

CS- semaine 5

Explication détaillée de la structure des données: du tableau à l'arbre, puis à la table de hachage
Cet article traite de plusieurs structures de données communes en profondeur, notamment des tableaux, des listes liées, des arbres de recherche binaires (BST) et des tables de hachage, et explique leur organisation en mémoire et leurs avantages et inconvénients.
Structure d'information et structure de données abstraite
La structure de l'information fait référence à la façon dont les informations sont organisées en mémoire, tandis que les structures de données abstraites sont notre compréhension conceptuelle de ces structures. Comprendre les structures de données abstraites nous aide à mieux mettre en œuvre diverses structures de données dans la pratique.
Pile et file d'attente
Les files d'attente sont une structure de données abstraite qui suit le principe FIFO (premier dans, premier sorti), similaire à l'attente en ligne. Ses principales opérations incluent la mise en file d'attente (ajoutant des éléments à la queue de la file d'attente) et la désactivation (en supprimant les éléments de la tête de la file d'attente).
La pile suit le principe LIFO (dernier dans le premier sortie), tout comme l'empilement d'une plaque. Ses opérations incluent la poussée (ajoutant des éléments au sommet de la pile) et en retirant les éléments supérieurs de la pile).
Tableau
Un tableau est une structure qui stocke en continu les données en mémoire. Comme le montre la figure ci-dessous, les tableaux occupent l'espace de stockage continu en mémoire.
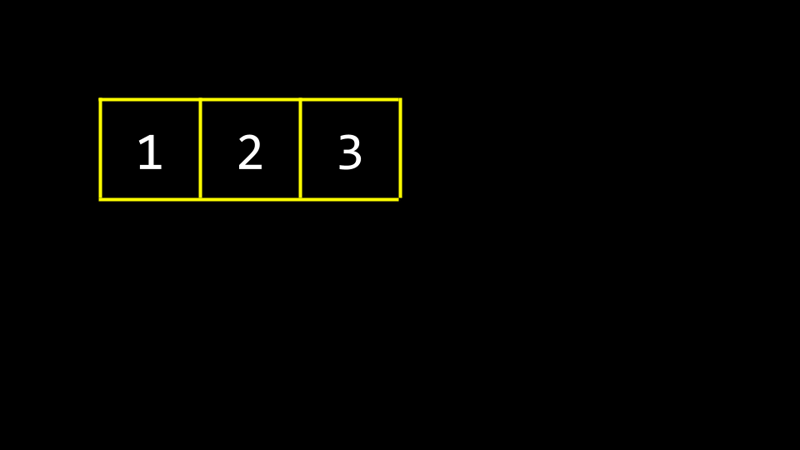
D'autres programmes, fonctions et variables peuvent exister en mémoire, ainsi que des données redondantes qui ont été utilisées auparavant. Si vous devez ajouter de nouveaux éléments au tableau, vous devez réaffecter la mémoire et copier l'intégralité du tableau, qui peut être inefficace.


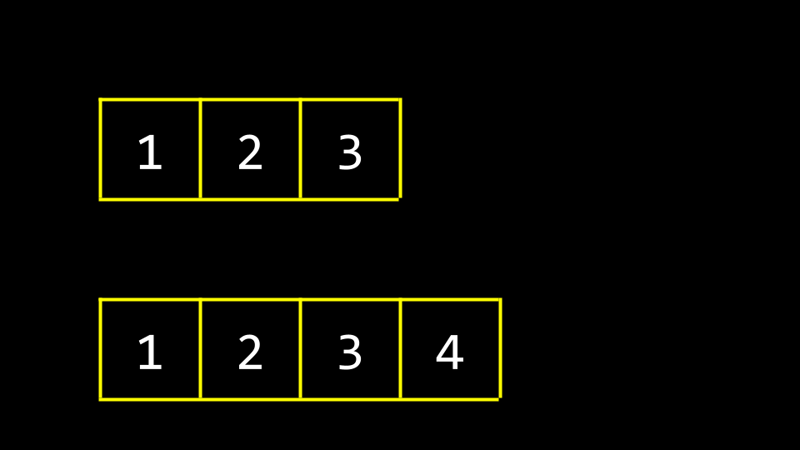
Bien que la pré-allocation de trop de mémoire puisse réduire les opérations de copie, elle gaspillera les ressources du système. Par conséquent, il est crucial d'allouer la mémoire en fonction des besoins réels.
Liste de liens
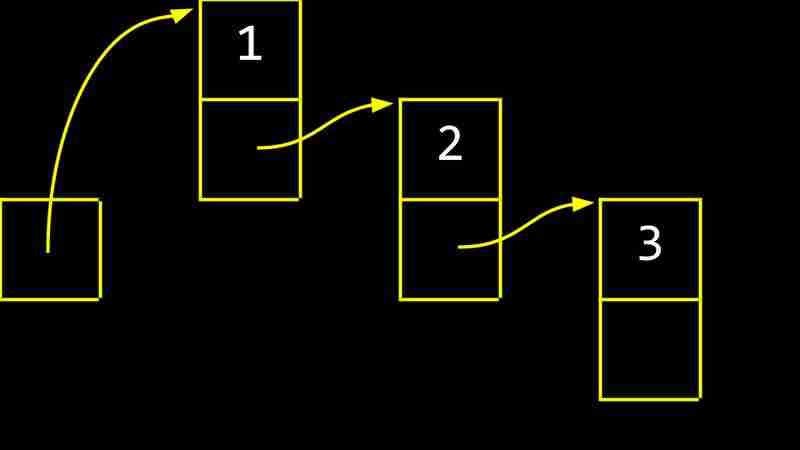
Les listes liées sont de puissantes structures de données qui permettent la concaténation des valeurs situées dans différentes régions de mémoire dans une liste et prennent en charge l'expansion ou la réduction dynamique.
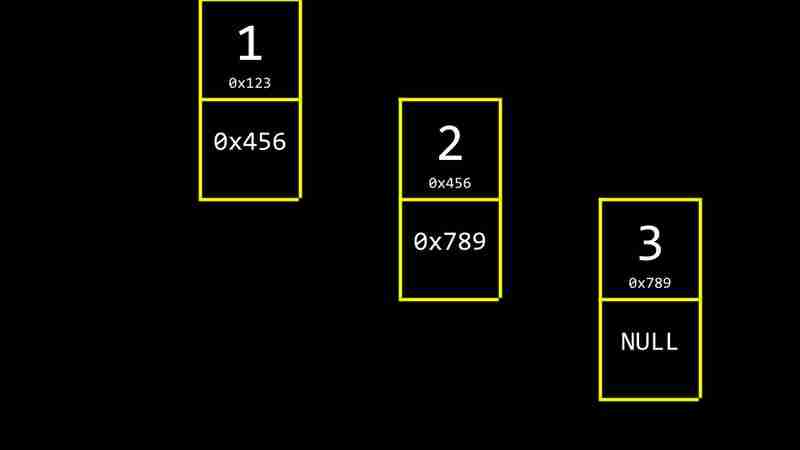
Chaque CS- semaine 5 contient deux valeurs: la valeur de données et un pointeur vers le CS- semaine 5 suivant. La valeur du pointeur du dernier CS- semaine 5 est nul, indiquant la fin de la liste liée.
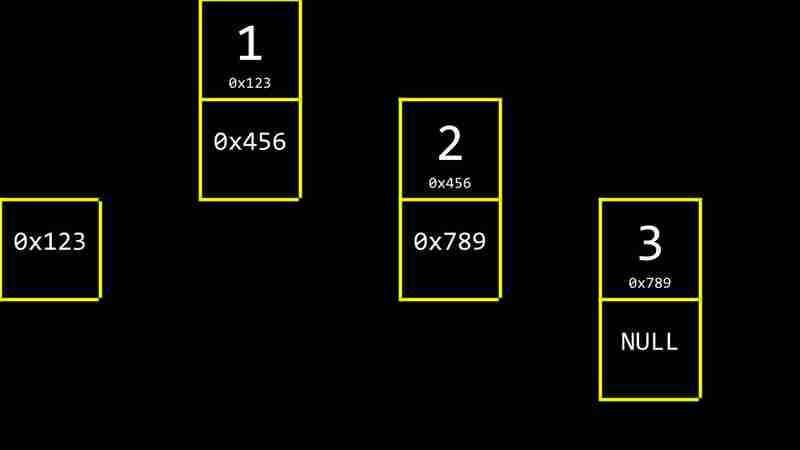
En langue C, les CS- semaine 5s peuvent être définis comme suit:
<code class="c">typedef struct node { int number; struct node *next; } node;</code>L'exemple suivant montre le processus de création d'une liste liée:

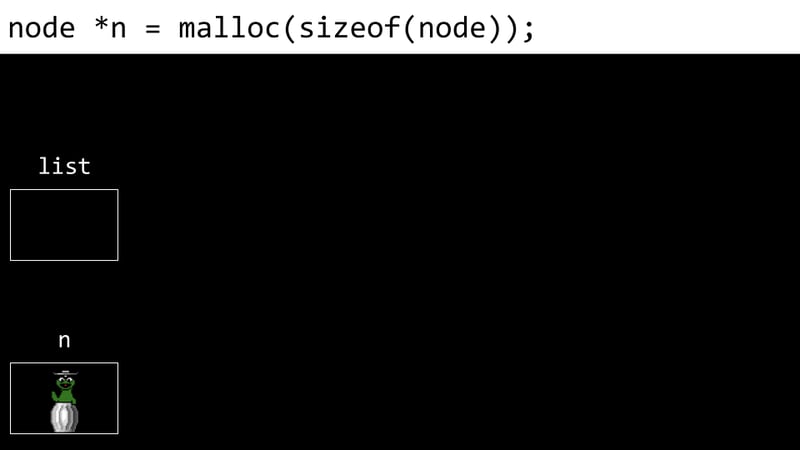

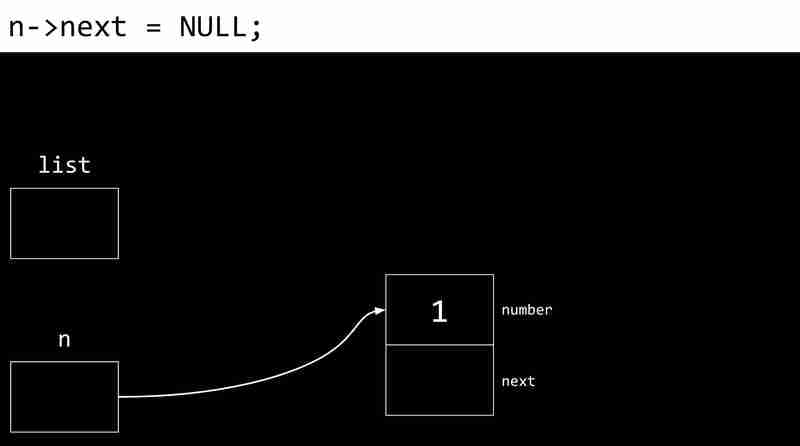
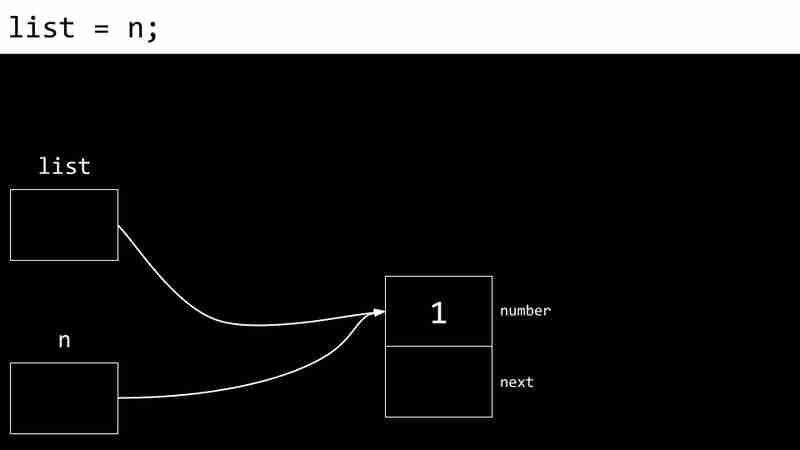
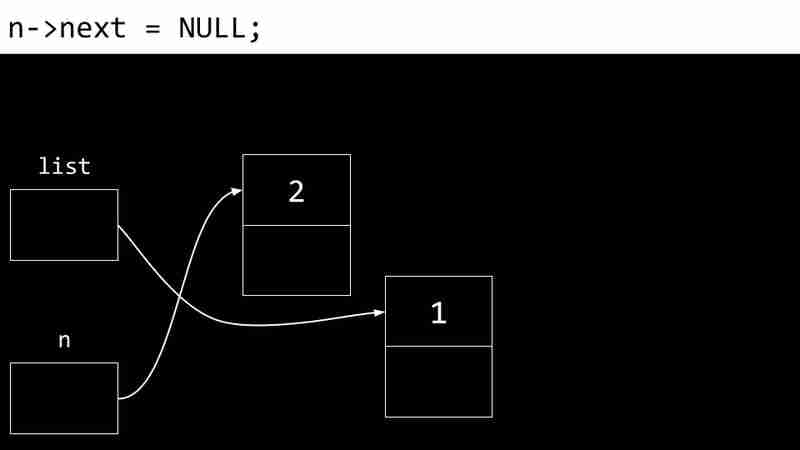
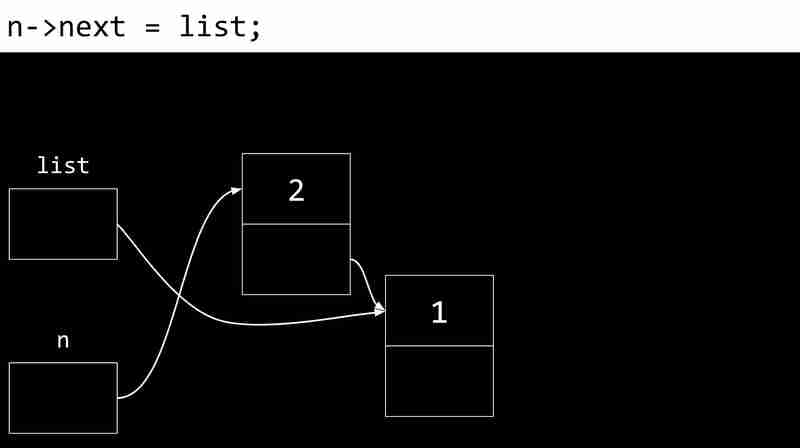

Les inconvénients des listes liées incluent la nécessité de pointeurs de stockage de mémoire supplémentaires et l'incapacité d'accès directement aux éléments via des index.
Arbre de recherche binaire (BST)
Un arbre de recherche binaire est une structure d'arbre qui stocke, recherche et récupère efficacement les données.

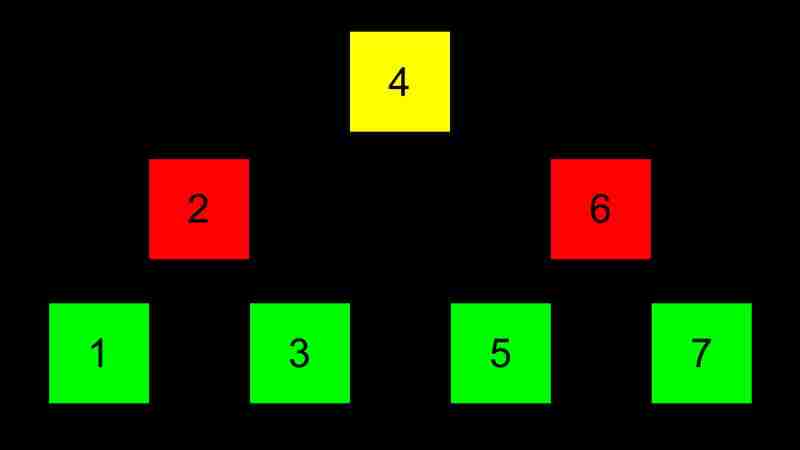
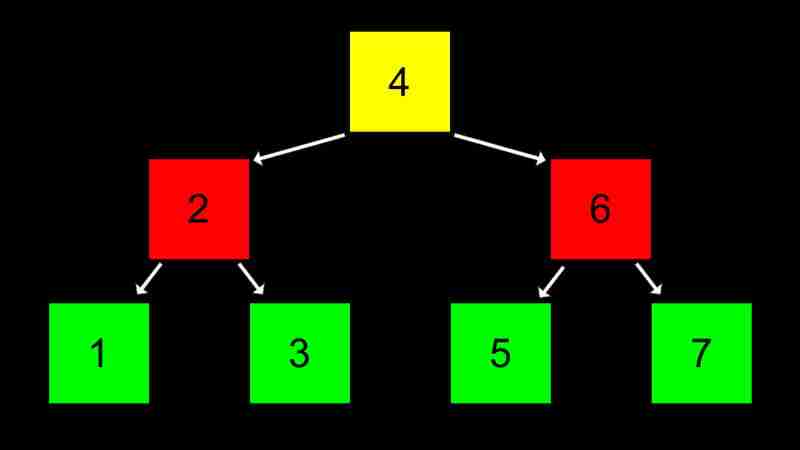
Les avantages de BST sont dynamiques et l'efficacité de recherche (O (log n)), et l'inconvénient est que l'efficacité de recherche tombe à O (n) lorsque l'arbre est déséquilibré et nécessite des pointeurs de stockage de mémoire supplémentaires.
Table de hachage
Une table de hachage est similaire à un dictionnaire et contient des paires de valeurs clés. Il utilise une fonction de hachage pour cartographier les clés pour les indices de tableau, réalisant ainsi le temps de recherche moyen de O (1).

Les conflits de hachage (plusieurs clés mappés au même indice) peuvent être résolus par des listes liées ou d'autres méthodes. La conception des fonctions de hachage est cruciale pour les performances des tables de hachage. Un exemple de fonction de hachage simple est le suivant:
<code class="c">#include <ctype.h> unsigned int hash(const char *word) { return toupper(word[0]) - 'A'; }</ctype.h></code>Cet article est compilé sur la base du code source CS50X 2024.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1664
1664
 14
1423
52
1317
25
1268
29
1248
24
14
1423
52
1317
25
1268
29
1248
24

 Quelle est la méthode de conversion des chaînes Vue.js en objets?
Apr 07, 2025 pm 09:18 PM
Quelle est la méthode de conversion des chaînes Vue.js en objets?
Apr 07, 2025 pm 09:18 PM
L'utilisation de la chaîne JSON.Parse () à l'objet est la plus sûre et la plus efficace: assurez-vous que les chaînes sont conformes aux spécifications JSON et évitez les erreurs courantes. Utilisez Try ... Catch pour gérer les exceptions pour améliorer la robustesse du code. Évitez d'utiliser la méthode EVAL (), qui présente des risques de sécurité. Pour les énormes cordes JSON, l'analyse de fouet ou l'analyse asynchrone peut être envisagée pour optimiser les performances.
 C Structure des données du langage: représentation des données et fonctionnement des arbres et des graphiques
Apr 04, 2025 am 11:18 AM
C Structure des données du langage: représentation des données et fonctionnement des arbres et des graphiques
Apr 04, 2025 am 11:18 AM
C Structure des données du langage: La représentation des données de l'arborescence et du graphique est une structure de données hiérarchique composée de nœuds. Chaque nœud contient un élément de données et un pointeur vers ses nœuds enfants. L'arbre binaire est un type spécial d'arbre. Chaque nœud a au plus deux nœuds enfants. Les données représentent StrustReenode {intdata; structTreenode * gauche; structureReode * droite;}; L'opération crée une arborescence d'arborescence arborescence (prédécision, ordre dans l'ordre et ordre ultérieur) Le nœud d'insertion de l'arborescence des arbres de recherche de nœud Graph est une collection de structures de données, où les éléments sont des sommets, et ils peuvent être connectés ensemble via des bords avec des données droites ou peu nombreuses représentant des voisins.
 La vérité derrière le problème de fonctionnement du fichier de langue C
Apr 04, 2025 am 11:24 AM
La vérité derrière le problème de fonctionnement du fichier de langue C
Apr 04, 2025 am 11:24 AM
La vérité sur les problèmes de fonctionnement des fichiers: l'ouverture des fichiers a échoué: les autorisations insuffisantes, les mauvais chemins de mauvais et les fichiers occupés. L'écriture de données a échoué: le tampon est plein, le fichier n'est pas écrivatif et l'espace disque est insuffisant. Autres FAQ: traversée de fichiers lents, encodage de fichiers texte incorrect et erreurs de lecture de fichiers binaires.
 Comment faire la distinction entre la fermeture d'un onglet de navigateur et la fermeture du navigateur entier à l'aide de JavaScript?
Apr 04, 2025 pm 10:21 PM
Comment faire la distinction entre la fermeture d'un onglet de navigateur et la fermeture du navigateur entier à l'aide de JavaScript?
Apr 04, 2025 pm 10:21 PM
Comment faire la distinction entre la fermeture des onglets et la fermeture du navigateur entier à l'aide de JavaScript sur votre navigateur? Pendant l'utilisation quotidienne du navigateur, les utilisateurs peuvent ...
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 L'URL demandée par Vue Axios est-elle correcte?
Apr 07, 2025 pm 10:12 PM
L'URL demandée par Vue Axios est-elle correcte?
Apr 07, 2025 pm 10:12 PM
Oui, l'URL demandée par Vue Axios doit être correcte pour que la demande réussisse. Le format d'URL est: Protocole, nom d'hôte, chemin de ressource, chaîne de requête facultative. Les erreurs communes incluent les protocoles manquants, les fautes d'orthographe, les objets en double, les numéros de port manquants et le format de chaîne de requête incorrect. Comment vérifier l'exactitude de l'URL: entrez manuellement dans la barre d'adresse du navigateur, utilisez l'outil de vérification en ligne ou utilisez l'option ValidateStatus de Vue Axios dans la demande.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Redis Counter est un mécanisme qui utilise le stockage de la paire de valeurs de clés Redis pour implémenter les opérations de comptage, y compris les étapes suivantes: création de clés de comptoir, augmentation du nombre, diminution du nombre, réinitialisation du nombre et objet de comptes. Les avantages des compteurs Redis comprennent une vitesse rapide, une concurrence élevée, une durabilité et une simplicité et une facilité d'utilisation. Il peut être utilisé dans des scénarios tels que le comptage d'accès aux utilisateurs, le suivi des métriques en temps réel, les scores de jeu et les classements et le comptage de traitement des commandes.
