

请问 寻找PHP采集大量网页高效可行的方法

请教 寻找PHP采集大量网页高效可行的方法

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Solution : Votre organisation vous demande de modifier votre code PIN
Oct 04, 2023 pm 05:45 PM
Solution : Votre organisation vous demande de modifier votre code PIN
Oct 04, 2023 pm 05:45 PM
Le message « Votre organisation vous a demandé de modifier votre code PIN » apparaîtra sur l'écran de connexion. Cela se produit lorsque la limite d'expiration du code PIN est atteinte sur un ordinateur utilisant les paramètres de compte basés sur l'organisation, sur lesquels ils contrôlent les appareils personnels. Cependant, si vous configurez Windows à l'aide d'un compte personnel, le message d'erreur ne devrait idéalement pas apparaître. Même si ce n'est pas toujours le cas. La plupart des utilisateurs qui rencontrent des erreurs déclarent utiliser leur compte personnel. Pourquoi mon organisation me demande-t-elle de modifier mon code PIN sous Windows 11 ? Il est possible que votre compte soit associé à une organisation et votre approche principale devrait être de le vérifier. Contacter votre administrateur de domaine peut vous aider ! De plus, des paramètres de stratégie locale mal configurés ou des clés de registre incorrectes peuvent provoquer des erreurs. Tout de suite
 Comment ajuster les paramètres de bordure de fenêtre sous Windows 11 : modifier la couleur et la taille
Sep 22, 2023 am 11:37 AM
Comment ajuster les paramètres de bordure de fenêtre sous Windows 11 : modifier la couleur et la taille
Sep 22, 2023 am 11:37 AM
Windows 11 met au premier plan un design frais et élégant ; l'interface moderne vous permet de personnaliser et de modifier les moindres détails, tels que les bordures des fenêtres. Dans ce guide, nous discuterons des instructions étape par étape pour vous aider à créer un environnement qui reflète votre style dans le système d'exploitation Windows. Comment modifier les paramètres de bordure de fenêtre ? Appuyez sur + pour ouvrir l'application Paramètres. WindowsJe vais dans Personnalisation et clique sur Paramètres de couleur. Changement de couleur Paramètres des bordures de fenêtre Fenêtre 11" Largeur = "643" Hauteur = "500" > Recherchez l'option Afficher la couleur d'accent sur la barre de titre et les bordures de fenêtre et activez le commutateur à côté. Pour afficher les couleurs d'accent dans le menu Démarrer et la barre des tâches Pour afficher la couleur du thème dans le menu Démarrer et la barre des tâches, activez Afficher le thème dans le menu Démarrer et la barre des tâches.
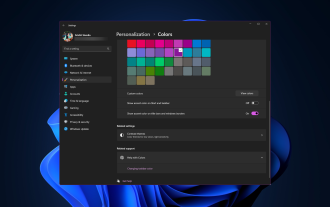 Comment changer la couleur de la barre de titre sous Windows 11 ?
Sep 14, 2023 pm 03:33 PM
Comment changer la couleur de la barre de titre sous Windows 11 ?
Sep 14, 2023 pm 03:33 PM
Par défaut, la couleur de la barre de titre sous Windows 11 dépend du thème sombre/clair que vous choisissez. Cependant, vous pouvez le changer pour la couleur de votre choix. Dans ce guide, nous discuterons des instructions étape par étape sur trois façons de le modifier et de personnaliser votre expérience de bureau pour la rendre visuellement attrayante. Est-il possible de changer la couleur de la barre de titre des fenêtres actives et inactives ? Oui, vous pouvez modifier la couleur de la barre de titre des fenêtres actives à l'aide de l'application Paramètres, ou vous pouvez modifier la couleur de la barre de titre des fenêtres inactives à l'aide de l'Éditeur du Registre. Pour connaître ces étapes, passez à la section suivante. Comment changer la couleur de la barre de titre sous Windows 11 ? 1. Appuyez sur + pour ouvrir la fenêtre des paramètres à l'aide de l'application Paramètres. WindowsJe vais dans "Personnalisation" puis
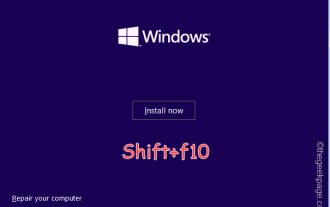 Problèmes d'erreur OOBELANGUAGE dans la réparation de Windows 11/10
Jul 16, 2023 pm 03:29 PM
Problèmes d'erreur OOBELANGUAGE dans la réparation de Windows 11/10
Jul 16, 2023 pm 03:29 PM
Voyez-vous « Un problème est survenu » avec l'instruction « OOBELANGUAGE » sur la page Windows Installer ? L'installation de Windows s'arrête parfois à cause de telles erreurs. OOBE signifie expérience hors des sentiers battus. Comme l'indique le message d'erreur, il s'agit d'un problème lié à la sélection de la langue OOBE. Il n'y a rien à craindre, vous pouvez résoudre ce problème avec une astucieuse modification du registre à partir de l'écran OOBE lui-même. Solution rapide – 1. Cliquez sur le bouton « Réessayer » en bas de l'application OOBE. Cela permettra de poursuivre le processus sans autre problème. 2. Utilisez le bouton d'alimentation pour forcer l'arrêt du système. Après le redémarrage du système, OOBE devrait continuer. 3. Déconnectez le système d'Internet. Terminez tous les aspects d'OOBE en mode hors ligne
 Comment activer ou désactiver les aperçus miniatures de la barre des tâches sur Windows 11
Sep 15, 2023 pm 03:57 PM
Comment activer ou désactiver les aperçus miniatures de la barre des tâches sur Windows 11
Sep 15, 2023 pm 03:57 PM
Les miniatures de la barre des tâches peuvent être amusantes, mais elles peuvent aussi être distrayantes ou ennuyeuses. Compte tenu de la fréquence à laquelle vous survolez cette zone, vous avez peut-être fermé plusieurs fois des fenêtres importantes par inadvertance. Un autre inconvénient est qu'il utilise plus de ressources système, donc si vous cherchez un moyen d'être plus efficace en termes de ressources, nous allons vous montrer comment le désactiver. Cependant, si vos spécifications matérielles peuvent le gérer et que vous aimez l'aperçu, vous pouvez l'activer. Comment activer l’aperçu miniature de la barre des tâches dans Windows 11 ? 1. Utilisez l'application Paramètres pour appuyer sur la touche et cliquez sur Paramètres. Windows, cliquez sur Système et sélectionnez À propos. Cliquez sur Paramètres système avancés. Accédez à l'onglet Avancé et sélectionnez Paramètres sous Performances. Sélectionnez "Effets visuels"
 Afficher le guide de mise à l'échelle sur Windows 11
Sep 19, 2023 pm 06:45 PM
Afficher le guide de mise à l'échelle sur Windows 11
Sep 19, 2023 pm 06:45 PM
Nous avons tous des préférences différentes en matière de mise à l'échelle de l'affichage sur Windows 11. Certaines personnes aiment les grandes icônes, d’autres les petites. Cependant, nous sommes tous d’accord sur le fait qu’il est important d’avoir la bonne échelle. Une mauvaise mise à l'échelle des polices ou une mise à l'échelle excessive des images peuvent nuire à la productivité lorsque vous travaillez. Vous devez donc savoir comment la personnaliser pour tirer le meilleur parti des capacités de votre système. Avantages du zoom personnalisé : Il s'agit d'une fonctionnalité utile pour les personnes qui ont des difficultés à lire du texte à l'écran. Cela vous aide à voir plus sur l’écran à la fois. Vous pouvez créer des profils d'extension personnalisés qui s'appliquent uniquement à certains moniteurs et applications. Peut aider à améliorer les performances du matériel bas de gamme. Cela vous donne plus de contrôle sur ce qui est sur votre écran. Comment utiliser Windows 11
 10 façons de régler la luminosité sous Windows 11
Dec 18, 2023 pm 02:21 PM
10 façons de régler la luminosité sous Windows 11
Dec 18, 2023 pm 02:21 PM
La luminosité de l’écran fait partie intégrante de l’utilisation des appareils informatiques modernes, en particulier lorsque vous regardez l’écran pendant de longues périodes. Il vous aide à réduire la fatigue oculaire, à améliorer la lisibilité et à visualiser le contenu facilement et efficacement. Cependant, en fonction de vos paramètres, il peut parfois être difficile de gérer la luminosité, notamment sous Windows 11 avec les nouvelles modifications de l'interface utilisateur. Si vous rencontrez des difficultés pour régler la luminosité, voici toutes les manières de gérer la luminosité sous Windows 11. Comment modifier la luminosité sous Windows 11 [10 méthodes expliquées] Les utilisateurs d'un seul moniteur peuvent utiliser les méthodes suivantes pour régler la luminosité sous Windows 11. Cela inclut les systèmes de bureau utilisant un seul moniteur ainsi que les ordinateurs portables. Commençons. Méthode 1 : Utiliser le Centre d'action Le Centre d'action est accessible
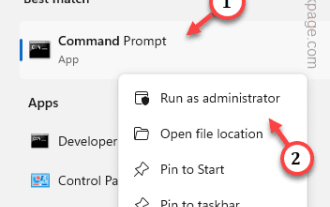 Comment réparer le code d'erreur d'activation 0xc004f069 dans Windows Server
Jul 22, 2023 am 09:49 AM
Comment réparer le code d'erreur d'activation 0xc004f069 dans Windows Server
Jul 22, 2023 am 09:49 AM
Le processus d'activation sous Windows prend parfois une tournure soudaine pour afficher un message d'erreur contenant ce code d'erreur 0xc004f069. Bien que le processus d'activation soit en ligne, certains anciens systèmes exécutant Windows Server peuvent rencontrer ce problème. Effectuez ces vérifications initiales et si elles ne vous aident pas à activer votre système, passez à la solution principale pour résoudre le problème. Solution de contournement : fermez le message d'erreur et la fenêtre d'activation. Ensuite, redémarrez votre ordinateur. Réessayez le processus d'activation de Windows à partir de zéro. Correctif 1 – Activer depuis le terminal Activez le système Windows Server Edition à partir du terminal cmd. Étape – 1 Vérifiez la version de Windows Server Vous devez vérifier quel type de W vous utilisez
