

javascript图像处理—仿射变换深度理解_javascript技巧

上一篇文章,我们讲解了图像金字塔,这篇文章我们来了解仿射变换。
仿射?
任何仿射变换都可以转换成,乘以一个矩阵(线性变化),再加上一个向量(平移变化)。
实际上仿射是两幅图片的变换关系。
例如我们可以通过仿射变换对图片进行:缩放、旋转、平移等操作。
一个数学问题
在解决仿射问题前,我们来做一个数学题。
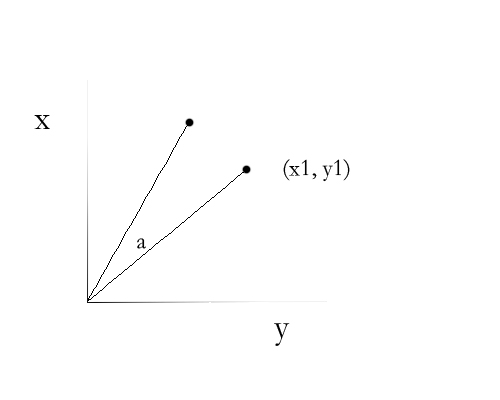
如图,对于点(x1, y1),相对于原点旋转一个角度a,那么这个点到哪里了呢?
我们将坐标系变成极坐标系,则点(x1, y1)就变成了(r, β),而旋转后变成(r, α+ β)。
转回直角坐标系,则旋转后的点变成了(cos(α+ β) * r, sin(α+ β) * r)。
然后利用公式:
cos(α+β)=cosαcosβ-sinαsinβ
sin(α+β)=sinαcosβ+cosαsinβ
以及原来点为(cosβ * r, sinβ * r),于是很容易得出新的点为(x1 * cosα - y1 * sinα, x1 * sinaα + y1 * cosα)。
我们可以从中推导出旋转变换公式:
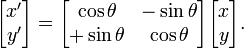
那么平移就相对简单很多了,就相当于加上一个向量(c, d)就行了。
获得变换矩阵函数实现
通常我们使用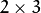 矩阵来表示仿射变换。
矩阵来表示仿射变换。
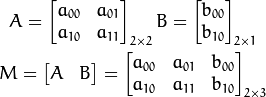
其中A是旋转缩放变换,B是平移变换。则结果T满足:
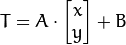 或者
或者
![T = M \cdot [x, y, 1]^{T}](http://files.jb51.net/file_images/article/201301/201301160852597.png)
即: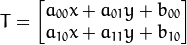
var getRotationArray2D = function(__angle, __x, __y){
var sin = Math.sin(__angle) || 0,
cos = Math.cos(__angle) || 1,
x = __x || 0,
y = __y || 0;
return [cos, -sin, -x,
sin, cos, -y
];
};
这样我们就得到了一个仿射变换矩阵。
当然这个实现本身是有一定问题的,因为这个原点被固定在左上角了。
仿射变换实现
var warpAffine = function(__src, __rotArray, __dst){
(__src && __rotArray) || error(arguments.callee, IS_UNDEFINED_OR_NULL/* {line} */);
if(__src.type && __src.type === "CV_RGBA"){
var height = __src.row,
width = __src.col,
dst = __dst || new Mat(height, width, CV_RGBA),
sData = new Uint32Array(__src.buffer),
dData = new Uint32Array(dst.buffer);
var i, j, xs, ys, x, y, nowPix;
for(j = 0, nowPix = 0; j xs = __rotArray[1] * j + __rotArray[2];
ys = __rotArray[4] * j + __rotArray[5];
for(i = 0; i
if(xs > 0 && ys > 0 && xs
y = ys | 0;
x = xs | 0;
dData[nowPix] = sData[y * width + x];
}else{
dData[nowPix] = 4278190080; //Black
}
}
}
}else{
error(arguments.callee, UNSPPORT_DATA_TYPE/* {line} */);
}
return dst;
};
这个函数先把矩阵数据变成32位形式,操作每个元素就等同于操作每一个像素。
然后遍历所有元素,对对应的点进行赋值。
效果


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment la distance de Wasserstein est-elle utilisée dans les tâches de traitement d'images ?
Jan 23, 2024 am 10:39 AM
Comment la distance de Wasserstein est-elle utilisée dans les tâches de traitement d'images ?
Jan 23, 2024 am 10:39 AM
La distance de Wasserstein, également connue sous le nom de distance de EarthMover (EMD), est une mesure utilisée pour mesurer la différence entre deux distributions de probabilité. Par rapport à la divergence KL ou à la divergence JS traditionnelle, la distance de Wasserstein prend en compte les informations structurelles entre les distributions et présente donc de meilleures performances dans de nombreuses tâches de traitement d'image. En calculant le coût minimum de transport entre deux distributions, la distance de Wasserstein permet de mesurer la quantité minimale de travail nécessaire pour transformer une distribution en une autre. Cette métrique est capable de capturer les différences géométriques entre les distributions, jouant ainsi un rôle important dans des tâches telles que la génération d'images et le transfert de style. Par conséquent, la distance de Wasserstein devient le concept
 Analyse approfondie des principes de fonctionnement et des caractéristiques du modèle Vision Transformer (VIT)
Jan 23, 2024 am 08:30 AM
Analyse approfondie des principes de fonctionnement et des caractéristiques du modèle Vision Transformer (VIT)
Jan 23, 2024 am 08:30 AM
VisionTransformer (VIT) est un modèle de classification d'images basé sur Transformer proposé par Google. Contrairement aux modèles CNN traditionnels, VIT représente les images sous forme de séquences et apprend la structure de l'image en prédisant l'étiquette de classe de l'image. Pour y parvenir, VIT divise l'image d'entrée en plusieurs patchs et concatène les pixels de chaque patch via des canaux, puis effectue une projection linéaire pour obtenir les dimensions d'entrée souhaitées. Enfin, chaque patch est aplati en un seul vecteur, formant la séquence d'entrée. Grâce au mécanisme d'auto-attention de Transformer, VIT est capable de capturer la relation entre les différents correctifs et d'effectuer une extraction efficace des fonctionnalités et une prédiction de classification. Cette représentation d'image sérialisée est
 Comment utiliser la technologie IA pour restaurer d'anciennes photos (avec exemples et analyse de code)
Jan 24, 2024 pm 09:57 PM
Comment utiliser la technologie IA pour restaurer d'anciennes photos (avec exemples et analyse de code)
Jan 24, 2024 pm 09:57 PM
La restauration de photos anciennes est une méthode d'utilisation de la technologie de l'intelligence artificielle pour réparer, améliorer et améliorer de vieilles photos. Grâce à des algorithmes de vision par ordinateur et d’apprentissage automatique, la technologie peut identifier et réparer automatiquement les dommages et les imperfections des anciennes photos, les rendant ainsi plus claires, plus naturelles et plus réalistes. Les principes techniques de la restauration de photos anciennes incluent principalement les aspects suivants : 1. Débruitage et amélioration de l'image Lors de la restauration de photos anciennes, elles doivent d'abord être débruitées et améliorées. Des algorithmes et des filtres de traitement d'image, tels que le filtrage moyen, le filtrage gaussien, le filtrage bilatéral, etc., peuvent être utilisés pour résoudre les problèmes de bruit et de taches de couleur, améliorant ainsi la qualité des photos. 2. Restauration et réparation d'images Les anciennes photos peuvent présenter certains défauts et dommages, tels que des rayures, des fissures, une décoloration, etc. Ces problèmes peuvent être résolus par des algorithmes de restauration et de réparation d’images
 Application de la technologie de l'IA à la reconstruction d'images en super-résolution
Jan 23, 2024 am 08:06 AM
Application de la technologie de l'IA à la reconstruction d'images en super-résolution
Jan 23, 2024 am 08:06 AM
La reconstruction d'images en super-résolution est le processus de génération d'images haute résolution à partir d'images basse résolution à l'aide de techniques d'apprentissage en profondeur, telles que les réseaux neuronaux convolutifs (CNN) et les réseaux contradictoires génératifs (GAN). Le but de cette méthode est d'améliorer la qualité et les détails des images en convertissant des images basse résolution en images haute résolution. Cette technologie trouve de nombreuses applications dans de nombreux domaines, comme l’imagerie médicale, les caméras de surveillance, les images satellites, etc. Grâce à la reconstruction d’images en super-résolution, nous pouvons obtenir des images plus claires et plus détaillées, ce qui permet d’analyser et d’identifier plus précisément les cibles et les caractéristiques des images. Méthodes de reconstruction Les méthodes de reconstruction d'images en super-résolution peuvent généralement être divisées en deux catégories : les méthodes basées sur l'interpolation et les méthodes basées sur l'apprentissage profond. 1) Méthode basée sur l'interpolation Reconstruction d'images en super-résolution basée sur l'interpolation
 Développement Java : comment implémenter la reconnaissance et le traitement d'images
Sep 21, 2023 am 08:39 AM
Développement Java : comment implémenter la reconnaissance et le traitement d'images
Sep 21, 2023 am 08:39 AM
Développement Java : Un guide pratique sur la reconnaissance et le traitement d'images Résumé : Avec le développement rapide de la vision par ordinateur et de l'intelligence artificielle, la reconnaissance et le traitement d'images jouent un rôle important dans divers domaines. Cet article expliquera comment utiliser le langage Java pour implémenter la reconnaissance et le traitement d'images, et fournira des exemples de code spécifiques. 1. Principes de base de la reconnaissance d'images La reconnaissance d'images fait référence à l'utilisation de la technologie informatique pour analyser et comprendre des images afin d'identifier des objets, des caractéristiques ou du contenu dans l'image. Avant d'effectuer la reconnaissance d'image, nous devons comprendre certaines techniques de base de traitement d'image, comme le montre la figure
 Notes d'étude PHP : reconnaissance faciale et traitement d'images
Oct 08, 2023 am 11:33 AM
Notes d'étude PHP : reconnaissance faciale et traitement d'images
Oct 08, 2023 am 11:33 AM
Notes d'étude PHP : Reconnaissance faciale et traitement d'images Préface : Avec le développement de la technologie de l'intelligence artificielle, la reconnaissance faciale et le traitement d'images sont devenus des sujets brûlants. Dans les applications pratiques, la reconnaissance faciale et le traitement d'images sont principalement utilisés dans la surveillance de la sécurité, le déverrouillage facial, la comparaison de cartes, etc. En tant que langage de script côté serveur couramment utilisé, PHP peut également être utilisé pour implémenter des fonctions liées à la reconnaissance faciale et au traitement d'images. Cet article vous présentera la reconnaissance faciale et le traitement d'images en PHP, avec des exemples de code spécifiques. 1. Reconnaissance faciale en PHP La reconnaissance faciale est un
 Comment gérer les problèmes de traitement d'image et de conception d'interface graphique dans le développement C#
Oct 08, 2023 pm 07:06 PM
Comment gérer les problèmes de traitement d'image et de conception d'interface graphique dans le développement C#
Oct 08, 2023 pm 07:06 PM
Comment gérer les problèmes de traitement d'image et de conception d'interface graphique dans le développement C# nécessite des exemples de code spécifiques Introduction : Dans le développement de logiciels modernes, le traitement d'image et la conception d'interface graphique sont des exigences courantes. En tant que langage de programmation généraliste de haut niveau, C# possède de puissantes capacités de traitement d’images et de conception d’interface graphique. Cet article sera basé sur C#, expliquera comment gérer les problèmes de traitement d'image et de conception d'interface graphique, et donnera des exemples de code détaillés. 1. Problèmes de traitement d'image : Lecture et affichage d'images : En C#, la lecture et l'affichage d'images sont des opérations de base. Peut être utilisé.N
 Algorithme SIFT (Scale Invariant Features)
Jan 22, 2024 pm 05:09 PM
Algorithme SIFT (Scale Invariant Features)
Jan 22, 2024 pm 05:09 PM
L'algorithme SIFT (Scale Invariant Feature Transform) est un algorithme d'extraction de caractéristiques utilisé dans les domaines du traitement d'images et de la vision par ordinateur. Cet algorithme a été proposé en 1999 pour améliorer les performances de reconnaissance et de correspondance d'objets dans les systèmes de vision par ordinateur. L'algorithme SIFT est robuste et précis et est largement utilisé dans la reconnaissance d'images, la reconstruction tridimensionnelle, la détection de cibles, le suivi vidéo et d'autres domaines. Il obtient l'invariance d'échelle en détectant les points clés dans plusieurs espaces d'échelle et en extrayant des descripteurs de caractéristiques locales autour des points clés. Les principales étapes de l'algorithme SIFT comprennent la construction d'un espace d'échelle, la détection des points clés, le positionnement des points clés, l'attribution de directions et la génération de descripteurs de caractéristiques. Grâce à ces étapes, l’algorithme SIFT peut extraire des fonctionnalités robustes et uniques, permettant ainsi un traitement d’image efficace.
