

Ce billet de blog explore des techniques efficaces de gestion de la mémoire pour charger de grands modèles Pytorch, en particulier bénéfique lorsqu'il s'agit de ressources GPU ou CPU limitées. L'auteur se concentre sur les scénarios où les modèles sont enregistrés à l'aide de torch.save(model.state_dict(), "model.pth") . Alors que les exemples utilisent un modèle de langue large (LLM), les techniques sont applicables à tout modèle de pytorch.
Stratégies clés pour le chargement des modèles efficace:
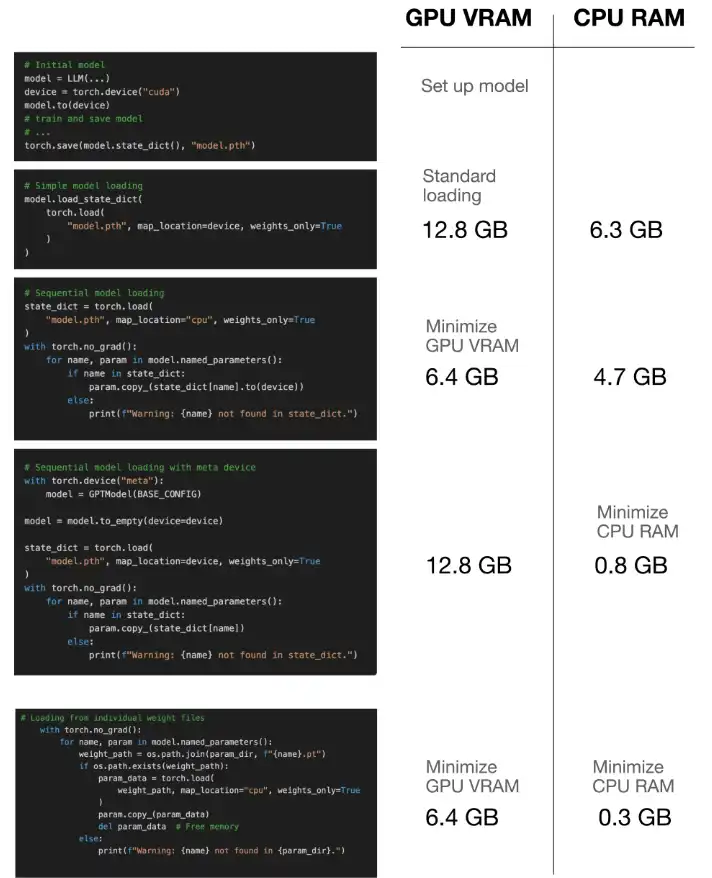
L'article détaille plusieurs méthodes pour optimiser l'utilisation de la mémoire pendant le chargement du modèle:
Charge de poids séquentiel: cette technique charge l'architecture du modèle sur le GPU, puis copie de manière itérative des poids individuels de la mémoire du CPU au GPU. Cela empêche la présence simultanée à la fois du modèle complet et des poids dans la mémoire GPU, réduisant considérablement la consommation de mémoire de mémoire de pointe.
Meta Device: le périphérique "Meta" de Pytorch permet la création du tenseur sans allocation de mémoire immédiate. Le modèle est initialisé sur le dispositif Meta, puis transféré au GPU, et les poids sont chargés directement sur le GPU, minimisant l'utilisation de la mémoire du processeur. Ceci est particulièrement utile pour les systèmes avec un RAM CPU limité.
mmap=True dans torch.load() : cette option utilise des E / S de fichiers mappées à mémoire, permettant à Pytorch de lire les données du modèle directement à partir du disque à la demande, plutôt que de tout charger dans RAM. Ceci est idéal pour les systèmes avec une mémoire CPU limitée et des E / S de disque rapide.
Économie et chargement individuels: En dernier recours pour des ressources extrêmement limitées, l'article suggère de sauvegarder chaque paramètre de modèle (tenseur) en tant que fichier séparé. Le chargement se produit ensuite un paramètre à la fois, minimisant l'empreinte de la mémoire à un moment donné. Cela se produit au prix de l'augmentation des frais généraux d'E / S.
Mise en œuvre pratique et comparaison:
Le post fournit des extraits de code Python présentant chaque technique, y compris les fonctions utilitaires pour suivre l'utilisation de la mémoire GPU et CPU. Ces repères illustrent les économies de mémoire réalisées par chaque méthode. L'auteur compare l'utilisation de la mémoire de chaque approche, mettant en évidence les compromis entre l'efficacité de la mémoire et les impacts potentiels de performance.
Conclusion:
L'article conclut en soulignant l'importance du chargement des modèles économe en mémoire, en particulier pour les grands modèles. Il recommande de sélectionner la technique la plus appropriée basée sur les limites matérielles spécifiques (RAM CPU, GPU VRAM) et les vitesses d'E / S. L'approche mmap=True est généralement préférée pour la RAM CPU limitée, tandis que le chargement de poids individuel est un dernier recours pour des environnements extrêmement contraints. La méthode de chargement séquentielle offre un bon équilibre pour de nombreux scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Base de données de restauration MySQL
Base de données de restauration MySQL
 Quels sont les frameworks Spring ?
Quels sont les frameworks Spring ?
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 Langage C pour trouver le multiple le plus petit commun
Langage C pour trouver le multiple le plus petit commun
 Qu'est-ce que la rigidité de l'utilisateur
Qu'est-ce que la rigidité de l'utilisateur
 Quel est le code espace en HTML
Quel est le code espace en HTML
 utilisation de la commande head
utilisation de la commande head
 Le but du niveau
Le but du niveau
 Quelles sont les principales différences entre Linux et Windows
Quelles sont les principales différences entre Linux et Windows








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



