
 Périphériques technologiques
IA
Optimisation des performances de l'IA: un guide du déploiement LLM efficace
Périphériques technologiques
IA
Optimisation des performances de l'IA: un guide du déploiement LLM efficace
Optimisation des performances de l'IA: un guide du déploiement LLM efficace

Master le modèle de grande langue (LLM) servant des applications d'IA à haute performance
La montée en puissance de l'intelligence artificielle (IA) nécessite un déploiement efficace de LLM pour une innovation et une productivité optimales. Imaginez le service client alimenté en AI anticiper vos besoins ou vos outils d'analyse de données offrant des informations instantanées. Cela nécessite la maîtrise du service LLM - transformant les LLM en applications à haute performance et en temps réel. Cet article explore une portion et un déploiement LLM efficaces, couvrant des plateformes optimales, des stratégies d'optimisation et des exemples pratiques pour créer des solutions d'IA puissantes et réactives.

Objectifs d'apprentissage clés:
- Saisissez le concept de déploiement LLM et son importance dans les applications en temps réel.
- Examinez divers cadres de service LLM, y compris leurs fonctionnalités et leurs cas d'utilisation.
- Gagnez une expérience pratique avec des exemples de code pour le déploiement de LLMS à l'aide de différents frameworks.
- Apprenez à comparer et à comparer les cadres de service LLM en fonction de la latence et du débit.
- Identifiez les scénarios idéaux pour utiliser des cadres de service LLM spécifiques dans diverses applications.
Cet article fait partie du blogathon des sciences des données.
Table des matières:
- Introduction
- Triton Inference Server: une plongée profonde
- Optimisation des modèles HuggingFace pour la génération de texte de production
- VLLM: révolutionner le traitement par lots pour les modèles de langue
- Deeppeed-MII: tirant parti de la vitesse profonde pour un déploiement LLM efficace
- OpenLLM: intégration du cadre adaptable
- Déploiement du modèle d'échelle avec Ray Serve
- Accélération de l'inférence avec Ctranslate2
- Latence et la comparaison du débit
- Conclusion
- Questions fréquemment posées
Triton Inference Server: une plongée profonde
Triton Inference Server est une plate-forme robuste pour le déploiement et la mise à l'échelle des modèles d'apprentissage automatique en production. Développé par NVIDIA, il prend en charge TensorFlow, Pytorch, ONNX et Backends personnalisés.
Caractéristiques clés:
- Gestion du modèle: chargement / déchargement dynamique, contrôle de version.
- Optimisation d'inférence: ensembles multimodèles, lots, lots dynamiques.
- Métriques et journalisation: intégration de Prometheus pour la surveillance.
- Prise en charge de l'accélérateur: support GPU, CPU et DLA.
Configuration et configuration:
La configuration de Triton peut être complexe, nécessitant une familiarité Docker et Kubernetes. Cependant, NVIDIA fournit une documentation complète et un soutien communautaire.
Cas d'utilisation:
Idéal pour les déploiements à grande échelle exigeant les performances, l'évolutivité et le support multi-trames.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)
Optimisation des modèles HuggingFace pour la génération de texte de production
Cette section se concentre sur l'utilisation de modèles HuggingFace pour la génération de texte, en mettant l'accent sur le support natif sans adaptateurs supplémentaires. Il utilise le rétrécissement du modèle pour le traitement parallèle, la mise en mémoire tampon pour la gestion des demandes et le lots pour l'efficacité. GRPC assure une communication rapide entre les composants.
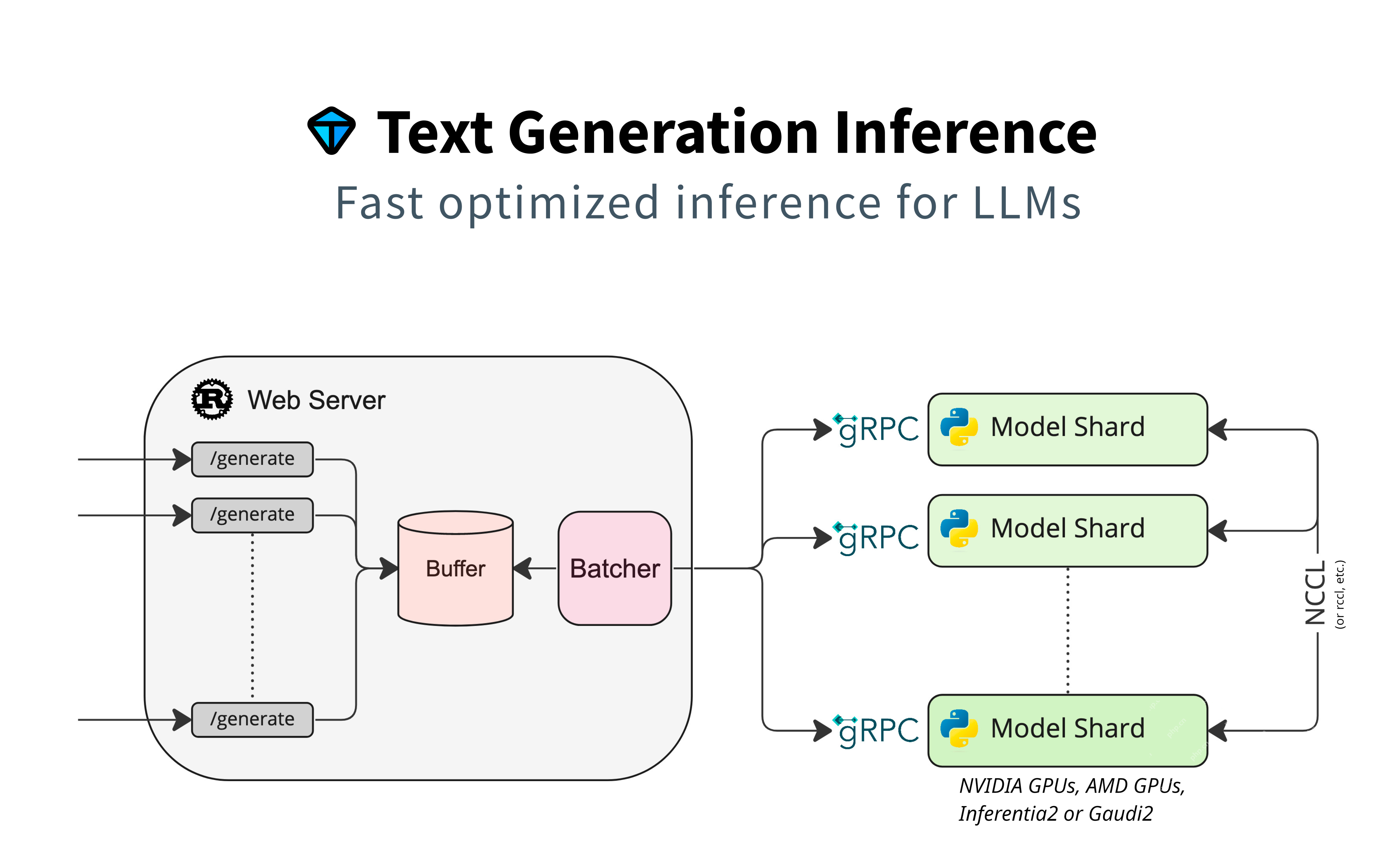
Caractéristiques clés:
- Conviviale: intégration sans faille en houblon sans couture.
- Personnalisation: permet un réglage fin et des configurations personnalisées.
- Prise en charge des transformateurs: exploite la bibliothèque Transformers.
Cas d'utilisation:
Convient pour les applications nécessitant une intégration directe du modèle HuggingFace, telles que les chatbots et la génération de contenu.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)
VLLM: révolutionner le traitement par lots pour les modèles de langue
VLLM priorise la vitesse dans la livraison rapide par lots, l'optimisation de la latence et du débit. Il utilise des opérations vectorisées et un traitement parallèle pour une génération efficace de texte par lots.

Caractéristiques clés:
- Haute performance: optimisée pour une faible latence et un débit élevé.
- Traitement par lots: Gestion efficace des demandes par lots.
- Évolutivité: Convient pour les déploiements à grande échelle.
Cas d'utilisation:
Meilleur pour les applications critiques de vitesse, telles que la traduction en temps réel et les systèmes d'IA interactifs.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)
Deeppeed-MII: exploitation profonde pour un déploiement LLM efficace
Deeppeed-MII est destiné aux utilisateurs expérimentés avec Deeppeed, en se concentrant sur le déploiement efficace de LLM et la mise à l'échelle par le parallélisme du modèle, l'efficacité de la mémoire et l'optimisation de la vitesse.

Caractéristiques clés:
- Efficacité: mémoire et efficacité de calcul.
- Évolutivité: gère les très grands modèles.
- Intégration: sans couture avec des flux de travail profonds.
Cas d'utilisation:
Idéal pour les chercheurs et les développeurs familiers avec Deeppeed, la priorisation de la formation et du déploiement à haute performance.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)
OpenLLM: intégration d'adaptateur flexible
OpenLLM connecte les adaptateurs au modèle de base et utilise des agents HuggingFace. Il prend en charge plusieurs frameworks, y compris Pytorch.
Caractéristiques clés:
- Framework Agnostic: prend en charge plusieurs cadres d'apprentissage en profondeur.
- Intégration de l'agent: exploite les agents de la surface des câlins.
- Prise en charge de l'adaptateur: intégration flexible avec les adaptateurs du modèle.
Cas d'utilisation:
Idéal pour les projets nécessitant une flexibilité du cadre et une utilisation étendue de l'outil de câlins.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)

Tirer parti des rayons servir pour le déploiement du modèle évolutif
Ray Service fournit un pipeline stable et un déploiement flexible pour des projets matures nécessitant des solutions fiables et évolutives.
Caractéristiques clés:
- Flexibilité: prend en charge plusieurs architectures de déploiement.
- Évolutivité: gère les applications à charge élevée.
- Intégration: fonctionne bien avec l'écosystème de Ray.
Cas d'utilisation:
Idéal pour les projets établis nécessitant une infrastructure de service robuste et évolutive.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)
Accélérer l'inférence avec Ctranslate2
CTRANSLATE2 priorise la vitesse, en particulier pour l'inférence basée sur le processeur. Il est optimisé pour les modèles de traduction et prend en charge diverses architectures.
Caractéristiques clés:
- Optimisation du processeur: haute performance pour l'inférence du CPU.
- Compatibilité: prend en charge les architectures de modèle populaires.
- Léger: dépendances minimales.
Cas d'utilisation:
Convient pour les applications priorisant la vitesse et l'efficacité du processeur, telles que les services de traduction.
Code de démonstration et explication: (Le code reste le même que dans l'entrée d'origine)

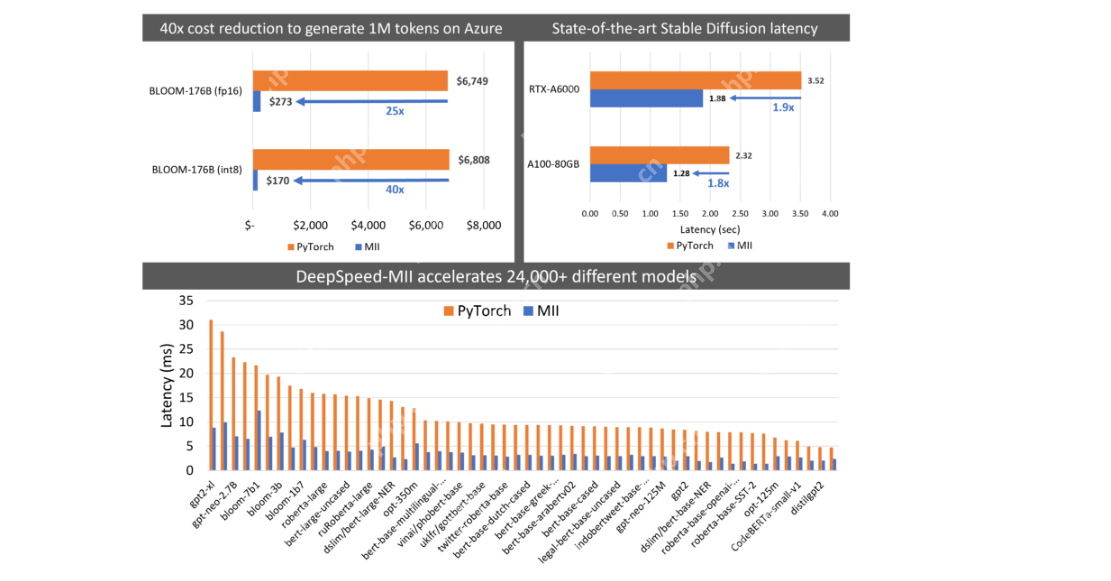
Latence et la comparaison du débit
(La table et l'image comparant la latence et le débit restent les mêmes que dans l'entrée d'origine)
Conclusion
La portion LLM efficace est cruciale pour les applications d'IA réactives. Cet article a exploré diverses plateformes, chacune avec des avantages uniques. Le meilleur choix dépend des besoins spécifiques.
Les principaux plats à retenir:
- Le service de modèle déploie des modèles formés pour l'inférence.
- Différentes plates-formes excellent dans différents aspects de performance.
- La sélection du cadre dépend du cas d'utilisation.
- Certains cadres sont meilleurs pour les déploiements évolutifs dans des projets matures.
Questions fréquemment posées:
(Les FAQ restent les mêmes que dans l'entrée d'origine)
Remarque: Les médias présentés dans cet article ne sont pas détenus par [mentionner l'entité pertinente] et est utilisé à la discrétion de l'auteur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
L'article passe en revue les meilleurs générateurs d'art AI, discutant de leurs fonctionnalités, de leur aptitude aux projets créatifs et de la valeur. Il met en évidence MidJourney comme la meilleure valeur pour les professionnels et recommande Dall-E 2 pour un art personnalisable de haute qualité.
 Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Début avec Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
META'S LLAMA 3.2: un bond en avant dans l'IA multimodal et mobile Meta a récemment dévoilé Llama 3.2, une progression importante de l'IA avec de puissantes capacités de vision et des modèles de texte légers optimisés pour les appareils mobiles. S'appuyer sur le succès o
 Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
Meilleurs chatbots AI comparés (Chatgpt, Gemini, Claude & amp; plus)
Apr 02, 2025 pm 06:09 PM
L'article compare les meilleurs chatbots d'IA comme Chatgpt, Gemini et Claude, en se concentrant sur leurs fonctionnalités uniques, leurs options de personnalisation et leurs performances dans le traitement et la fiabilité du langage naturel.
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
 Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
Assistants d'écriture de l'IA pour augmenter votre création de contenu
Apr 02, 2025 pm 06:11 PM
L'article traite des meilleurs assistants d'écriture d'IA comme Grammarly, Jasper, Copy.ai, WireSonic et Rytr, en se concentrant sur leurs fonctionnalités uniques pour la création de contenu. Il soutient que Jasper excelle dans l'optimisation du référencement, tandis que les outils d'IA aident à maintenir le ton
 Top 7 Système de chiffon agentique pour construire des agents d'IA
Mar 31, 2025 pm 04:25 PM
Top 7 Système de chiffon agentique pour construire des agents d'IA
Mar 31, 2025 pm 04:25 PM
2024 a été témoin d'un simple passage de l'utilisation des LLM pour la génération de contenu pour comprendre leur fonctionnement intérieur. Cette exploration a conduit à la découverte des agents de l'IA - les systèmes autonomes manipulant des tâches et des décisions avec une intervention humaine minimale. Construire
 Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
Choisir le meilleur générateur de voix d'IA: les meilleures options examinées
Apr 02, 2025 pm 06:12 PM
L'article examine les meilleurs générateurs de voix d'IA comme Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson et Descript, en se concentrant sur leurs fonctionnalités, leur qualité vocale et leur aptitude à différents besoins.
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de Shopify
Apr 10, 2025 am 11:19 AM
La récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
