

La gestion des données manquantes est une étape cruciale dans l'analyse des données et l'apprentissage automatique. Les valeurs manquantes, provenant de diverses sources telles que les erreurs de saisie des données ou les limitations inhérentes aux données, peuvent avoir un impact gravement sur la précision de l'analyse et la fiabilité du modèle. Pandas, une puissante bibliothèque Python, fournit la méthode fillna() - un outil polyvalent pour une imputation efficace de données manquantes. Cette méthode permet de remplacer les valeurs manquantes par diverses stratégies, en garantissant l'exhaustivité des données pour l'analyse.

Table des matières
fillna()fillna()
fillna()Qu'est-ce que l'imputation des données?
L'imputation des données est la technique de remplissage des points de données manquants dans un ensemble de données. Les données manquantes pose des défis importants pour de nombreuses méthodes analytiques et algorithmes d'apprentissage automatique qui nécessitent des ensembles de données complets. L'imputation aborde cela en estimant et en remplaçant les valeurs manquantes par des substituts plausibles en fonction des données disponibles.
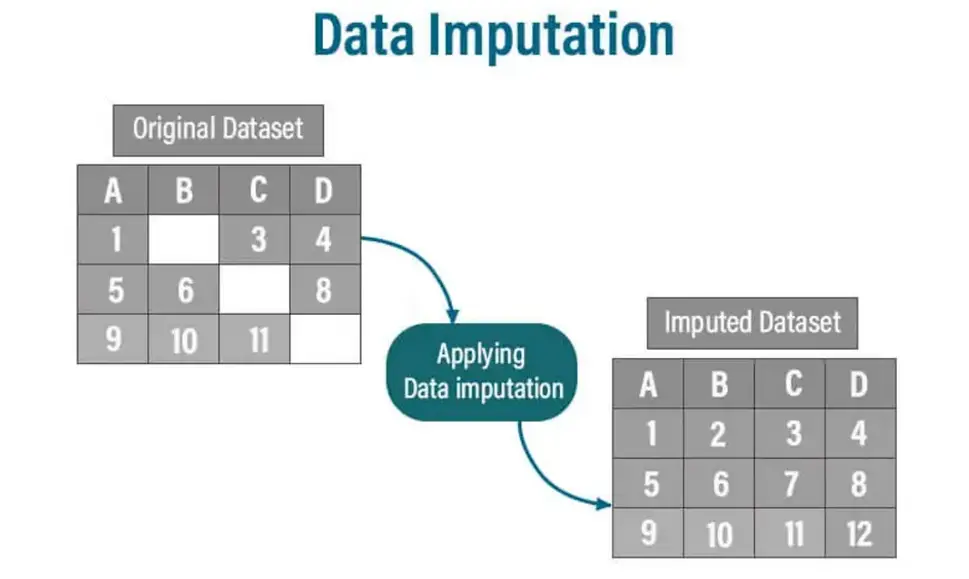
Pourquoi l'imputation des données est-elle importante?
Plusieurs raisons clés mettent en évidence l'importance de l'imputation des données:
Comprendre Pandas fillna()
La méthode Pandas fillna() est conçue pour remplacer les valeurs NaN (pas un nombre) dans DataFrames ou Series. Il offre diverses stratégies d'imputation.
Syntaxe fillna()

Les paramètres clés incluent value (la valeur de remplacement), method (par exemple, «ffill» pour le remplissage vers l'avant, «bfill» pour le remplissage vers l'arrière), axis , inplace , limit et downcast .
Utilisation fillna() pour différentes techniques d'imputation
Plusieurs techniques d'imputation peuvent être implémentées à l'aide de fillna() :
(Des exemples de code pour chaque technique seraient inclus ici, reflétant la structure et le contenu des exemples de code du texte d'origine.)
Conclusion
La gestion efficace des données manquantes est vitale pour une analyse fiable des données et l'apprentissage automatique. La méthode fillna() de Pandas offre une solution puissante et flexible, offrant une gamme de stratégies d'imputation pour s'adapter à différents types de données et contextes. Le choix de la bonne méthode dépend des caractéristiques de l'ensemble de données et des objectifs d'analyse.
Questions fréquemment posées
(La section FAQS serait conservée, reflétant le contenu du texte d'origine.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment créer un nouveau dossier dans Webstorm
Comment créer un nouveau dossier dans Webstorm
 Comment résoudre le problème selon lequel document.cookie ne peut pas être obtenu
Comment résoudre le problème selon lequel document.cookie ne peut pas être obtenu
 Comment lire le retour chariot en Java
Comment lire le retour chariot en Java
 commande de ligne de rupture cad
commande de ligne de rupture cad
 Introduction aux types d'interfaces
Introduction aux types d'interfaces
 Yiouoky est-il un logiciel légal ?
Yiouoky est-il un logiciel légal ?
 Quels sont les outils de classement des mots clés SEO ?
Quels sont les outils de classement des mots clés SEO ?
 Que faire si l'ordinateur simule la mort
Que faire si l'ordinateur simule la mort








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



