

Cette enquête révolutionnaire, "Datased for Big Language Models: A Comprehensive Survey", publiée en février 2024, dévoile un trésor de plus de 400 ensembles de données de données méticuleusement catégorisés pour le développement de modèles de grand langage (LLM). Compilé par Yang Liu, Jiahuan Cao, Chongyu Liu, Kai Ding et Lianwen Jin, cette ressource est une mine d'or pour les chercheurs et les développeurs. Ce n'est pas seulement une collection statique; Il est régulièrement mis à jour, garantissant sa pertinence continue.
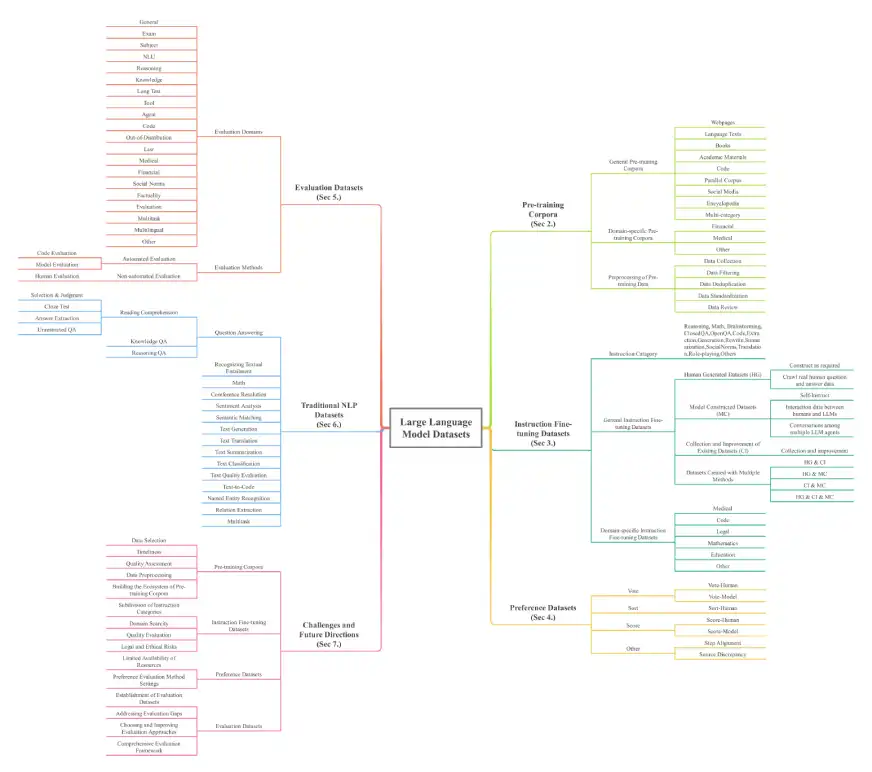
Le document donne un aperçu complet des ensembles de données LLM, essentiels pour comprendre les bases de ces modèles puissants. Les ensembles de données sont classés sur sept dimensions clés: les corpus de pré-formation, les ensembles de données de réglage fin des instructions, les ensembles de données de préférence, les ensembles de données d'évaluation, les ensembles de données NLP traditionnels, les ensembles de données de données de génération (RAG) multi-modaux de grande langue (MLLMS). L'échelle est impressionnante, avec plus de 774,5 To de données pour la pré-formation seule et 700 millions d'instances dans d'autres catégories, couvrant 32 domaines et 8 langues.

Catégories et exemples de l'ensemble de données clés:
L'enquête détaille divers types de jeux de données, notamment:
Corparèmes de pré-formation: collections de texte massives pour la formation initiale de LLM. Les exemples incluent Madlad-400 (jetons 2.8t), Fineweb (jetons de 15 To) et BookCorpusopen (17 868 livres). Ceux-ci sont en outre décomposés en corpus généraux (pages Web, livres, textes linguistiques) et corpus spécifiques au domaine (finance, médical, mathématiques).
Ensembles de données de réglage fin des instructions: paires d'instructions et réponses correspondantes pour affiner le comportement du modèle. Les exemples incluent Databricks-Dolly-15k et Alpaca_data. Ceux-ci sont également classés en ensembles de données généraux et spécifiques au domaine (médicale, code).
Ensembles de données de préférence: utilisés pour évaluer et améliorer les sorties du modèle en comparant plusieurs réponses. Les exemples incluent le chatbot_arena_conversations et HH-RLHF.
Ensembles de données d'évaluation: spécialement conçu pour comparer les performances LLM sur diverses tâches. Les exemples incluent Alpacaeval et Bayling-80.
Ensembles de données NLP traditionnels: ensembles de données utilisés pour les tâches NLP pré-LLM. Les exemples incluent Boolq, Cosmosqa et PubMedqa.
Ensembles de données multimodaux de grands langues (MLLMS): ensembles de données combinant du texte et d'autres modalités (images, vidéos). Les exemples incluent Moscar et MMRS-1M.
Ensembles de données de génération augmentée (RAG) de récupération: ensembles de données qui améliorent les LLM avec des capacités de récupération de données externes. Les exemples incluent Crud-Rag et Wikieval.

Source: ensembles de données pour les modèles de grande langue: une enquête complète
L'architecture de l'enquête est illustrée ci-dessous:
Conclusion et exploration plus approfondie:
Cette enquête sert de ressource vitale, guidant les chercheurs et les développeurs dans le domaine LLM. Le référentiel fourni (Awesome-Llms-Datasets) propose une feuille de route complète pour accéder et utiliser ces ensembles de données inestimables. La catégorisation détaillée et les statistiques complètes en font un outil essentiel pour toute personne travaillant avec ou recherche de LLMS. L'article relève également des défis clés et suggère des orientations de recherche futures.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment activer le mode sans échec de Word
Comment activer le mode sans échec de Word
 Introduction à l'utilisation de la fonction MySQL ELT
Introduction à l'utilisation de la fonction MySQL ELT
 Que faire si la connexion win8wifi n'est pas disponible
Que faire si la connexion win8wifi n'est pas disponible
 Comment utiliser la fonction de ligne
Comment utiliser la fonction de ligne
 Que comprennent les plateformes de commerce électronique ?
Que comprennent les plateformes de commerce électronique ?
 Comment enregistrer un e-mail professionnel
Comment enregistrer un e-mail professionnel
 Comment configurer la mémoire virtuelle
Comment configurer la mémoire virtuelle
 Comment arrondir dans Matlab
Comment arrondir dans Matlab
 utilisation de plusieurs fonctions
utilisation de plusieurs fonctions








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



