

深入理解python多进程编程

1、python多进程编程背景
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用;在多线程中,内存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据;在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图:
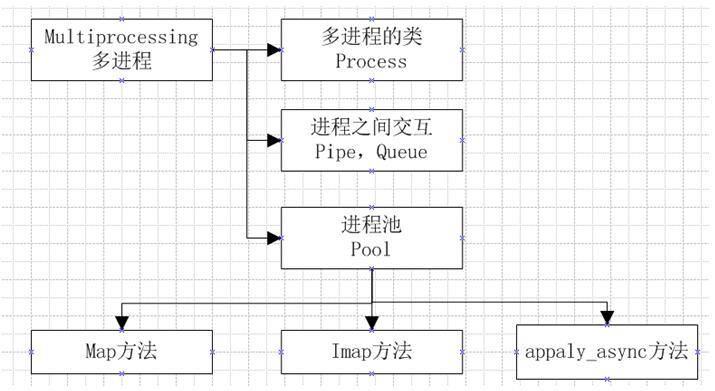
2、多进程的类Process
多进程的类Process和多线程的类Thread差不多的方法,两者的接口基本相同,具体看以下的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
在上面例子中可以看到,多进程和多线程的API接口是一样一样的,显示创建进程,然后进行start开始运行,然后join等待进程结束。
在需要执行的函数中,打印出了进程的id和pid,从而可以看到父进程和子进程的id号,在linu中,进程主要是使用fork出来的,在创建进程的时候可以查询到父进程和子进程的id号,而在多线程中是无法找到线程的id,执行效果如下:
1 2 3 4 5 6 7 8 9 |
|
在操作系统中查询的id的时候,最好用pstree,清晰:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
在进行运行的时候,可以看到,如果没有join语句,那么主进程是不会等待子进程结束的,是一直会执行下去,然后再等待子进程的执行。
在多进程的时候,说,我怎么得到多进程的返回值呢?然后写了下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
尝试从结果中返回值,从而在主进程中得到子进程的返回值,然而,,,并没有结果,后来一想,在进程中,进程之间是不共享内存的 ,那么使用list来存放数据显然是不可行的,进程之间的交互必须依赖于特殊的数据结构,从而以上的代码仅仅是执行进程,不能得到进程的返回值,但是以上代码修改为线程,那么是可以得到返回值的。
3、进程间的交互Queue
进程间交互的时候,首先就可以使用在多线程里面一样的Queue结构,但是在多进程中,必须使用multiprocessing里的Queue,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
其实这个是上面例子的改进,在其中,并没有使用什么其他的代码,主要就是使用Queue来保存数据,从而可以达到进程间交换数据的目的。
在进行使用Queue的时候,其实用的是socket,感觉,因为在其中使用的还是发送send,然后是接收recv。
在进行数据交互的时候,其实是父进程和所有的子进程进行数据交互,所有的子进程之间基本是没有交互的,除非,但是,也是可以的,例如,每个进程去Queue中取数据,但是这个时候应该是要考虑锁,不然可能会造成数据混乱。
4、 进程之间交互Pipe
在进程之间交互数据的时候还可以使用Pipe,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
在以上代码中,主要是使用Pipe中返回的两个socket来进行传输和接收数据,在父进程中,使用的是parent_conn,在子进程中使用的是child_conn,从而子进程发送数据的方法send,而在父进程中进行接收方法recv
最好的地方在于,明确的知道收发的次数,但是如果某个出现异常,那么估计pipe不能使用了。
5、进程池pool
其实在使用多进程的时候,感觉使用pool是最方便的,在多线程中是不存在pool的。
在使用pool的时候,可以限制每次的进程数,也就是剩余的进程是在排队,而只有在设定的数量的进程在运行,在默认的情况下,进程是cpu的个数,也就是根据multiprocessing.cpu_count()得出的结果。
在poo中,有两个方法,一个是map一个是imap,其实这两方法超级方便,在执行结束之后,可以得到每个进程的返回结果,但是缺点就是每次的时候,只能有一个参数,也就是在执行的函数中,最多是只有一个参数的,否则,需要使用组合参数的方法,代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
在使用map的时候,直接返回的一个是一个list,从而这个list也就是函数执行的结果,而在imap中,返回的是一个由结果组成的迭代器,如果需要使用多个参数的话,那么估计需要*args,从而使用参数args。
在使用apply.async的时候,可以直接使用多个参数,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
在进行得到各个结果的时候,注意使用了一个list来进行append,要不然在得到结果get的时候会阻塞进程,从而将多进程编程了单进程,从而使用了一个list来存放相关的结果,在进行得到get数据的时候,可以设置超时时间,也就是get(timeout=5),这种设置。
总结:
在进行多进程编程的时候,注意进程之间的交互,在执行函数之后,如何得到执行函数的结果,可以使用特殊的数据结构,例如Queue或者Pipe或者其他,在使用pool的时候,可以直接得到结果,map和imap都是直接得到一个list和可迭代对象,而apply_async得到的结果需要用一个list装起来,然后得到每个结果。
以上这篇深入理解python多进程编程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texte
Mar 05, 2025 am 09:58 AM
Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texte
Mar 05, 2025 am 09:58 AM
Ce tutoriel montre comment utiliser Python pour traiter le concept statistique de la loi de Zipf et démontre l'efficacité de la lecture et du tri de Python de gros fichiers texte lors du traitement de la loi. Vous vous demandez peut-être ce que signifie le terme distribution ZIPF. Pour comprendre ce terme, nous devons d'abord définir la loi de Zipf. Ne vous inquiétez pas, je vais essayer de simplifier les instructions. La loi de Zipf La loi de Zipf signifie simplement: dans un grand corpus en langage naturel, les mots les plus fréquents apparaissent environ deux fois plus fréquemment que les deuxième mots fréquents, trois fois comme les troisième mots fréquents, quatre fois comme quatrième mots fréquents, etc. Regardons un exemple. Si vous regardez le corpus brun en anglais américain, vous remarquerez que le mot le plus fréquent est "th
 Comment utiliser la belle soupe pour analyser HTML?
Mar 10, 2025 pm 06:54 PM
Comment utiliser la belle soupe pour analyser HTML?
Mar 10, 2025 pm 06:54 PM
Cet article explique comment utiliser la belle soupe, une bibliothèque Python, pour analyser HTML. Il détaille des méthodes courantes comme find (), find_all (), select () et get_text () pour l'extraction des données, la gestion de diverses structures et erreurs HTML et alternatives (Sel
 Filtrage d'image en python
Mar 03, 2025 am 09:44 AM
Filtrage d'image en python
Mar 03, 2025 am 09:44 AM
Traiter avec des images bruyantes est un problème courant, en particulier avec des photos de téléphones portables ou de caméras basse résolution. Ce tutoriel explore les techniques de filtrage d'images dans Python à l'aide d'OpenCV pour résoudre ce problème. Filtrage d'image: un outil puissant Filtre d'image
 Introduction à la programmation parallèle et simultanée dans Python
Mar 03, 2025 am 10:32 AM
Introduction à la programmation parallèle et simultanée dans Python
Mar 03, 2025 am 10:32 AM
Python, un favori pour la science et le traitement des données, propose un écosystème riche pour l'informatique haute performance. Cependant, la programmation parallèle dans Python présente des défis uniques. Ce tutoriel explore ces défis, en se concentrant sur l'interprète mondial
 Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?
Mar 10, 2025 pm 06:52 PM
Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?
Mar 10, 2025 pm 06:52 PM
Cet article compare TensorFlow et Pytorch pour l'apprentissage en profondeur. Il détaille les étapes impliquées: préparation des données, construction de modèles, formation, évaluation et déploiement. Différences clés entre les cadres, en particulier en ce qui concerne le raisin informatique
 Comment implémenter votre propre structure de données dans Python
Mar 03, 2025 am 09:28 AM
Comment implémenter votre propre structure de données dans Python
Mar 03, 2025 am 09:28 AM
Ce didacticiel montre la création d'une structure de données de pipeline personnalisée dans Python 3, en tirant parti des classes et de la surcharge de l'opérateur pour une fonctionnalité améliorée. La flexibilité du pipeline réside dans sa capacité à appliquer une série de fonctions à un ensemble de données, GE
 Sérialisation et désérialisation des objets Python: partie 1
Mar 08, 2025 am 09:39 AM
Sérialisation et désérialisation des objets Python: partie 1
Mar 08, 2025 am 09:39 AM
La sérialisation et la désérialisation des objets Python sont des aspects clés de tout programme non trivial. Si vous enregistrez quelque chose dans un fichier Python, vous effectuez une sérialisation d'objets et une désérialisation si vous lisez le fichier de configuration, ou si vous répondez à une demande HTTP. Dans un sens, la sérialisation et la désérialisation sont les choses les plus ennuyeuses du monde. Qui se soucie de tous ces formats et protocoles? Vous voulez persister ou diffuser des objets Python et les récupérer dans son intégralité plus tard. C'est un excellent moyen de voir le monde à un niveau conceptuel. Cependant, à un niveau pratique, le schéma de sérialisation, le format ou le protocole que vous choisissez peut déterminer la vitesse, la sécurité, le statut de liberté de maintenance et d'autres aspects du programme
 Modules mathématiques en python: statistiques
Mar 09, 2025 am 11:40 AM
Modules mathématiques en python: statistiques
Mar 09, 2025 am 11:40 AM
Le module statistique de Python fournit de puissantes capacités d'analyse statistique de données pour nous aider à comprendre rapidement les caractéristiques globales des données, telles que la biostatistique et l'analyse commerciale. Au lieu de regarder les points de données un par un, regardez simplement des statistiques telles que la moyenne ou la variance pour découvrir les tendances et les fonctionnalités des données d'origine qui peuvent être ignorées et comparer les grands ensembles de données plus facilement et efficacement. Ce tutoriel expliquera comment calculer la moyenne et mesurer le degré de dispersion de l'ensemble de données. Sauf indication contraire, toutes les fonctions de ce module prennent en charge le calcul de la fonction moyenne () au lieu de simplement additionner la moyenne. Les nombres de points flottants peuvent également être utilisés. Importer au hasard Statistiques d'importation de fracTI
