

爬虫如何获得biilbili播放数?

<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
 使用火狐查看选中部分源代码,如下
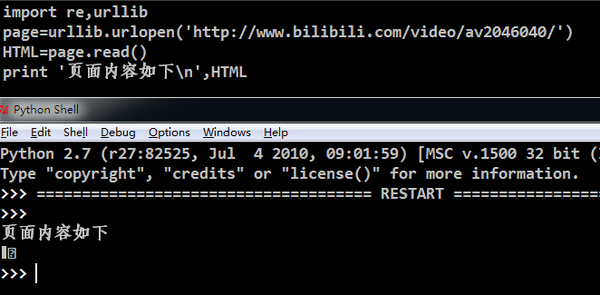
使用火狐查看选中部分源代码,如下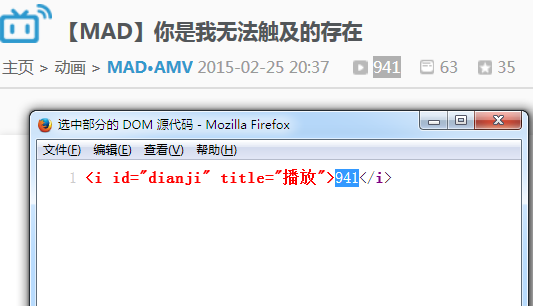 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
 既可以获得如下界面:
既可以获得如下界面: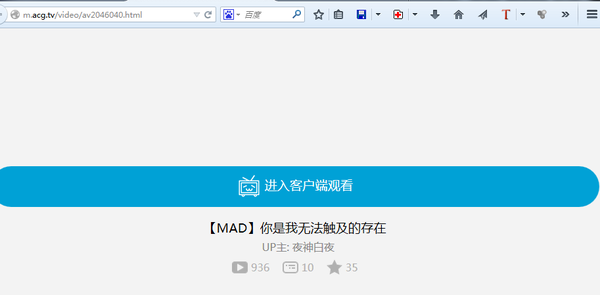 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码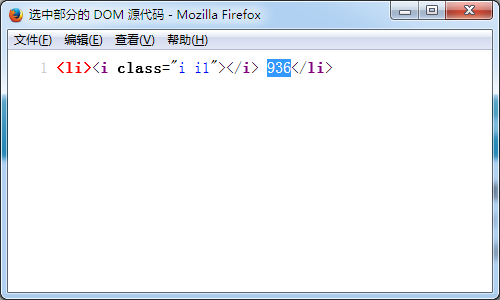 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)</script>',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050然后被
<click>4611</click>

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Quelles sont les différences entre Huawei GT3 Pro et GT4 ?
Dec 29, 2023 pm 02:27 PM
Quelles sont les différences entre Huawei GT3 Pro et GT4 ?
Dec 29, 2023 pm 02:27 PM
De nombreux utilisateurs choisiront la marque Huawei lors du choix des montres intelligentes. Parmi eux, les Huawei GT3pro et GT4 sont des choix très populaires. De nombreux utilisateurs sont curieux de connaître la différence entre Huawei GT3pro et GT4. Quelles sont les différences entre Huawei GT3pro et GT4 ? 1. Apparence GT4 : 46 mm et 41 mm, le matériau est un miroir en verre + un corps en acier inoxydable + une coque arrière en fibre haute résolution. GT3pro : 46,6 mm et 42,9 mm, le matériau est du verre saphir + corps en titane/corps en céramique + coque arrière en céramique 2. GT4 sain : en utilisant le dernier algorithme Huawei Truseen5.5+, les résultats seront plus précis. GT3pro : ajout d'un électrocardiogramme ECG, d'un vaisseau sanguin et de la sécurité
 Correctif : l'outil de capture ne fonctionne pas sous Windows 11
Aug 24, 2023 am 09:48 AM
Correctif : l'outil de capture ne fonctionne pas sous Windows 11
Aug 24, 2023 am 09:48 AM
Pourquoi l'outil Snipping ne fonctionne pas sous Windows 11 Comprendre la cause première du problème peut aider à trouver la bonne solution. Voici les principales raisons pour lesquelles l'outil de capture peut ne pas fonctionner correctement : L'assistant de mise au point est activé : cela empêche l'ouverture de l'outil de capture. Application corrompue : si l'outil de capture plante au lancement, il est peut-être corrompu. Pilotes graphiques obsolètes : des pilotes incompatibles peuvent interférer avec l'outil de capture. Interférence provenant d'autres applications : d'autres applications en cours d'exécution peuvent entrer en conflit avec l'outil de capture. Le certificat a expiré : une erreur lors du processus de mise à niveau peut provoquer ce problème. Solution simple. Celles-ci conviennent à la plupart des utilisateurs et ne nécessitent aucune connaissance technique particulière. 1. Mettez à jour les applications Windows et Microsoft Store
 La différence entre counta et count
Nov 20, 2023 am 10:01 AM
La différence entre counta et count
Nov 20, 2023 am 10:01 AM
La fonction Count est utilisée pour compter le nombre de nombres dans une plage spécifiée. Elle ignore le texte, les valeurs logiques et les valeurs nulles, mais compte les cellules vides. La fonction Count ne compte que le nombre de cellules contenant des nombres réels. La fonction CountA est utilisée pour compter le nombre de cellules non vides dans une plage spécifiée. Il compte non seulement les cellules contenant des nombres réels, mais également le nombre de cellules non vides contenant du texte, des valeurs logiques et des formules.
 Comment réparer l'erreur Impossible de se connecter à l'App Store sur iPhone
Jul 29, 2023 am 08:22 AM
Comment réparer l'erreur Impossible de se connecter à l'App Store sur iPhone
Jul 29, 2023 am 08:22 AM
Partie 1 : étapes de dépannage initiales Vérification de l'état du système Apple : avant d'aborder des solutions complexes, commençons par les bases. Le problème ne vient peut-être pas de votre appareil ; les serveurs Apple sont peut-être en panne. Visitez la page État du système d'Apple pour voir si l'AppStore fonctionne correctement. S'il y a un problème, tout ce que vous pouvez faire est d'attendre qu'Apple le résolve. Vérifiez votre connexion Internet : assurez-vous que vous disposez d'une connexion Internet stable, car le problème "Impossible de se connecter à l'AppStore" peut parfois être attribué à une mauvaise connexion. Essayez de basculer entre le Wi-Fi et les données mobiles ou de réinitialiser les paramètres réseau (Général > Réinitialiser > Réinitialiser les paramètres réseau > Paramètres). Mettez à jour votre version iOS :
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
 que signifie le titre
Aug 04, 2023 am 11:18 AM
que signifie le titre
Aug 04, 2023 am 11:18 AM
Le titre est la signification qui définit le titre de la page Web. Il se trouve dans la balise et correspond au texte affiché dans la barre de titre du navigateur. Le titre est très important pour l'optimisation des moteurs de recherche et l'expérience utilisateur de la page Web. Lorsque vous rédigez des pages Web HTML, vous devez veiller à utiliser des mots-clés pertinents et des descriptions attrayantes pour définir l'élément de titre afin d'inciter davantage d'utilisateurs à cliquer et à parcourir.
 Quelle est la signification du titre en HTML
Mar 06, 2024 am 09:53 AM
Quelle est la signification du titre en HTML
Mar 06, 2024 am 09:53 AM
Le titre en HTML affiche la balise de titre de la page Web, ce qui permet au spectateur de savoir de quoi parle principalement la page actuelle. Chaque page Web doit donc avoir un titre distinct.
 Quelles sont les différences entre div et span ?
Nov 02, 2023 pm 02:29 PM
Quelles sont les différences entre div et span ?
Nov 02, 2023 pm 02:29 PM
Les différences sont les suivantes : 1. div est un élément de niveau bloc et span est un élément en ligne ; 2. div occupera automatiquement une ligne, tandis que span ne sera pas automatiquement renvoyé à la ligne ; 3. div est utilisé pour envelopper des structures et des mises en page plus volumineuses ; span est utilisé pour envelopper du texte ou d'autres éléments en ligne ; 4. div peut contenir d'autres éléments de niveau bloc et des éléments en ligne, et span peut contenir d'autres éléments en ligne.
