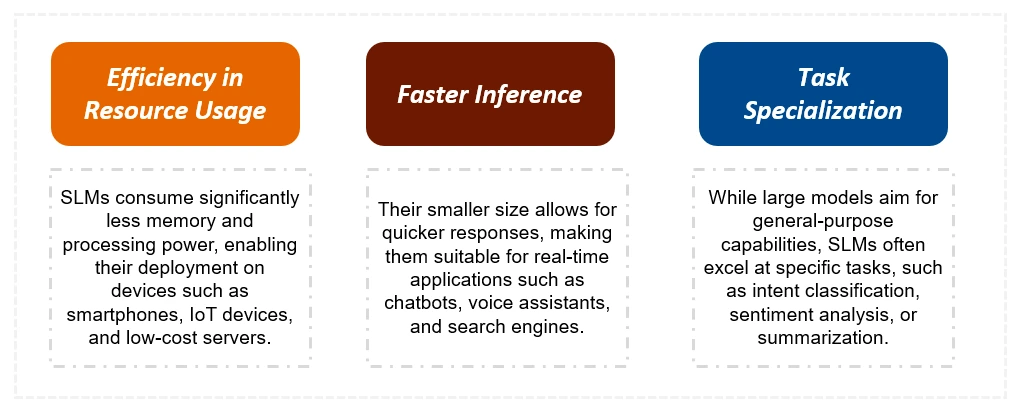
Différences clés: SLMS vs LLMS
Les SLM sont nettement plus petits que les LLM, nécessitant moins de données de formation et de ressources de calcul. Il en résulte des temps d'inférence et des coûts plus rapides. Alors que les LLM excellaient en complexe, les tâches générales, les SLM sont optimisés pour des tâches spécifiques et sont mieux adaptés aux dispositifs limités aux ressources. Le tableau ci-dessous résume les principales distinctions:
| Fonctionnalité | Modèles de petit langage (SLMS) | Modèles de grande langue (LLMS) |
|---|---|---|
| Taille | Significativement plus petit (moins de 10 milliards de paramètres) | Beaucoup plus grand (centaines de milliards ou milliards de paramètres) |
| Données de formation | Ensembles de données plus petits et ciblés | Ensembles de données massifs et diversifiés |
| Temps de formation | Plus court (semaines) | Plus long (mois) |
| Ressources | Faibles exigences de calcul | Exigences de calcul élevées |
| Maîtrise de la tâche | Tâches spécialisées | Tâches à usage général |
| Inférence | Peut fonctionner sur les appareils Edge | Nécessite généralement des GPU puissants |
| Temps de réponse | Plus rapide | Ralentissez |
| Coût | Inférieur | Plus haut |
Bâtiment SLMS: techniques et exemples
Cette section détaille les méthodes utilisées pour créer des SLM à partir de LLMS:
- Distillation des connaissances: un modèle "étudiant" plus petit apprend des sorties d'un modèle plus grand "enseignant".
- Élagage: supprime les connexions ou les neurones moins importants dans le modèle plus grand.
- Quantification: réduit la précision des paramètres du modèle, abaissant les exigences de la mémoire.
L'article présente ensuite une comparaison détaillée de plusieurs SLM de pointe, notamment Llama 2, Microsoft Phi, Qwen 2, Gemma 2 et Mistral 7B, mettant en évidence leurs caractéristiques uniques et leurs références de performance.

Exécution des SLM avec Olllama sur Google Colab
Un guide pratique montre comment utiliser Olllama pour exécuter des SLM sur Google Colab, fournissant des extraits de code pour l'installation, la sélection du modèle et l'exécution rapide. L'article présente les sorties de différents modèles, permettant une comparaison directe de leurs performances sur un exemple de tâche.
Conclusion et FAQ
L'article se termine en résumant les avantages des SLM et leur aptitude à diverses applications. Une section de questions fréquemment posées traite des requêtes communes sur les SLM, la distillation des connaissances et les différences entre l'élagage et la quantification. Le point à retenir clé met l'accent sur l'équilibre que les SLM par l'efficacité et les performances, ce qui en fait de précieux outils pour les développeurs et les entreprises.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
L'article passe en revue les meilleurs générateurs d'art AI, discutant de leurs fonctionnalités, de leur aptitude aux projets créatifs et de la valeur. Il met en évidence MidJourney comme la meilleure valeur pour les professionnels et recommande Dall-E 2 pour un art personnalisable de haute qualité.
 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
L'article compare les meilleurs chatbots d'IA comme Chatgpt, Gemini et Claude, en se concentrant sur leurs fonctionnalités uniques, leurs options de personnalisation et leurs performances dans le traitement et la fiabilité du langage naturel.
 10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
10 extensions de codage générateur AI dans le code vs que vous devez explorer
Apr 13, 2025 am 01:14 AM
Hé là, codant ninja! Quelles tâches liées au codage avez-vous prévues pour la journée? Avant de plonger plus loin dans ce blog, je veux que vous réfléchissiez à tous vos malheurs liés au codage - les énumérez. Fait? - Let & # 8217
 Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
L'article traite des meilleurs assistants d'écriture d'IA comme Grammarly, Jasper, Copy.ai, WireSonic et Rytr, en se concentrant sur leurs fonctionnalités uniques pour la création de contenu. Il soutient que Jasper excelle dans l'optimisation du référencement, tandis que les outils d'IA aident à maintenir le ton
 AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta & # 039; S Llama 3.2, Google's Gemini 1.5, et plus
Apr 11, 2025 pm 12:01 PM
Le paysage de l'IA de cette semaine: un tourbillon de progrès, de considérations éthiques et de débats réglementaires. Les principaux acteurs comme Openai, Google, Meta et Microsoft ont déclenché un torrent de mises à jour, des nouveaux modèles révolutionnaires aux changements cruciaux de LE
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
La récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
 Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
L'article examine les meilleurs générateurs de voix d'IA comme Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson et Descript, en se concentrant sur leurs fonctionnalités, leur qualité vocale et leur aptitude à différents besoins.
