

Les modèles distillés de Deepseek, également vus sur Olllama et Groq Cloud, sont des versions plus petites et plus efficaces de LLMS originales, conçues pour correspondre aux performances des modèles plus importantes tout en utilisant moins de ressources. Ce processus de "distillation", une forme de compression du modèle, a été introduit par Geoffrey Hinton en 2015.
Table des matières:
Avantages des modèles distillés:
Connexes: Construire un système de chiffon pour le raisonnement d'IA avec un modèle distillé R1 Deepseek
Origine des modèles distillés:
L'article de 2015 d'Hinton, "Distilling the Knowledge in a Neural Network", a exploré la compression de grands réseaux de neurones en versions plus petites et préservant les connaissances. Un modèle plus grand "enseignant" forme un modèle "étudiant" plus petit, visant que l'élève reproduit les principaux poids appris de l'enseignant.
L'élève apprend en minimisant les erreurs contre deux cibles: la vérité au sol (cible dure) et les prédictions de l'enseignant (cible douce).
Composants à double perte:
La perte totale est une somme pondérée de ces pertes, contrôlée par le paramètre λ (lambda). La fonction Softmax, modifiée avec un paramètre de température (T), adoucit la distribution de probabilité, améliorant l'apprentissage. La perte molle est multipliée par T² pour compenser cela.




Distilbert et Distillgpt2:
Distilbert utilise la méthode d'Hinton avec une perte d'incorporation de cosinus. Il est nettement plus petit que Bert-Base mais avec une légère précision de précision. DistillGPT2, bien que plus rapide que GPT-2, montre une perplexité plus élevée (performances plus basses) sur de grands ensembles de données de texte.
Implémentation de la distillation LLM:
Cela implique la préparation des données, la sélection du modèle des enseignants et un processus de distillation à l'aide de cadres tels que les transformateurs de visage étreintes, l'optimisation du modèle TensorFlow, le distillateur Pytorch ou la vitesse profonde. Les métriques d'évaluation comprennent la précision, la vitesse d'inférence, la taille du modèle et l'utilisation des ressources.
Comprendre la distillation du modèle:
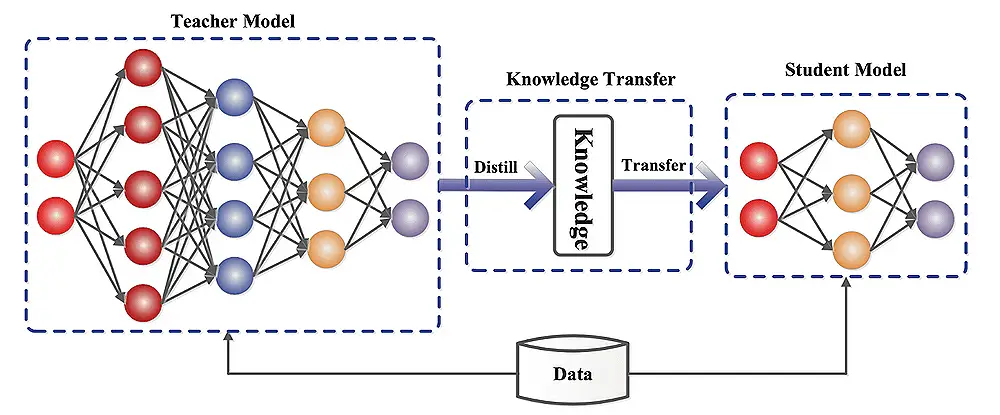
Le modèle étudiant peut être un modèle de professeur simplifié ou avoir une architecture différente. Le processus de distillation forme l'élève à imiter le comportement de l'enseignant en minimisant la différence entre leurs prédictions.


Défis et limitations:
Directions futures dans la distillation du modèle:
Applications du monde réel:
Conclusion:
Les modèles distillés offrent un équilibre précieux entre les performances et l'efficacité. Bien qu'ils ne puissent pas dépasser le modèle d'origine, leurs exigences de ressources réduites les rendent très bénéfiques dans diverses applications. Le choix entre un modèle distillé et l'original dépend du compromis de performance acceptable et des ressources de calcul disponibles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Sur quel échange se trouve Sols Inscription Coin ?
Sur quel échange se trouve Sols Inscription Coin ?
 Que sont les variables d'environnement
Que sont les variables d'environnement
 Les photos Windows ne peuvent pas être affichées
Les photos Windows ne peuvent pas être affichées
 Comment utiliser la fonction de longueur dans Matlab
Comment utiliser la fonction de longueur dans Matlab
 Comment résoudre l'erreur 1
Comment résoudre l'erreur 1
 Comment lire le retour chariot en Java
Comment lire le retour chariot en Java
 winkawaksrom
winkawaksrom
 Que signifient pleine largeur et demi-largeur ?
Que signifient pleine largeur et demi-largeur ?
 Utilisation de la classe Snoopy en php
Utilisation de la classe Snoopy en php








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



