

高性能Javascript笔记 数据的存储与访问性能优化_javascript技巧

局部变量也就可以理解为在函数内部定义的变量,很明显访问局部变量要比域外的变量要快,因为它位于作用域链的第一个变量对象中(关于作用域链的介绍可以阅读这篇文章)。变量在作用域链的位置越深,访问所需要的时间就越长,全局变量总是最慢的,因为它们位于作用域链的最后一个变量对象。
每种数据类型的访问都需要付出点性能代价,对于直接量和局部变量基本都能消费得起,而访问数组项和对象成员则要代价高点。下图显示了不同浏览器,分别对这四种数据类型进行了200'000次操作所用的时间。
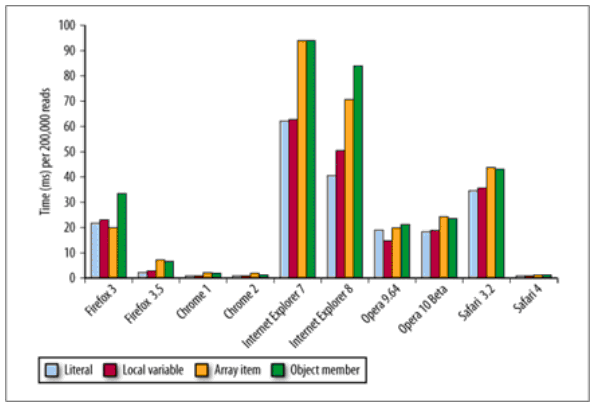
首先我们需要了解一下对象成员的访问过程。其实函数就是一个特殊的对象,所以对象成员的访问跟函数的内部变量的访问都差不多,都是基于链的查找,前者是原型链,后者是作用域链,只是怎么个链法有点差别而已。
对象成员包含属性和方法,如果该成员是一个函数就称为方法,否则就称为属性。
JavaScript中的对象是基于原形(原形本身就是一个对象)的,原形是其他对象的基础。当你实例化一个Object对象或其它JS的内置对象时(var obj=new Object() or var obj={}),实例obj的原形由后台自动创建,浏览器FF,safari,Chrome可通过obj.__proto__属性(等同于 Object.prototype)可以访问到这个原形,也正是因为这个原形,每一个实例都能共享原形对象的成员。如:
var book = {
name:"Javascript Book",
getName = function(){
return this.name;
}
};
alert(book.toString()); //"[object Object]"
此代码中,book对象有两个私有成员,分别是属性name和方法getName。book对象并没有定义成员toString,但调用了也没有抛出错误,原因是book对象继承了原形对象的成员。book对象与原形的关系如下:

对象的另一高级用法就是模拟类和继承类,我喜欢叫这样用法的对象为对象类。继承对象类主要就是依靠原型链来完成的,这个知识点太多需要另外详细 说明。通过上面的对象成员搜索过程,访问对象成员的速度,随着原型链的越深,搜索的速度就越慢。下图就显示了对象成员在原型链中所处的深度与访问时间的关 系:
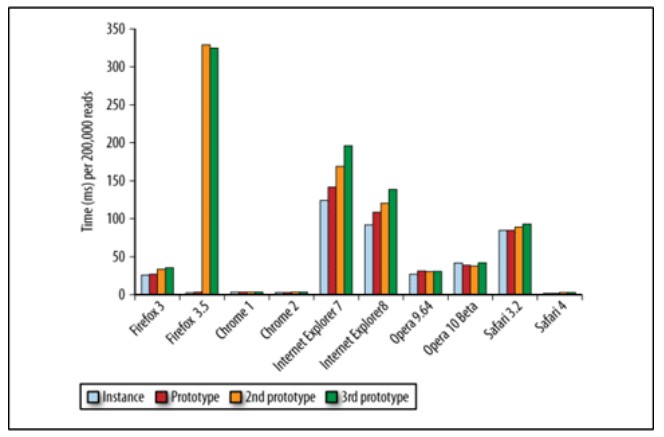
好了,总结起来就一句话:一个属性或方法在原型链的位置越深,访问它的速度就越慢。解决办法就是:将经常使用的对象成员,数组项和域外的变量存入局部变量中,然后访问这个局部变量。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Pourquoi le stockage local ne parvient-il pas à sauvegarder les données ?
Jan 03, 2024 pm 01:41 PM
Pourquoi le stockage local ne parvient-il pas à sauvegarder les données ?
Jan 03, 2024 pm 01:41 PM
Pourquoi le stockage des données sur le stockage local échoue-t-il toujours ? Besoin d'exemples de code spécifiques Dans le développement front-end, nous avons souvent besoin de stocker des données côté navigateur pour améliorer l'expérience utilisateur et faciliter l'accès ultérieur aux données. Localstorage est une technologie fournie par HTML5 pour le stockage de données côté client. Elle fournit un moyen simple de stocker des données et de maintenir la persistance des données après l'actualisation ou la fermeture de la page. Cependant, lorsque nous utilisons le stockage local pour le stockage de données, parfois
 Comment implémenter le stockage polymorphe et l'interrogation multidimensionnelle des données dans MySQL ?
Jul 31, 2023 pm 09:12 PM
Comment implémenter le stockage polymorphe et l'interrogation multidimensionnelle des données dans MySQL ?
Jul 31, 2023 pm 09:12 PM
Comment implémenter le stockage polymorphe et l'interrogation multidimensionnelle des données dans MySQL ? Dans le développement d'applications pratiques, le stockage polymorphe et l'interrogation multidimensionnelle des données sont une exigence très courante. En tant que système de gestion de bases de données relationnelles couramment utilisé, MySQL offre diverses façons d'implémenter le stockage polymorphe et les requêtes multidimensionnelles. Cet article présentera la méthode d'utilisation de MySQL pour implémenter le stockage polymorphe et l'interrogation multidimensionnelle des données, et fournira des exemples de code correspondants pour aider les lecteurs à les comprendre et à les utiliser rapidement. 1. Stockage polymorphe Le stockage polymorphe fait référence à la technologie permettant de stocker différents types de données dans le même champ.
 Comment implémenter les fonctions de stockage d'images et de traitement des données dans MongoDB
Sep 22, 2023 am 10:30 AM
Comment implémenter les fonctions de stockage d'images et de traitement des données dans MongoDB
Sep 22, 2023 am 10:30 AM
Aperçu de la façon d'implémenter les fonctions de stockage d'images et de traitement des données dans MongoDB : dans le développement d'applications de données modernes, le traitement et le stockage d'images sont une exigence courante. MongoDB, une base de données NoSQL populaire, fournit des fonctionnalités et des outils qui permettent aux développeurs d'implémenter le stockage et le traitement d'images sur sa plateforme. Cet article présentera comment implémenter les fonctions de stockage d'images et de traitement des données dans MongoDB, et fournira des exemples de code spécifiques. Stockage d'images : dans MongoDB, vous pouvez utiliser GridFS
 En savoir plus sur la technologie de mise en cache Aerospike
Jun 20, 2023 am 11:28 AM
En savoir plus sur la technologie de mise en cache Aerospike
Jun 20, 2023 am 11:28 AM
Avec l’avènement de l’ère numérique, le Big Data est devenu un élément indispensable dans tous les domaines. En tant que solution permettant de traiter des données à grande échelle, l’importance de la technologie de mise en cache est devenue de plus en plus importante. Aerospike est une technologie de mise en cache haute performance. Dans cet article, nous apprendrons en détail les principes, les caractéristiques et les scénarios d'application de la technologie de mise en cache Aerospike. 1. Le principe de la technologie de mise en cache Aerospike Aerospike est une base de données Key-Value basée sur la mémoire et la mémoire flash qu'elle utilise.
 Interaction entre Redis et Golang : comment obtenir un stockage et une récupération rapides des données
Jul 30, 2023 pm 05:18 PM
Interaction entre Redis et Golang : comment obtenir un stockage et une récupération rapides des données
Jul 30, 2023 pm 05:18 PM
Interaction entre Redis et Golang : Comment obtenir un stockage et une récupération rapides des données Introduction : Avec le développement rapide d'Internet, le stockage et la récupération des données sont devenus des besoins importants dans divers domaines d'application. Dans ce contexte, Redis est devenu un middleware de stockage de données important, et Golang est devenu le choix de plus en plus de développeurs en raison de ses performances efficaces et de sa simplicité d'utilisation. Cet article présentera aux lecteurs comment interagir avec Golang via Redis pour obtenir un stockage et une récupération rapides des données. 1.Re
 Quel type de fichier est un fichier DAT ?
Feb 19, 2024 am 11:32 AM
Quel type de fichier est un fichier DAT ?
Feb 19, 2024 am 11:32 AM
Le fichier dat est un format de fichier de données universel qui peut être utilisé pour stocker différents types de données. Les fichiers dat peuvent contenir différentes formes de données telles que du texte, des images, de l'audio et de la vidéo. Il est largement utilisé dans de nombreuses applications et systèmes d’exploitation différents. Les fichiers dat sont généralement des fichiers binaires qui stockent les données en octets plutôt qu'en texte. Cela signifie que les fichiers DAT ne peuvent pas être modifiés ni leur contenu visualisé directement via un éditeur de texte. Au lieu de cela, des logiciels ou des outils spécifiques sont nécessaires pour traiter et analyser les données des fichiers DAT. d
 Comment utiliser C++ pour une compression et un stockage de données efficaces ?
Aug 25, 2023 am 10:24 AM
Comment utiliser C++ pour une compression et un stockage de données efficaces ?
Aug 25, 2023 am 10:24 AM
Comment utiliser C++ pour une compression et un stockage de données efficaces ? Introduction : À mesure que la quantité de données augmente, la compression et le stockage des données deviennent de plus en plus importants. En C++, il existe de nombreuses façons d’obtenir une compression et un stockage efficaces des données. Cet article présentera certains algorithmes de compression de données et technologies de stockage de données courants en C++, et fournira des exemples de code correspondants. 1. Algorithme de compression de données 1.1 Algorithme de compression basé sur le codage de Huffman Le codage de Huffman est un algorithme de compression de données basé sur un codage de longueur variable. Pour ce faire, il associe des caractères avec une fréquence plus élevée
 À l'ère des grands modèles d'IA, les nouvelles bases de stockage de données favorisent la transition vers l'intelligence numérique de l'éducation et de la recherche scientifique
Jul 21, 2023 pm 09:53 PM
À l'ère des grands modèles d'IA, les nouvelles bases de stockage de données favorisent la transition vers l'intelligence numérique de l'éducation et de la recherche scientifique
Jul 21, 2023 pm 09:53 PM
L'IA générative (AIGC) a ouvert une nouvelle ère d'intelligence artificielle générale. La concurrence autour des grands modèles est devenue spectaculaire. L'infrastructure informatique est le principal objectif de la concurrence, et la prise de pouvoir devient de plus en plus un consensus industriel. Dans la nouvelle ère, les grands modèles passent d'une modalité unique à une multimodalité, la taille des paramètres et des ensembles de données d'entraînement augmente de façon exponentielle et les données massives non structurées nécessitent en même temps la prise en charge de capacités de charge mixtes hautes performances ; gourmand en données Le nouveau paradigme gagne en popularité et les scénarios d'application tels que le calcul intensif et le calcul haute performance (HPC) évoluent en profondeur. Les bases de stockage de données existantes ne sont plus en mesure de répondre aux besoins en constante évolution. Si la puissance de calcul, les algorithmes et les données constituent la « troïka » qui conduit le développement de l'intelligence artificielle, alors dans le contexte d'énormes changements dans l'environnement externe, les trois doivent de toute urgence retrouver un dynamisme
