

ExtJS中文乱码之GBK格式编码解决方案及代码_extjs

这几天做后台看了一些Ext的知识,在切入工作项目的时候出现了乱码情况,所以就总结了这篇ExtJS中文乱码之GBK格式编码解决办法的文章,作为记录。
1、具体情况:
在引入:
02.
03.
04.
05.
后,写了一个简单的例子:
结果出现:
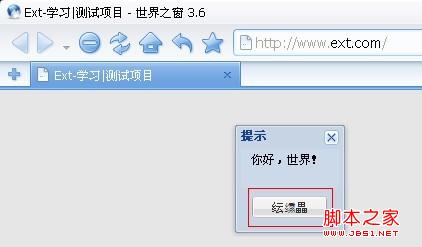
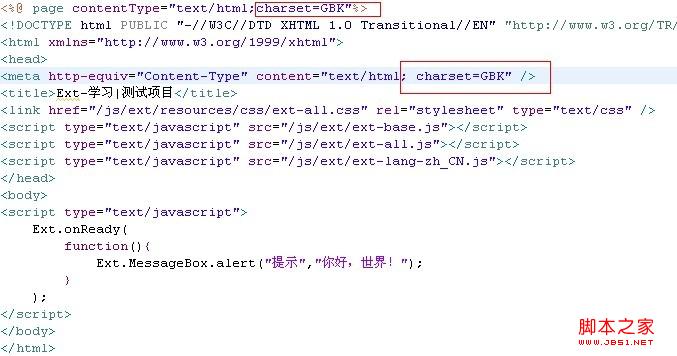
2、页面的编码是GBK,具体代码如下:
3、解决办法:
(1)把页面的编码定义为UFT-8后正常,但项目指定编码是UTF-8,所以不能采用这个思路。
(2)把引入的资源文件(/js/ext/ext-lang-zh_CN.js)改变为合适的编码,具体如下:
A 、用EditPlus打开这个js文件,选择另存为,如下图:
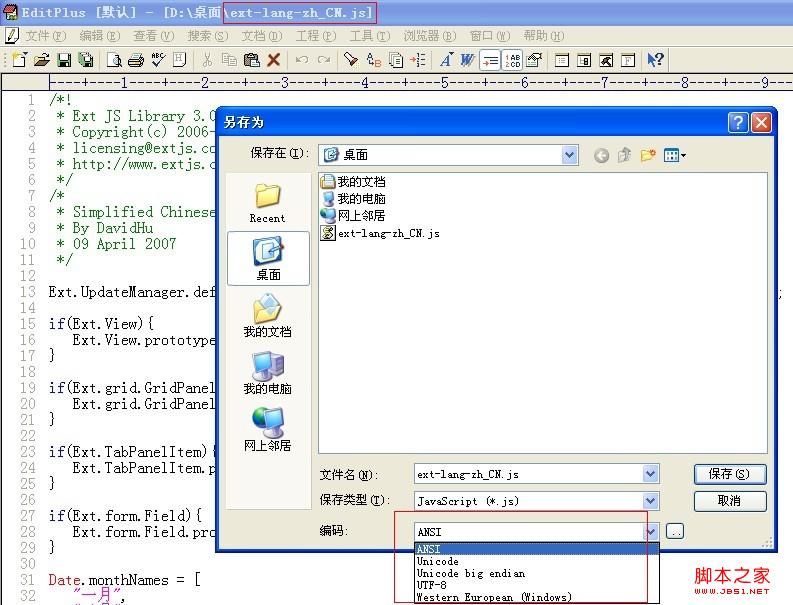
B、可以看到编码选项一共有5项,但是都不是我们需要的,我们点击后面的 更多的小按钮(上面有两个点的不起眼的哪个按钮)
看到下图后,选择图中的编码并确认:

然后,替换工程里面的js,再测试:
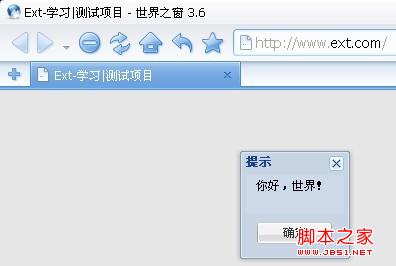
可以看到,乱码问题已经解决,文字显示正常了。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes pour résoudre le problème des caractères chinois tronqués en PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Méthodes pour résoudre le problème des caractères chinois tronqués en PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Méthodes pour résoudre le problème chinois tronqué de PHPDompdf PHPDompdf est un outil de conversion de documents HTML en fichiers PDF. Il est puissant et facile à utiliser. Cependant, lors du traitement du contenu chinois, vous rencontrez parfois le problème des caractères chinois tronqués. Cet article présentera quelques méthodes pour résoudre le problème des caractères chinois tronqués dans PHPDompdf et fournira des exemples de code spécifiques. 1. Lors de l'utilisation de fichiers de polices pour traiter du contenu chinois, un problème courant est que Dompdf ne prend pas en charge le contenu chinois par défaut.
 11 techniques courantes d'encodage des caractéristiques de classification
Apr 12, 2023 pm 12:16 PM
11 techniques courantes d'encodage des caractéristiques de classification
Apr 12, 2023 pm 12:16 PM
Les algorithmes d'apprentissage automatique n'acceptent que les entrées numériques, donc si nous rencontrons des caractéristiques catégorielles, nous coderons les caractéristiques catégorielles. Cet article résume 11 méthodes courantes de codage de variables catégorielles. 1. ONE HOT ENCODING La méthode d’encodage la plus populaire et la plus couramment utilisée est One Hot Enoding. Une unique variable à n observations et d valeurs distinctes est convertie en d variables binaires à n observations, chaque variable binaire est identifiée par un bit (0, 1). Par exemple : l'implémentation la plus simple après l'encodage consiste à utiliser get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2 de pandas,
 Combien d'octets les caractères chinois codés en utf8 occupent-ils ?
Feb 21, 2023 am 11:40 AM
Combien d'octets les caractères chinois codés en utf8 occupent-ils ?
Feb 21, 2023 am 11:40 AM
Les caractères chinois codés en UTF8 occupent 3 octets. En codage UTF-8, un caractère chinois équivaut à trois octets et un signe de ponctuation chinois occupe trois octets, tandis qu'en codage Unicode, un caractère chinois (y compris le chinois traditionnel) équivaut à deux octets. UTF-8 utilise 1 à 4 octets pour coder chaque caractère. Un caractère US-ASCIl n'a besoin que de 1 octet pour coder. Le latin, le grec, le cyrillique, l'arménien et l'hébreu avec des signes diacritiques, l'arabe, le syriaque et d'autres lettres nécessitent 2 octets. codage.
 La solution ultime au problème des caractères chinois tronqués dans PyCharm
Jan 27, 2024 am 08:00 AM
La solution ultime au problème des caractères chinois tronqués dans PyCharm
Jan 27, 2024 am 08:00 AM
La méthode ultime pour résoudre le problème des caractères chinois tronqués dans PyCharm nécessite des exemples de code spécifiques Introduction : PyCharm, en tant qu'environnement de développement intégré (IDE) Python couramment utilisé, possède des fonctions puissantes et une interface utilisateur conviviale, et est apprécié et utilisé par les utilisateurs. majorité des développeurs. Cependant, lorsque PyCharm traite des caractères chinois, il peut parfois rencontrer des caractères tronqués, ce qui provoque certains problèmes de développement et de débogage. Cet article explique comment résoudre le problème du chinois tronqué dans PyCharm et donne des exemples de code spécifiques. 1. Mettre en place le projet
 Causes courantes et solutions aux caractères chinois tronqués dans l'installation de MySQL
Mar 02, 2024 am 09:00 AM
Causes courantes et solutions aux caractères chinois tronqués dans l'installation de MySQL
Mar 02, 2024 am 09:00 AM
Raisons et solutions courantes pour les caractères chinois tronqués dans l'installation de MySQL MySQL est un système de gestion de base de données relationnelle couramment utilisé, mais vous pouvez rencontrer le problème des caractères chinois tronqués lors de l'utilisation, ce qui pose des problèmes aux développeurs et aux administrateurs système. Le problème des caractères chinois tronqués est principalement dû à des paramètres de jeu de caractères incorrects, à des jeux de caractères incohérents entre le serveur de base de données et le client, etc. Cet article présentera en détail les causes courantes et les solutions des caractères chinois tronqués dans l'installation de MySQL pour aider tout le monde à mieux résoudre ce problème. 1. Raisons courantes : paramètre du jeu de caractères
 Knowledge graph : le partenaire idéal des grands modèles
Jan 29, 2024 am 09:21 AM
Knowledge graph : le partenaire idéal des grands modèles
Jan 29, 2024 am 09:21 AM
Les grands modèles linguistiques (LLM) ont la capacité de générer un texte fluide et cohérent, ouvrant de nouvelles perspectives dans des domaines tels que la conversation par intelligence artificielle et l'écriture créative. Cependant, le LLM présente également certaines limites clés. Premièrement, leurs connaissances se limitent aux modèles reconnus à partir des données de formation, sans une véritable compréhension du monde. Deuxièmement, les capacités de raisonnement sont limitées et ne peuvent pas faire de déductions logiques ni fusionner des faits provenant de plusieurs sources de données. Face à des questions plus complexes et ouvertes, les réponses de LLM peuvent devenir absurdes ou contradictoires, ce que l'on appelle des « illusions ». Par conséquent, bien que le LLM soit très utile à certains égards, il présente néanmoins certaines limites lorsqu’il s’agit de problèmes complexes et de situations du monde réel. Afin de combler ces lacunes, des systèmes de génération augmentée par récupération (RAG) ont vu le jour ces dernières années.
 Que faire si ajax transmet des caractères chinois tronqués
Nov 15, 2023 am 10:42 AM
Que faire si ajax transmet des caractères chinois tronqués
Nov 15, 2023 am 10:42 AM
Solutions pour qu'Ajax transmette des caractères chinois tronqués : 1. Définir une méthode de codage unifiée ; 2. Codage côté serveur ; 3. Décodage côté client ; 4. Définir les en-têtes de réponse HTTP ; Introduction détaillée : 1. Définissez une méthode de codage unifiée pour garantir que le serveur et le client utilisent la même méthode de codage. Dans des circonstances normales, UTF-8 est une méthode de codage couramment utilisée car elle peut prendre en charge plusieurs langues et jeux de caractères ; 2, Codage côté serveur. Côté serveur, assurez-vous que les données chinoises sont codées selon la méthode de codage correcte, puis transmises au client, etc.
 Plusieurs méthodes de codage courantes
Oct 24, 2023 am 10:09 AM
Plusieurs méthodes de codage courantes
Oct 24, 2023 am 10:09 AM
Les méthodes de codage courantes incluent le codage ASCII, le codage Unicode, le codage UTF-8, le codage UTF-16, le codage GBK, etc. Introduction détaillée : 1. Le codage ASCII est la première norme de codage de caractères, utilisant des nombres binaires de 7 bits pour représenter 128 caractères, y compris des lettres anglaises, des chiffres, des signes de ponctuation, des caractères de contrôle, etc. 2. Le codage Unicode est une méthode utilisée pour représenter ; tous les caractères du monde La méthode d'encodage standard des caractères, qui attribue un point de code numérique unique à chaque caractère 3. Encodage UTF-8, etc.
