

PHP的XML模式详解

研究与 php(做为现在的主流开发语言) 5 捆绑在一起的 xml(标准化越来越近了)Reader 库,它使 php(做为现在的主流开发语言) 页面能够以高效的流模式来处理 xml(标准化越来越近了) 文档。
php(做为现在的主流开发语言) 5 引入了新的类 xml(标准化越来越近了)Reader,用于读取可扩展标记语言(Extensible Markup Language,xml(标准化越来越近了))。与 Simplexml(标准化越来越近了) 或文档对象模型(Document Object Model,DOM)不同,xml(标准化越来越近了)Reader 以流模式进行操作。即它从头到尾读取文档。在文档后面的内容编译完成之前,可以先处理已编译好的文档前面的内容,从而实现非常快速、非常高效、非常节省地使用内存。需要处理的文档越大,这个特点就越发重要。
libxml(标准化越来越近了)
这里所说的 xml(标准化越来越近了)Reader API 位于 Gnome Project 中用于 C 和 C++ 的 libxml(标准化越来越近了) 库之上。实际上 xml(标准化越来越近了)Reader 只是在 libxml(标准化越来越近了) 的 xml(标准化越来越近了)TextReader API 之上的很薄的 php(做为现在的主流开发语言) 层。xml(标准化越来越近了)TextReader 本身是模仿 .NET 的 xml(标准化越来越近了)TextReader 类和 xml(标准化越来越近了)Reader 类,尽管并不具有与这些类相似的代码。
与 Simple API for xml(标准化越来越近了) (SAX) 不同,xml(标准化越来越近了)Reader 是推解析器,而不是拉解析器。这意味着程序是可以控制的。您将告诉解析器何时获取下一个文档片段,而不是在解析器看到文档后告诉您所看到的内容。您将请求内容,而不是对内容进行反应。从另一个角度来考虑这个问题:xml(标准化越来越近了)Reader 是 Iterator 设计模式的实现,而不是 Observer 设计模式的实现。
示例问题
先从简单例子开始讨论。假定正在编写 php(做为现在的主流开发语言) 脚本,用来接收 xml(标准化越来越近了)-RPC 请求并生成响应。更具体一些,假定请求如清单 1 所示。文档的根元素是 methodCall,它包含 methodName 元素和 params 元素。方法的名称是 sqrt.params 元素包含一个 param 元素,param 元素包含 double,double 的平方根是希望得到的值。没有使用名称空间。
清单 1. xml(标准化越来越近了)-RPC 请求
<b>以下是引用片段:<br></b><?xml <font class=reblank>(标准化越来越近了) version="1.0"?> <br><methodcall> <br> <methodname>sqrt</methodname> <br> <params> <br> <param> <br> <value><double>36.0</double></value> <br> <br> </params> <br></methodcall> Copier après la connexion |
下面是 php(做为现在的主流开发语言) 脚本需要完成的工作:
1、检查方法名,如果不是 sqrt(它是该脚本懂得如何处理的惟一方法),则生成错误响应。
2、找到参数,如果参数不存在或参数类型错误,则生成错误响应。
3、另外,计算平方根。
4、在表单中返回结果,如清单 2 所示。
清单 2. xml(标准化越来越近了)-RPC 响应
<b>以下是引用片段:<br></b><?xml <font class=reblank>(标准化越来越近了) version="1.0"?> <br><methodresponse> <br> <params> <br> <param> <br> <value><double>6.0</double></value> <br> <br> </params> <br></methodresponse> Copier après la connexion |
下面我们逐步展开说明。
初始化解析器并载入文档
第一步是创建新的解析器对象。创建操作很简单:
<b>以下是引用片段:<br></b>$reader = new xml<font class="reblank">(标准化越来越近了)</font>Reader(); Copier après la connexion |
接着,需要为它提供一些用于解析的数据。对于 xml(标准化越来越近了)-RPC,这是超文本传输协议(Hypertext Transfer Protocol,HTTP)请求的原始主体。然后可以将该字符串传递到读取器的 xml(标准化越来越近了)() 函数:
填充原始发送数据
<b>以下是引用片段:<br></b> $request = $HTTP_RAW_POST_DATA; <br> $reader->xml<font class="reblank">(标准化越来越近了)</font>($request); Copier après la connexion |
如果发现 $HTTP_RAW_POST_DATA 是空的,则将以下代码行添加到 php(做为现在的主流开发语言).ini 文件:
<b>以下是引用片段:<br></b> always_populate_raw_post_data = On Copier après la connexion |
可以解析任何字符串,无论它是从何处获取的。例如,可以是程序中的一串文字或从本地文件读取。还可以使用 open() 函数从外部 URL 载入数据。例如,下面的语句准备解析其中一个 Atom 提要:
<b>以下是引用片段:<br></b> $reader->xml<font class="reblank">(标准化越来越近了)</font>('http://www.cafeaulait.org/today.atom');Copier après la connexion |
无论是从何处获取原始数据,现在已建立了阅读器并为解析做好准备。
读取文档
read() 函数使解析器前进到下一个标记。最简单的方法是在 while 循环中遍历整个文档:
<b>以下是引用片段:<br></b> while ($reader->read()) { <br> // processing code goes here... <br> }Copier après la connexion |
完成遍历后,关闭解析器以释放它所持有的任何资源,并且重置解析器以便用于下一个文档:
<b>以下是引用片段:<br></b> $reader->close(); Copier après la connexion |
在循环内部,将解析器放置在特殊节点上:元素的起点、元素的终点、文本节点、注释等等。通过检查以下属性,可以发现解析器正在查看的内容:
localName 是本地的、未带前缀的节点名。
name 是可能的节点前缀名。对于像注释这种没有名称的节点,包括 #comment、#text、#document 等等,与 DOM 中的一样。
namespaceURI 是节点名称空间的统一资源标识符(Uniform Resource Identifier,URI)。
nodeType 是代表节点类型的整数 —— 例如,2 代表属性节点,7 代表处理指令。
prefix 是节点的名称空间前缀。
value 是节点的下一个文本内容。
如果节点有文本值,hasValue 值为 true;否则,值为 false.

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment désactiver les mises à jour automatiques dans Adobe Acrobat Reader
Mar 14, 2024 pm 08:58 PM
Comment désactiver les mises à jour automatiques dans Adobe Acrobat Reader
Mar 14, 2024 pm 08:58 PM
AdobeAcrobatReader est un outil puissant pour visualiser et éditer des fichiers PDF. Le logiciel est disponible en versions gratuite et payante. Si vous devez utiliser Adobe Acrobat Reader pour modifier des fichiers PDF, vous devez acheter son forfait payant. Pour maintenir Adobe Acrobat Reader à jour avec les dernières améliorations et correctifs de sécurité, le logiciel active les mises à jour automatiques par défaut. Cependant, vous pouvez choisir de désactiver les mises à jour automatiques si vous le souhaitez. Cet article vous montrera comment désactiver les mises à jour automatiques dans Adobe Acrobat Reader. Comment désactiver les mises à jour automatiques dans Adobe Acrobat Reader avec
 Solution : Votre organisation vous demande de modifier votre code PIN
Oct 04, 2023 pm 05:45 PM
Solution : Votre organisation vous demande de modifier votre code PIN
Oct 04, 2023 pm 05:45 PM
Le message « Votre organisation vous a demandé de modifier votre code PIN » apparaîtra sur l'écran de connexion. Cela se produit lorsque la limite d'expiration du code PIN est atteinte sur un ordinateur utilisant les paramètres de compte basés sur l'organisation, sur lesquels ils contrôlent les appareils personnels. Cependant, si vous configurez Windows à l'aide d'un compte personnel, le message d'erreur ne devrait idéalement pas apparaître. Même si ce n'est pas toujours le cas. La plupart des utilisateurs qui rencontrent des erreurs déclarent utiliser leur compte personnel. Pourquoi mon organisation me demande-t-elle de modifier mon code PIN sous Windows 11 ? Il est possible que votre compte soit associé à une organisation et votre approche principale devrait être de le vérifier. Contacter votre administrateur de domaine peut vous aider ! De plus, des paramètres de stratégie locale mal configurés ou des clés de registre incorrectes peuvent provoquer des erreurs. Tout de suite
 Comment ajuster les paramètres de bordure de fenêtre sous Windows 11 : modifier la couleur et la taille
Sep 22, 2023 am 11:37 AM
Comment ajuster les paramètres de bordure de fenêtre sous Windows 11 : modifier la couleur et la taille
Sep 22, 2023 am 11:37 AM
Windows 11 met au premier plan un design frais et élégant ; l'interface moderne vous permet de personnaliser et de modifier les moindres détails, tels que les bordures des fenêtres. Dans ce guide, nous discuterons des instructions étape par étape pour vous aider à créer un environnement qui reflète votre style dans le système d'exploitation Windows. Comment modifier les paramètres de bordure de fenêtre ? Appuyez sur + pour ouvrir l'application Paramètres. WindowsJe vais dans Personnalisation et clique sur Paramètres de couleur. Changement de couleur Paramètres des bordures de fenêtre Fenêtre 11" Largeur = "643" Hauteur = "500" > Recherchez l'option Afficher la couleur d'accent sur la barre de titre et les bordures de fenêtre et activez le commutateur à côté. Pour afficher les couleurs d'accent dans le menu Démarrer et la barre des tâches Pour afficher la couleur du thème dans le menu Démarrer et la barre des tâches, activez Afficher le thème dans le menu Démarrer et la barre des tâches.
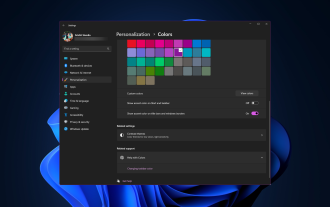 Comment changer la couleur de la barre de titre sous Windows 11 ?
Sep 14, 2023 pm 03:33 PM
Comment changer la couleur de la barre de titre sous Windows 11 ?
Sep 14, 2023 pm 03:33 PM
Par défaut, la couleur de la barre de titre sous Windows 11 dépend du thème sombre/clair que vous choisissez. Cependant, vous pouvez le changer pour la couleur de votre choix. Dans ce guide, nous discuterons des instructions étape par étape sur trois façons de le modifier et de personnaliser votre expérience de bureau pour la rendre visuellement attrayante. Est-il possible de changer la couleur de la barre de titre des fenêtres actives et inactives ? Oui, vous pouvez modifier la couleur de la barre de titre des fenêtres actives à l'aide de l'application Paramètres, ou vous pouvez modifier la couleur de la barre de titre des fenêtres inactives à l'aide de l'Éditeur du Registre. Pour connaître ces étapes, passez à la section suivante. Comment changer la couleur de la barre de titre sous Windows 11 ? 1. Appuyez sur + pour ouvrir la fenêtre des paramètres à l'aide de l'application Paramètres. WindowsJe vais dans "Personnalisation" puis
 Comment activer ou désactiver les aperçus miniatures de la barre des tâches sur Windows 11
Sep 15, 2023 pm 03:57 PM
Comment activer ou désactiver les aperçus miniatures de la barre des tâches sur Windows 11
Sep 15, 2023 pm 03:57 PM
Les miniatures de la barre des tâches peuvent être amusantes, mais elles peuvent aussi être distrayantes ou ennuyeuses. Compte tenu de la fréquence à laquelle vous survolez cette zone, vous avez peut-être fermé plusieurs fois des fenêtres importantes par inadvertance. Un autre inconvénient est qu'il utilise plus de ressources système, donc si vous cherchez un moyen d'être plus efficace en termes de ressources, nous allons vous montrer comment le désactiver. Cependant, si vos spécifications matérielles peuvent le gérer et que vous aimez l'aperçu, vous pouvez l'activer. Comment activer l’aperçu miniature de la barre des tâches dans Windows 11 ? 1. Utilisez l'application Paramètres pour appuyer sur la touche et cliquez sur Paramètres. Windows, cliquez sur Système et sélectionnez À propos. Cliquez sur Paramètres système avancés. Accédez à l'onglet Avancé et sélectionnez Paramètres sous Performances. Sélectionnez "Effets visuels"
 Afficher le guide de mise à l'échelle sur Windows 11
Sep 19, 2023 pm 06:45 PM
Afficher le guide de mise à l'échelle sur Windows 11
Sep 19, 2023 pm 06:45 PM
Nous avons tous des préférences différentes en matière de mise à l'échelle de l'affichage sur Windows 11. Certaines personnes aiment les grandes icônes, d’autres les petites. Cependant, nous sommes tous d’accord sur le fait qu’il est important d’avoir la bonne échelle. Une mauvaise mise à l'échelle des polices ou une mise à l'échelle excessive des images peuvent nuire à la productivité lorsque vous travaillez. Vous devez donc savoir comment la personnaliser pour tirer le meilleur parti des capacités de votre système. Avantages du zoom personnalisé : Il s'agit d'une fonctionnalité utile pour les personnes qui ont des difficultés à lire du texte à l'écran. Cela vous aide à voir plus sur l’écran à la fois. Vous pouvez créer des profils d'extension personnalisés qui s'appliquent uniquement à certains moniteurs et applications. Peut aider à améliorer les performances du matériel bas de gamme. Cela vous donne plus de contrôle sur ce qui est sur votre écran. Comment utiliser Windows 11
 Quelles sont les différences entre Huawei GT3 Pro et GT4 ?
Dec 29, 2023 pm 02:27 PM
Quelles sont les différences entre Huawei GT3 Pro et GT4 ?
Dec 29, 2023 pm 02:27 PM
De nombreux utilisateurs choisiront la marque Huawei lors du choix des montres intelligentes. Parmi eux, les Huawei GT3pro et GT4 sont des choix très populaires. De nombreux utilisateurs sont curieux de connaître la différence entre Huawei GT3pro et GT4. Quelles sont les différences entre Huawei GT3pro et GT4 ? 1. Apparence GT4 : 46 mm et 41 mm, le matériau est un miroir en verre + un corps en acier inoxydable + une coque arrière en fibre haute résolution. GT3pro : 46,6 mm et 42,9 mm, le matériau est du verre saphir + corps en titane/corps en céramique + coque arrière en céramique 2. GT4 sain : en utilisant le dernier algorithme Huawei Truseen5.5+, les résultats seront plus précis. GT3pro : ajout d'un électrocardiogramme ECG, d'un vaisseau sanguin et de la sécurité
 10 façons de régler la luminosité sous Windows 11
Dec 18, 2023 pm 02:21 PM
10 façons de régler la luminosité sous Windows 11
Dec 18, 2023 pm 02:21 PM
La luminosité de l’écran fait partie intégrante de l’utilisation des appareils informatiques modernes, en particulier lorsque vous regardez l’écran pendant de longues périodes. Il vous aide à réduire la fatigue oculaire, à améliorer la lisibilité et à visualiser le contenu facilement et efficacement. Cependant, en fonction de vos paramètres, il peut parfois être difficile de gérer la luminosité, notamment sous Windows 11 avec les nouvelles modifications de l'interface utilisateur. Si vous rencontrez des difficultés pour régler la luminosité, voici toutes les manières de gérer la luminosité sous Windows 11. Comment modifier la luminosité sous Windows 11 [10 méthodes expliquées] Les utilisateurs d'un seul moniteur peuvent utiliser les méthodes suivantes pour régler la luminosité sous Windows 11. Cela inclut les systèmes de bureau utilisant un seul moniteur ainsi que les ordinateurs portables. Commençons. Méthode 1 : Utiliser le Centre d'action Le Centre d'action est accessible
