

Apache Iceberg: un format de table moderne pour une gestion de lac de données améliorée
Apache Iceberg est un format de table de pointe conçu pour répondre aux lacunes des tables de ruche traditionnelles, offrant des performances supérieures, la cohérence des données et l'évolutivité. Cet article explore l'évolution d'Iceberg, les caractéristiques clés (transactions acides, l'évolution du schéma, le voyage dans le temps), l'architecture et les comparaisons avec d'autres formats de table comme Delta Lake et Parquet. Nous examinerons également son intégration avec les lacs de données modernes et son impact sur la gestion des données et l'analyse à grande échelle.
Originaire à Netflix en 2017 (l'idée originale de Ryan Blue et Daniel Weeks), Apache Iceberg a été créée pour résoudre les goulots d'étranglement des performances, des problèmes de cohérence et des limitations inhérentes au format de la table Hive. Open-Open et donnée à l'Apache Software Foundation en 2018, il a rapidement gagné du terrain, attirant les contributions de géants de l'industrie comme Apple, AWS et LinkedIn.
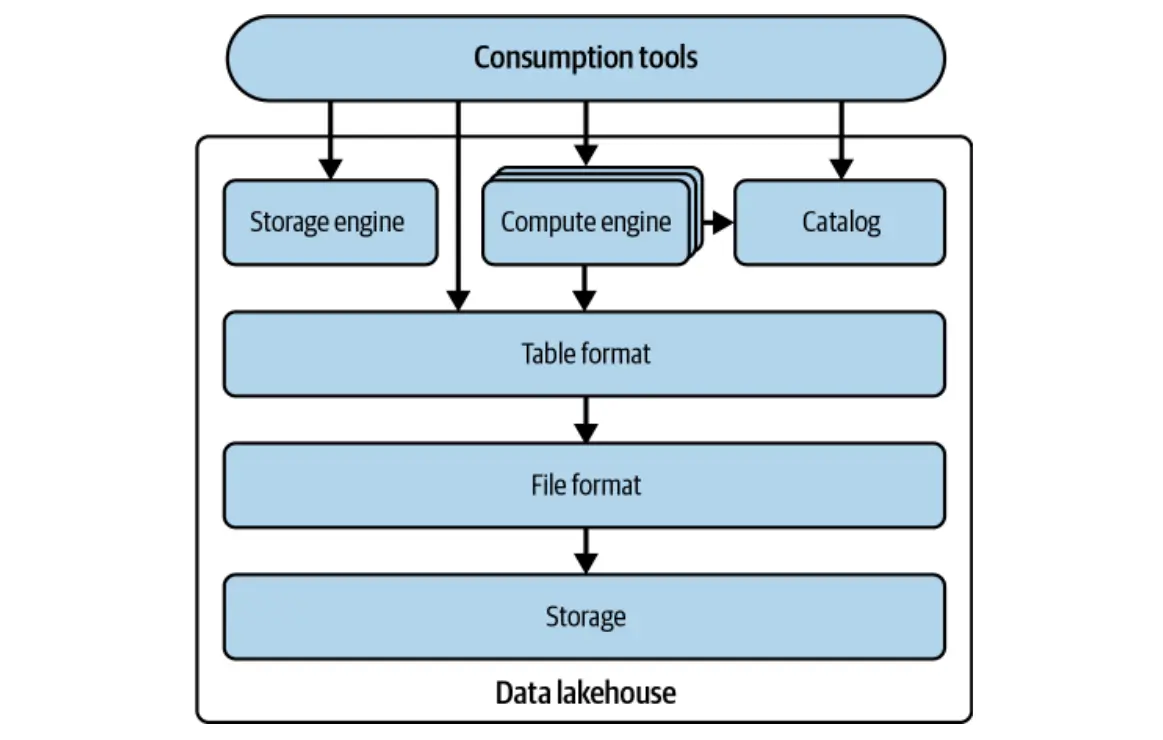
L'expérience de Netflix a mis en évidence une faiblesse critique de Hive: sa dépendance à l'égard des répertoires pour le suivi de la table. Cette approche manquait de granularité nécessaire pour une cohérence robuste, une concurrence efficace et les fonctionnalités avancées attendues dans les entrepôts de données modernes. Le développement d'Iceberg visait à surmonter ces limites en mettant l'accent sur:
Iceberg relève ces défis en suivant les tables en tant que liste structurée de fichiers, et non des répertoires. Il fournit un format standardisé définissant la structure des métadonnées sur plusieurs fichiers et propose des bibliothèques pour une intégration transparente avec des moteurs populaires comme Spark et Flink.
La conception d'Iceberg priorise la compatibilité avec les moteurs de stockage et de calcul existants, favorisant une large adoption sans changements significatifs. L'objectif est d'établir l'iceberg en tant que norme de l'industrie, permettant aux utilisateurs d'interagir avec les tables indépendamment du format sous-jacent. De nombreux outils de données offrent désormais un support d'iceberg natif.
Iceberg transcende simplement les limites de Hive; Il introduit de puissantes capacités améliorant les charges de travail Data Lake et Data Lakehouse. Les caractéristiques clés comprennent:
Iceberg utilise un contrôle de concurrence optimiste pour assurer les propriétés acides, garantissant que les transactions sont entièrement engagées ou complètement enroulées. Cela minimise les conflits tout en maintenant l'intégrité des données.
Contrairement aux lacs de données traditionnels, Iceberg permet de modifier les schémas de partitionnement sans réécrire l'ensemble du tableau. Cela garantit une optimisation efficace des requêtes sans perturber les données existantes.
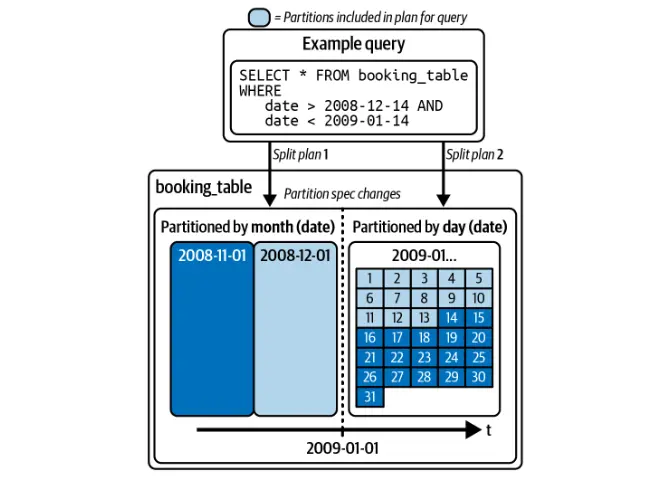
Iceberg optimise automatiquement les requêtes en fonction de la partition, éliminant la nécessité pour les utilisateurs de filtrer manuellement par colonnes de partition.
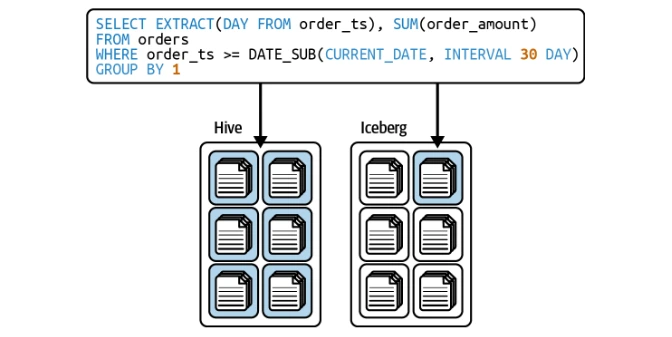
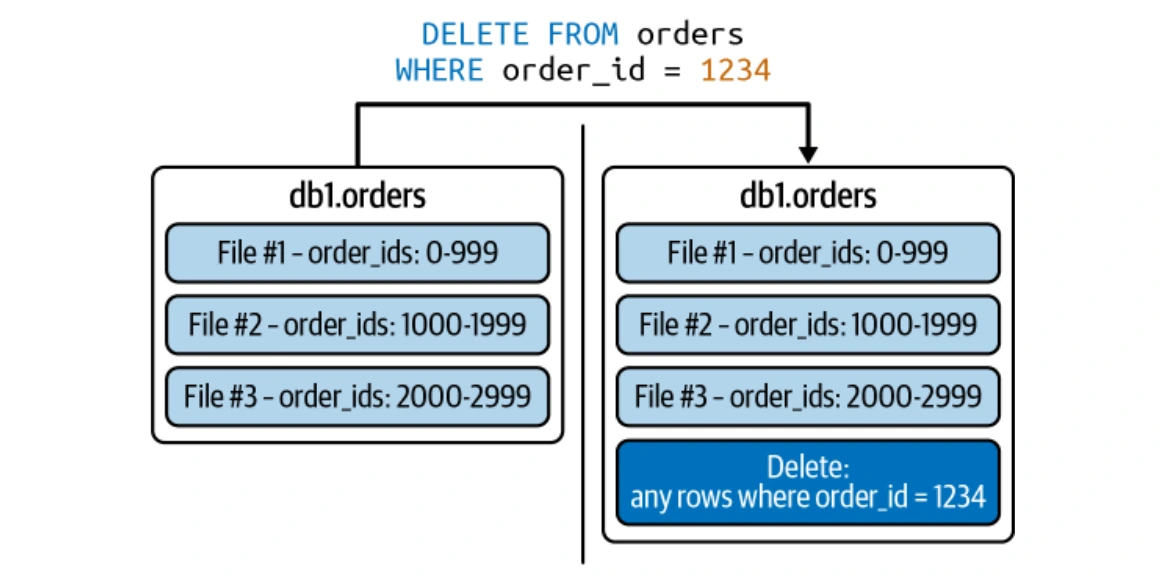
Iceberg prend en charge les stratégies de copie-écriture (vache) et de fusion sur la lecture (MOR) pour des mises à jour efficaces au niveau des lignes.
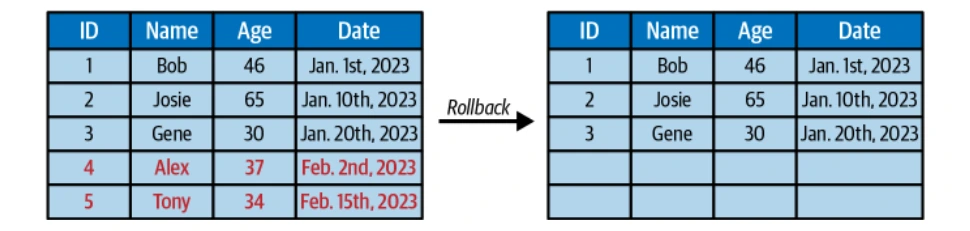
Les instantanés immuables d'Iceberg permettent des requêtes de voyage dans le temps et la capacité de revenir aux états de table précédents.

Iceberg prend en charge les modifications du schéma (ajoutant, supprimant ou modifiant les colonnes) sans réécriture de données, assurant la flexibilité et la compatibilité.
Cette section explore l'architecture d'Iceberg et comment elle surmonte les limites de Hive.
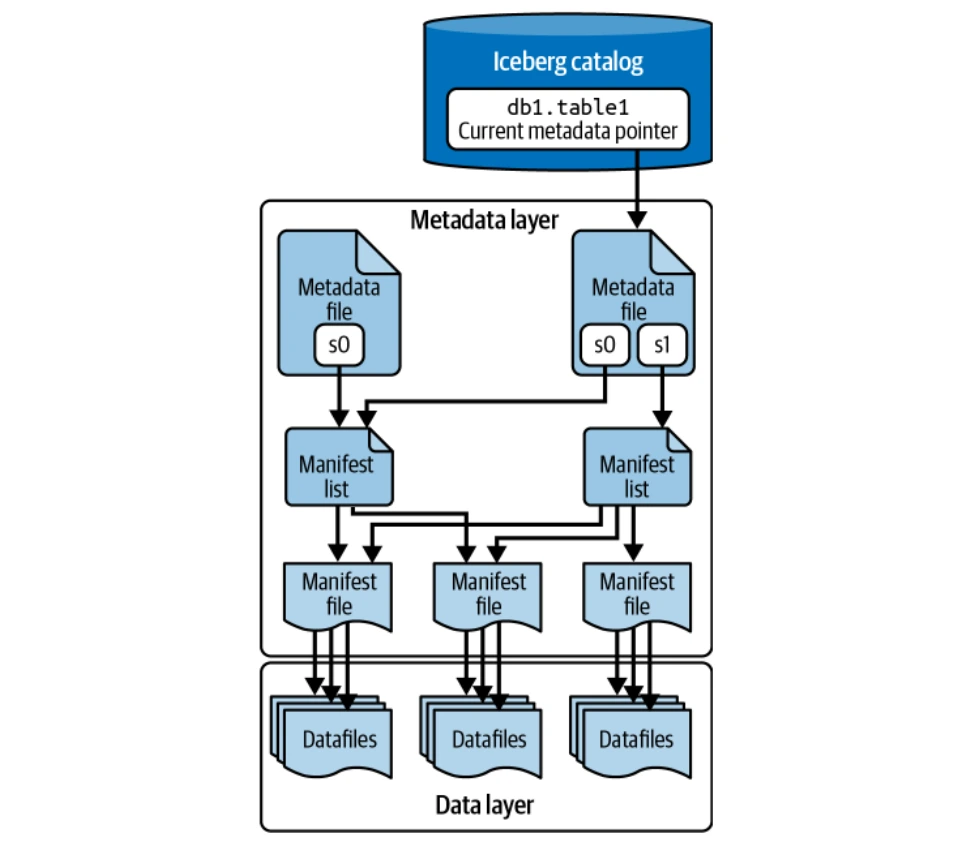
La couche de données stocke les données de table réelles (fichiers de données et supprimer des fichiers). Il est hébergé sur les systèmes de fichiers distribués (HDFS, S3, etc.) et prend en charge plusieurs formats de fichiers (Parquet, Orc, Avro). Le parquet est généralement préféré pour son stockage en colonnes.


Cette couche gère tous les fichiers de métadonnées dans une structure d'arborescence, suivant les fichiers de données et les opérations. Les composants clés incluent des fichiers manifestes, des listes manifestes et des fichiers de métadonnées. Les fichiers Puffin stockent des statistiques avancées et des index pour l'optimisation des requêtes.
Le catalogue agit comme un registre central, fournissant l'emplacement du fichier de métadonnées actuel pour chaque table, garantissant un accès cohérent pour tous les lecteurs et écrivains. Divers backends peuvent servir de catalogues iceberg (catalogue Hadoop, Metastore Hive, catalogue Nessie, catalogue AWS Glue).
Iceberg, Parquet, Orc et Delta Lake sont fréquemment utilisés dans le traitement des données à grande échelle. Iceberg se distingue comme un format de table offrant des garanties transactionnelles et des optimisations de métadonnées, contrairement à Parquet et Orc qui sont des formats de fichiers. Comparé au lac Delta, Iceberg excelle dans le schéma et l'évolution de la partition.
Apache Iceberg propose une approche robuste, évolutive et conviviale de la gestion des lacs de données. Ses fonctionnalités en font une solution convaincante pour les organisations qui gèrent les données à grande échelle.
Q1. Qu'est-ce qu'Apache iceberg? A. Un format de table open-source moderne améliorant les performances, la cohérence et l'évolutivité du lac.
Q2. Pourquoi Apache Iceberg est-il nécessaire? A. pour surmonter les limites de Hive dans la gestion des métadonnées et les capacités transactionnelles.
Q3. Comment iceberg gère-t-il l'évolution du schéma? A. Il prend en charge les changements de schéma sans nécessiter de réécritures de table complètes.
Q4. Qu'est-ce que l'évolution de la partition dans Iceberg? A. Modification des schémas de partitionnement sans réécrire des données historiques.
Q5. Comment iceberg prend-il en charge les transactions acides? A. grâce à un contrôle optimiste de la concurrence, en assurant des mises à jour atomiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment nettoyer le lecteur C de l'ordinateur lorsqu'il est plein
Comment nettoyer le lecteur C de l'ordinateur lorsqu'il est plein
 fil prix de la devise prix en temps réel
fil prix de la devise prix en temps réel
 Comment défendre les serveurs cloud contre les attaques DDoS
Comment défendre les serveurs cloud contre les attaques DDoS
 Comment télécharger Binance
Comment télécharger Binance
 Comment acheter et vendre du Bitcoin sur Huobi.com
Comment acheter et vendre du Bitcoin sur Huobi.com
 Comment ouvrir le fichier iso
Comment ouvrir le fichier iso
 Quelles sont les fonctions des réseaux informatiques
Quelles sont les fonctions des réseaux informatiques
 comment cacher l'adresse IP
comment cacher l'adresse IP
 Comment résoudre les problèmes lors de l'analyse des packages
Comment résoudre les problèmes lors de l'analyse des packages








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



