

Dans le monde actuel axé sur les données, une analyse efficace des données est primordiale pour la prise de décision éclairée. Python, avec sa syntaxe conviviale et ses vastes bibliothèques, est devenue le langage incontournable pour les scientifiques des données et les analystes. Cet article met en évidence dix bibliothèques Python essentielles pour l'analyse des données, s'adressant aux utilisateurs novices et expérimentés.
Numpy forme le fondement des capacités de calcul numérique de Python. Il excelle à manipuler de grandes tableaux et matrices multidimensionnelles, offrant une suite complète de fonctions mathématiques pour une manipulation efficace de réseau.
Forces:
Limites:
Importer Numpy comme NP
données = np.array ([1, 2, 3, 4, 5])
imprimer ("Array:", données)
print ("Mean:", np.mean (data))
Imprimer ("écart-type:", np.std (données))Sortir

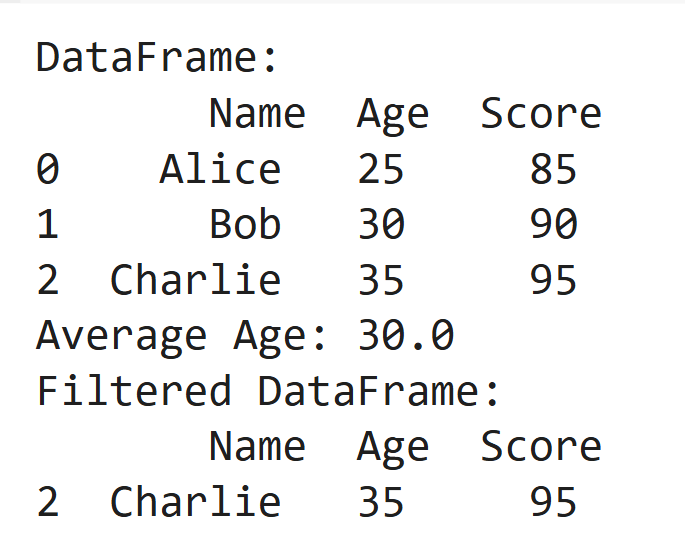
Pandas simplifie la manipulation des données avec sa structure DataFrame, idéale pour travailler avec des données tabulaires. Le nettoyage, la transformation et l'analyse des ensembles de données structurés devient beaucoup plus facile avec les pandas.
Forces:
Limites:
Importer des pandas en tant que PD
data = pd.dataframe ({'name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'score': [85, 90, 95]})
imprimer ("dataframe: \ n", données)
imprimer ("Âge moyen:", données ['âge']. Mean ())
Imprimer ("Filtora DataFrame: \ n", données [data ['score']> 90])Sortir
Matplotlib est une bibliothèque de tracé polyvalente, permettant la création d'un large éventail de visualisations statiques, interactives et même animées.
Forces:
Limites:
Importer Matplotlib.pyplot en tant que plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot (x, y, label = "Line Plot")
plt.xLabel ('x-axe')
plt.ylabel («axe y-y-»)
plt.title («Exemple Matplotlib»)
plt.legend ()
plt.show ()Sortir

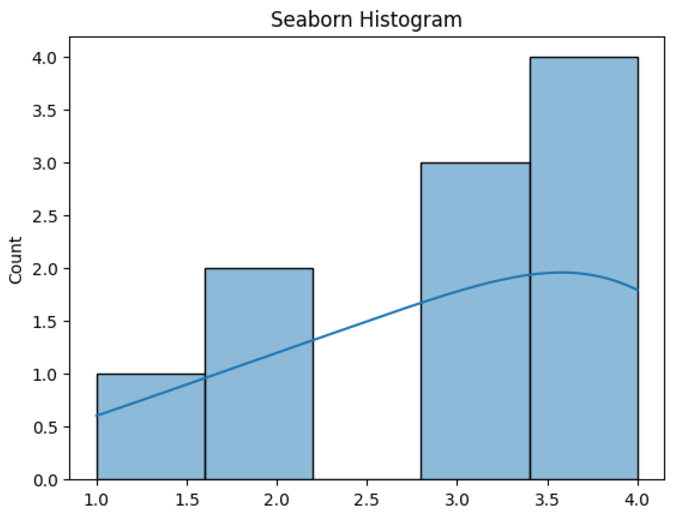
Seaborn s'appuie sur Matplotlib, simplifiant la création de parcelles statistiquement informatives et visuellement attrayantes.
Forces:
Limites:
Importer Seaborn comme SNS Importer Matplotlib.pyplot en tant que plt Données = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4] sns.histplot (data, kde = true) plt.title («Histogramme marin») plt.show ()
Sortir
Scipy étend Numpy, offrant des outils avancés pour l'informatique scientifique, y compris l'optimisation, l'intégration et le traitement du signal.
Forces:
Limites:
à partir de scipy.stats import ttest_ind
Groupe 1 = [1, 2, 3, 4, 5]
Groupe2 = [2, 3, 4, 5, 6]
t_stat, p_value = ttest_ind (groupe1, groupe2)
print ("t-statistic:", t_stat)
print ("p-valeur:", p_value)Sortir

Scikit-Learn est une bibliothèque d'apprentissage automatique puissante, fournissant des outils pour la classification, la régression, le regroupement et la réduction de la dimensionnalité.
Forces:
Limites:
De Sklearn.Linear_Model Import Lineargression
X = [[1], [2], [3], [4]]
y = [2, 4, 6, 8]
modèle = linéaire ()
Model.Fit (x, y)
print ("prédiction pour x = 5:", modèle.predict ([[5]]) [0])Sortir
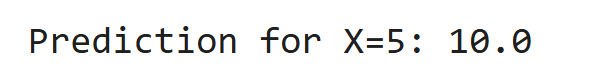
Les modèles de statistiques se concentrent sur la modélisation statistique et les tests d'hypothèse, particulièrement utiles pour l'économétrie et la recherche statistique.
Forces:
Limites:
importer statsmodels.api comme sm X = [1, 2, 3, 4] y = [2, 4, 6, 8] X = sm.add_constant (x) modèle = sm.ols (y, x) .fit () print (Model.Summary ())
Sortir

Plotly crée des visualisations interactives et prêtes pour le Web, parfaites pour les tableaux de bord et les applications Web.
Forces:
Limites:
Importer Plotly.express as px data = px.data.iris () Fig = px.scatter (data, x = "sepal_width", y = "sepal_length", color = "espèce", title = "Iris Dataset Scatter Plot") Fig.show ()
Sortir

Pyspark fournit une interface Python à Apache Spark, permettant un calcul distribué pour le traitement de données à grande échelle.
Forces:
Limites:
! Pip installer Pyspark
De Pyspark.sql Import Sparkcession
Spark = SparkSession.Builder.AppNAME ("Exemple Pyspark"). GetorCreate ()
data = Spark.CreateDataFrame ([(1, "Alice"), (2, "bob")], ["id", "name"])
data.show ()Sortir

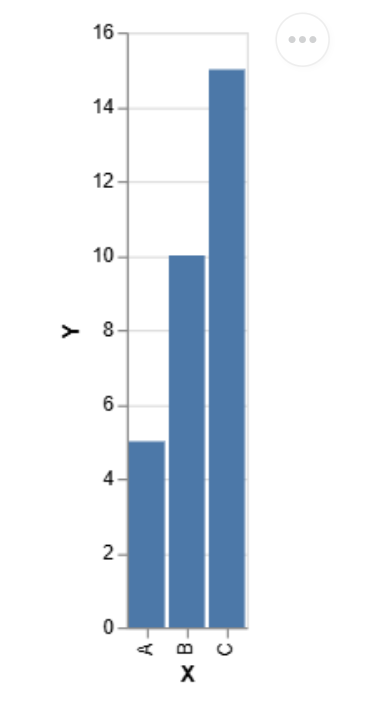
Altair est une bibliothèque de visualisation déclarative basée sur Vega et Vega-Lite, offrant une syntaxe concise pour créer des parcelles sophistiquées.
Forces:
Limites:
Importer Altair comme Alt
Importer des pandas en tant que PD
data = pd.dataframe ({'x': ['a', 'b', 'c'], 'y': [5, 10, 15]})
chart = alt.chart (data) .mark_bar (). Encode (x = 'x', y = 'y')
chart.display ()Sortir
Le choix de la bibliothèque appropriée dépend de plusieurs facteurs: la nature de votre tâche (nettoyage des données, visualisation, modélisation), taille de l'ensemble de données, objectifs d'analyse et niveau d'expérience. Considérez les forces et les limites de chaque bibliothèque avant de faire votre sélection.
La popularité de Python dans l'analyse des données découle de sa facilité d'utilisation, de vastes bibliothèques, de son soutien communautaire solide et de son intégration transparente avec des outils de Big Data.
Le riche écosystème de bibliothèques de Python permet aux analystes de données de relever divers défis, de la simple exploration des données aux tâches complexes d'apprentissage automatique. La sélection des bons outils pour le travail est cruciale, et cet aperçu fournit une base solide pour choisir les meilleures bibliothèques Python pour vos besoins d'analyse de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 Qu'est-ce que la monnaie numérique
Qu'est-ce que la monnaie numérique
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Nettoyer les fichiers indésirables dans Win10
Nettoyer les fichiers indésirables dans Win10
 point de symbole spécial
point de symbole spécial
 À quelles touches les flèches font-elles référence dans les ordinateurs ?
À quelles touches les flèches font-elles référence dans les ordinateurs ?
 Comment utiliser la fonction Print() en Python
Comment utiliser la fonction Print() en Python
 Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.
Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



