

Cet article explore la génération de la récupération (RAG), une technique d'IA de pointe qui stimule la précision de la réponse en fusionnant les capacités de récupération et de génération. RAG améliore la capacité de l'IA à fournir des réponses fiables et contextuellement pertinentes en récupérant d'abord les informations actuelles pertinentes d'une base de connaissances avant de générer une réponse. La discussion couvre en détail le flux de travail RAG, y compris l'utilisation de bases de données vectorielles pour une récupération efficace des données, l'importance des mesures de distance pour l'appariement de similitudes et la façon dont le chiffon atténue les pièges d'IA communs comme les hallucinations et les confabulations. Des étapes pratiques pour la mise en place et la mise en œuvre du chiffon sont également fournies, ce qui en fait un guide complet pour quiconque visant à améliorer la récupération des connaissances basée sur l'IA.
* Cet article fait partie du *** Data Science Blogathon.
Le RAG est une méthode d'IA qui améliore la précision des réponses en récupérant des informations pertinentes avant de générer une réponse. Contrairement à l'IA traditionnelle, qui repose uniquement sur les données de formation, RAG recherche une base de données ou une source de connaissances pour des informations à jour ou spécifiques. Ces informations informent ensuite la génération d'une réponse plus précise et fiable. L'approche RAG combine des modèles de récupération et de génération pour améliorer la qualité et la précision du contenu généré, en particulier dans les tâches PNL.
Lire plus approfondie: Génération auprès de la récupération pour les tâches NLP à forte intensité de connaissances
Le workflow Rag se compose de deux étapes primaires: la récupération et la génération. Le processus étape par étape est décrit ci-dessous.
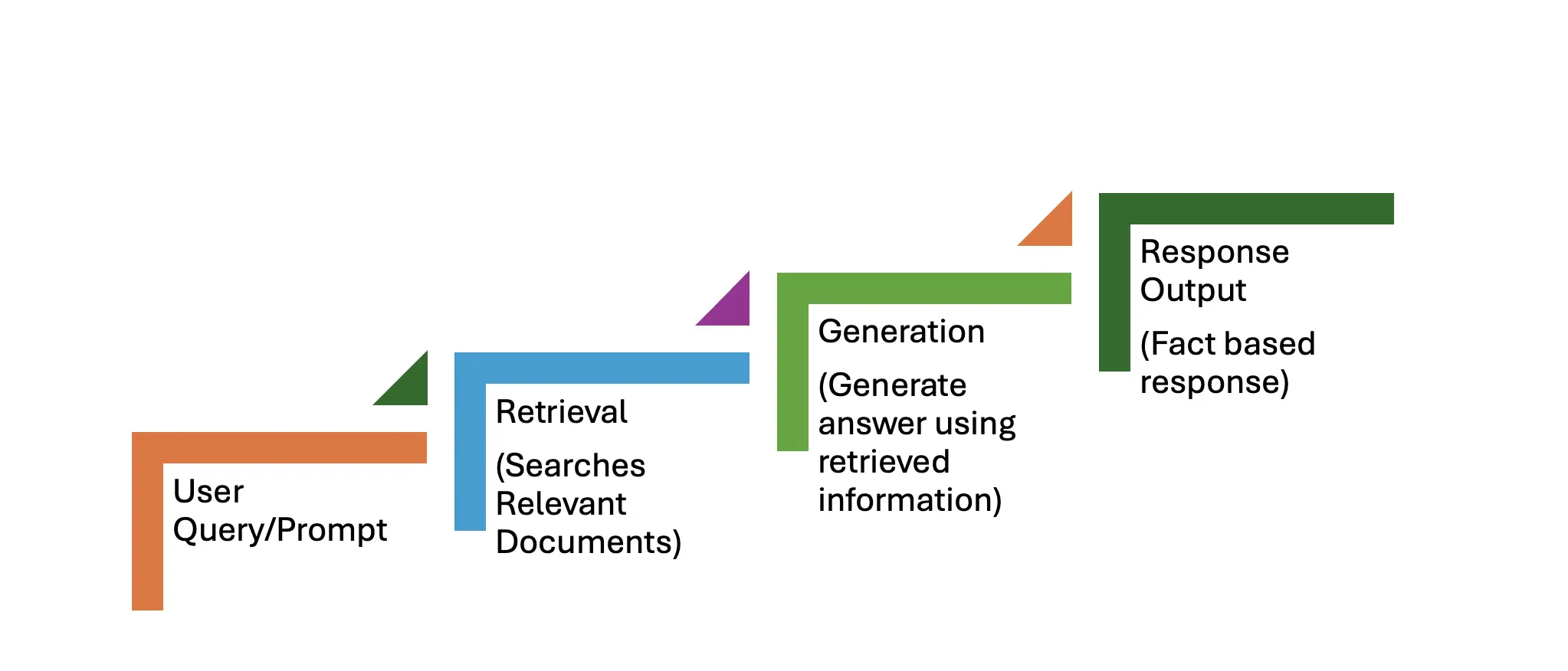
Une requête utilisateur, telle que: "Quelles sont les dernières avancées de l'informatique quantique?" sert d'invite.
Cette phase comprend trois étapes:
Cette phase implique également trois étapes:
Le système renvoie une réponse factuellement précise et à jour, supérieure à ce qu'un modèle purement génératif pourrait produire.
La comparaison de l'IA avec et sans chiffon met en évidence le pouvoir transformateur du chiffon. Les modèles traditionnels reposent uniquement sur les données pré-formées, tandis que RAG améliore les réponses avec la récupération des informations en temps réel, combler l'écart entre les sorties statiques et dynamiques et conscientes.
| Avec des ragots | Sans chiffon |
|---|---|
| Récupère les informations actuelles à partir de sources externes. | Repose uniquement sur les connaissances pré-formées (potentiellement dépassées). |
| Fournit des solutions spécifiques (par exemple, versions de correctifs, modifications de configuration). | Génère de vagues réponses généralisées manquant de détails exploitables. |
| Minimise le risque d'hallucination en ancrant les réponses dans des documents réels. | Risque plus élevé d'hallucination ou d'inexactitudes, en particulier pour les informations récentes. |
| Comprend les derniers avis ou correctifs de sécurité des fournisseurs. | Peut être conscient des avis ou des mises à jour récentes. |
| Combine des informations internes (spécifiques à l'organisation) et externes (base de données publiques). | Impossible de récupérer des informations nouvelles ou spécifiques à l'organisation. |
Les bases de données vectorielles sont cruciales pour une récupération de documents ou de données efficace et précise en RAG, sur la base de la similitude sémantique. Contrairement à la recherche basée sur les mots clés, qui repose sur la correspondance exacte du terme, les bases de données vectorielles représentent le texte en tant que vecteurs dans un espace de grande dimension, regroupant des significations similaires ensemble. Cela les rend très adaptés aux systèmes de chiffon. Une base de données vectorielle stocke des documents vectorisés, permettant une récupération d'informations plus précise pour les modèles d'IA.
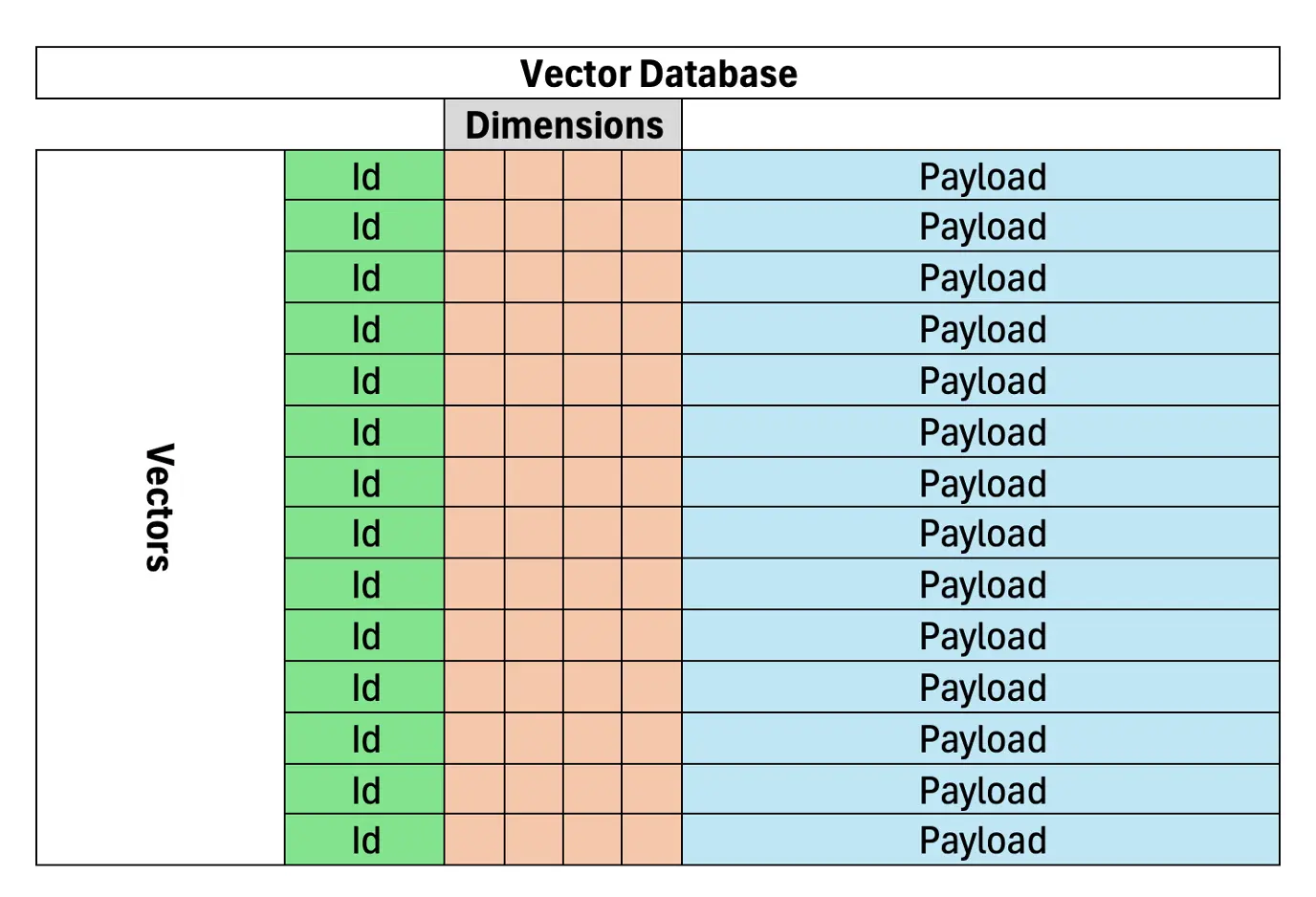
(Les sections restantes suivraient un modèle similaire de reformulation et de restructuration, en maintenant les informations et le placement d'image d'origine.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre une syntaxe invalide en Python
Comment résoudre une syntaxe invalide en Python
 securefx ne peut pas se connecter
securefx ne peut pas se connecter
 java configurer les variables d'environnement jdk
java configurer les variables d'environnement jdk
 Supprimer le champ du tableau
Supprimer le champ du tableau
 fil prix de la devise prix en temps réel
fil prix de la devise prix en temps réel
 Comment ouvrir le fichier iso
Comment ouvrir le fichier iso
 Qu'est-ce que le quota de disque
Qu'est-ce que le quota de disque
 Les principaux composants du dhtml
Les principaux composants du dhtml
 Quel est le rôle du groupe de consommateurs Kafka
Quel est le rôle du groupe de consommateurs Kafka








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



