
 base de données
tutoriel mysql
Une entreprise de services RH supérieure remplace de manière transparente son système par Bladepipe
base de données
tutoriel mysql
Une entreprise de services RH supérieure remplace de manière transparente son système par Bladepipe
Une entreprise de services RH supérieure remplace de manière transparente son système par Bladepipe

Les entreprises sont souvent confrontées à d'énormes défis dans le remplacement des systèmes, tels que la mise à niveau des systèmes de gestion des ressources humaines (SHRM), en particulier pour minimiser les temps d'arrêt. Cet article utilisera un exemple réel pour illustrer comment une société de services RH supérieure peut remplacer de manière transparente son système de SHRM par des outils de migration de données.
Architecture et exigences commerciales
La société vise à remplacer l'ancien système par un nouveau système de SHRM plus puissant. L'ancien système couvre la gestion de l'information telle que les contrats des employés, le salaire, la sécurité sociale et les bureaux. Le nouveau système doit traiter plus de données, de sorte que le stockage de données dans le système doit être reconstruit.
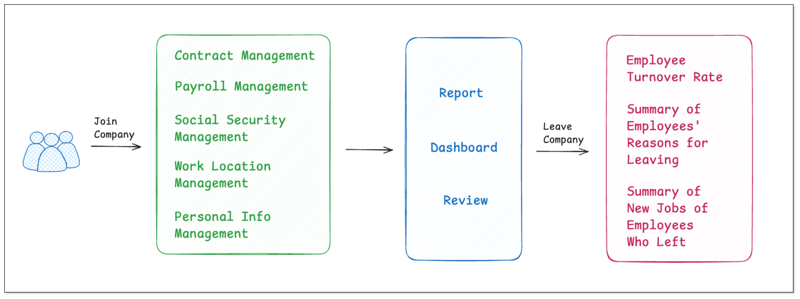
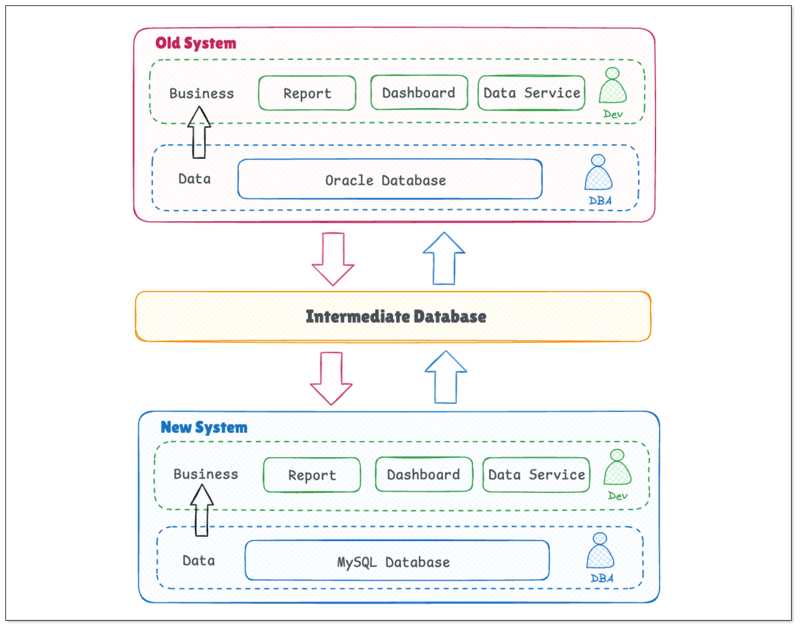
Architecture technique et stratégie de migration des données
L'ancien système est basé sur la base de données Oracle, tandis que le nouveau système utilise la base de données MySQL. Pour garantir la continuité des services RH pendant le remplacement du système et pour répondre à la complexité du réseau et aux besoins de sécurité des données, la société a intelligemment conçu une base de données Oracle intermédiaire en tant que centre d'échange de données. Cela résout le problème de la différence de structure de la base de données entre les anciens et les nouveaux systèmes.
La figure suivante montre le processus de remplacement de système sans couture:
Défis et solutions
Afin d'obtenir une transition de système fluide, la migration des données en temps réel est cruciale. Cela nécessite de construire plusieurs pipelines de données pour effectuer les tâches suivantes:
- Convertir et migrer les données du système hérité vers une base de données intermédiaire et synchroniser les données incrémentielles en temps réel.
- Migrez les données nécessaires de la base de données intermédiaire vers le nouveau système et chargez les données vers l'ancien système en temps réel.

Ce processus fait face aux défis suivants:
- Maintenir la stabilité de plusieurs pipelines de données.
- Assurer la précision de la migration des données entre les bases de données hétérogènes.
- Contrôlez le retard en quelques secondes.
Pourquoi choisir Bladepipe?
Après avoir comparé plusieurs outils de migration de données, l'entreprise a finalement choisi Bladepipe pour les principales raisons suivantes:
- Interface intuitive pour configurer les pipelines de données sans code.
- Terminez automatiquement la migration de l'architecture, la migration complète des données et la synchronisation incrémentielle des données.
- Surveillance continue et alarmes automatiques pour réduire les coûts de fonctionnement et de maintenance et la pression.
- Capacités de migration des données de la source de données hétérogènes fortes, soutenant les fonctions d'élagage, de cartographie et de filtrage des données.
- Prend en charge le code personnalisé et fournit des options de personnalisation flexibles et personnalisées.
Résultats et conclusion
La société de services RH a utilisé avec succès Bladepipe pour terminer le remplacement du système, et le nouveau système fonctionne de manière stable depuis plusieurs mois. Dans le processus de migration du système, la synchronisation des données en temps réel est cruciale. Avec sa facilité d'utilisation, ses caractéristiques puissantes et sa latence ultra-faible, Bladepipe résout efficacement le problème de migration des données, prouvant sa fiabilité et son efficacité dans le remplacement du système d'entreprise. Le choix des bons outils est essentiel pour assurer la continuité des activités et l'intégrité des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment créer Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
Comment créer Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
Les instructions SQL peuvent être créées et exécutées en fonction de l'entrée d'exécution en utilisant Dynamic SQL d'Oracle. Les étapes comprennent: la préparation d'une variable de chaîne vide pour stocker des instructions SQL générées dynamiquement. Utilisez l'instruction EXECUTER IMMÉDIATE OU PRÉPEPART pour compiler et exécuter les instructions SQL dynamiques. Utilisez la variable Bind pour passer l'entrée utilisateur ou d'autres valeurs dynamiques à Dynamic SQL. Utilisez EXECUTER immédiat ou exécuter pour exécuter des instructions SQL dynamiques.
 Comment créer des curseurs dans Oracle Loop
Apr 12, 2025 am 06:18 AM
Comment créer des curseurs dans Oracle Loop
Apr 12, 2025 am 06:18 AM
Dans Oracle, la boucle pour la boucle pour créer des curseurs dynamiquement. Les étapes sont: 1. Définissez le type de curseur; 2. Créez la boucle; 3. Créez le curseur dynamiquement; 4. Exécuter le curseur; 5. Fermez le curseur. Exemple: un curseur peut être créé de cycle par circuit pour afficher les noms et salaires des 10 meilleurs employés.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment supprimer l'échec de la bibliothèque Oracle
Apr 12, 2025 am 06:21 AM
Comment supprimer l'échec de la bibliothèque Oracle
Apr 12, 2025 am 06:21 AM
Étapes pour supprimer la base de données ratée après que Oracle a échoué à créer une bibliothèque: utilisez le nom d'utilisateur SYS pour se connecter à l'instance cible. Utilisez la base de données Drop pour supprimer la base de données. Base de données de requête V $ pour confirmer que la base de données a été supprimée.
 Comment arrêter Oracle Database
Apr 12, 2025 am 06:12 AM
Comment arrêter Oracle Database
Apr 12, 2025 am 06:12 AM
Pour arrêter une base de données Oracle, effectuez les étapes suivantes: 1. Connectez-vous à la base de données; 2. Arrêt immédiatement; 3. Arrêt About complètement.
 Comment commencer la surveillance d'Oracle
Apr 12, 2025 am 06:00 AM
Comment commencer la surveillance d'Oracle
Apr 12, 2025 am 06:00 AM
Les étapes pour démarrer un écouteur Oracle sont les suivantes: cochez l'état de l'écouteur (en utilisant la commande LSNRCTL Status) pour Windows, démarrez le service "TNS Écouteur" dans Oracle Services Manager pour Linux et Unix, utilisez la commande LSNRCTL LSNRCTL pour démarrer l'auditeur pour exécuter la commande LSNRCTL STAT
