

php5与mysql5 web 开发技术详解-12 Smarty与模板技术_PHP教程

1、MVC简介

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



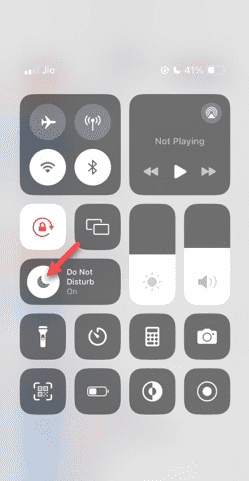 Le mode Ne pas déranger ne fonctionne pas sur iPhone : correctif
Apr 24, 2024 pm 04:50 PM
Le mode Ne pas déranger ne fonctionne pas sur iPhone : correctif
Apr 24, 2024 pm 04:50 PM
Même répondre à des appels en mode Ne pas déranger peut être une expérience très ennuyeuse. Comme son nom l'indique, le mode Ne pas déranger désactive toutes les notifications d'appels entrants et les alertes provenant d'e-mails, de messages, etc. Vous pouvez suivre ces ensembles de solutions pour résoudre ce problème. Correctif 1 – Activer le mode de mise au point Activez le mode de mise au point sur votre téléphone. Étape 1 – Faites glisser votre doigt depuis le haut pour accéder au Centre de contrôle. Étape 2 – Ensuite, activez le « Mode Focus » sur votre téléphone. Le mode Focus active le mode Ne pas déranger sur votre téléphone. Aucune alerte d’appel entrant n’apparaîtra sur votre téléphone. Correctif 2 – Modifier les paramètres du mode de mise au point S'il y a des problèmes dans les paramètres du mode de mise au point, vous devez les résoudre. Étape 1 – Ouvrez la fenêtre des paramètres de votre iPhone. Étape 2 – Ensuite, activez les paramètres du mode Focus
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Effets de la spécialisation des modèles C++ sur la surcharge et la réécriture des fonctions
Apr 20, 2024 am 09:09 AM
Effets de la spécialisation des modèles C++ sur la surcharge et la réécriture des fonctions
Apr 20, 2024 am 09:09 AM
Les spécialisations de modèles C++ affectent la surcharge et la réécriture des fonctions : Surcharge de fonctions : les versions spécialisées peuvent fournir différentes implémentations d'un type spécifique, affectant ainsi les fonctions que le compilateur choisit d'appeler. Remplacement de fonction : la version spécialisée dans la classe dérivée remplacera la fonction modèle dans la classe de base, affectant le comportement de l'objet de classe dérivée lors de l'appel de la fonction.
 PHP est-il front-end ou back-end dans le développement Web ?
Mar 24, 2024 pm 02:18 PM
PHP est-il front-end ou back-end dans le développement Web ?
Mar 24, 2024 pm 02:18 PM
PHP appartient au backend du développement Web. PHP est un langage de script côté serveur, principalement utilisé pour traiter la logique côté serveur et générer du contenu Web dynamique. Par rapport à la technologie front-end, PHP est davantage utilisé pour les opérations back-end telles que l'interaction avec les bases de données, le traitement des demandes des utilisateurs et la génération du contenu des pages. Ensuite, des exemples de code spécifiques seront utilisés pour illustrer l'application de PHP dans le développement back-end. Tout d'abord, regardons un exemple de code PHP simple pour se connecter à une base de données et interroger des données :
 Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que la reconstruction 3D basée sur l'image est une tâche difficile qui implique de déduire la forme 3D d'un objet ou d'une scène à partir d'un ensemble d'images d'entrée. Les méthodes basées sur l’apprentissage ont attiré l’attention pour leur capacité à estimer directement des formes 3D. Cet article de synthèse se concentre sur les techniques de reconstruction 3D de pointe, notamment la génération de nouvelles vues inédites. Un aperçu des développements récents dans les méthodes d'éclaboussure gaussienne est fourni, y compris les types d'entrée, les structures de modèle, les représentations de sortie et les stratégies de formation. Les défis non résolus et les orientations futures sont également discutés. Compte tenu des progrès rapides dans ce domaine et des nombreuses opportunités d’améliorer les méthodes de reconstruction 3D, un examen approfondi de l’algorithme semble crucial. Par conséquent, cette étude fournit un aperçu complet des progrès récents en matière de diffusion gaussienne. (Faites glisser votre pouce vers le haut
 Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Le 23 septembre, l'article « DeepModelFusion:ASurvey » a été publié par l'Université nationale de technologie de la défense, JD.com et l'Institut de technologie de Pékin. La fusion/fusion de modèles profonds est une technologie émergente qui combine les paramètres ou les prédictions de plusieurs modèles d'apprentissage profond en un seul modèle. Il combine les capacités de différents modèles pour compenser les biais et les erreurs des modèles individuels pour de meilleures performances. La fusion profonde de modèles sur des modèles d'apprentissage profond à grande échelle (tels que le LLM et les modèles de base) est confrontée à certains défis, notamment un coût de calcul élevé, un espace de paramètres de grande dimension, l'interférence entre différents modèles hétérogènes, etc. Cet article divise les méthodes de fusion de modèles profonds existantes en quatre catégories : (1) « Connexion de modèles », qui relie les solutions dans l'espace de poids via un chemin de réduction des pertes pour obtenir une meilleure fusion de modèles initiale.
 GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
Le modèle GPT-4o publié par OpenAI constitue sans aucun doute une énorme avancée, notamment dans sa capacité à traiter plusieurs supports d'entrée (texte, audio, images) et à générer la sortie correspondante. Cette capacité rend l’interaction homme-machine plus naturelle et intuitive, améliorant considérablement l’aspect pratique et la convivialité de l’IA. Plusieurs points forts de GPT-4o incluent : une évolutivité élevée, des entrées et sorties multimédias, de nouvelles améliorations des capacités de compréhension du langage naturel, etc. 1. Entrée/sortie multimédia : GPT-4o+ peut accepter n'importe quelle combinaison de texte, d'audio et d'images en entrée et générer directement une sortie à partir de ces médias. Cela brise les limites des modèles d’IA traditionnels qui ne traitent qu’un seul type d’entrée, rendant ainsi l’interaction homme-machine plus flexible et plus diversifiée. Cette innovation contribue à alimenter les assistants intelligents
 Prise en charge du navigateur Golang : créer un Web interactif
Apr 07, 2024 pm 04:03 PM
Prise en charge du navigateur Golang : créer un Web interactif
Apr 07, 2024 pm 04:03 PM
Go crée des applications Web interactives qui s'exécutent dans le navigateur. Étapes : Créez un projet Go et un fichier main.go, ajoutez un gestionnaire HTTP pour afficher les messages. Ajoutez des formulaires utilisant HTML et JavaScript pour la saisie et la soumission des utilisateurs. Ajoutez la gestion des requêtes POST dans votre application Go, recevez les messages des utilisateurs et renvoyez les réponses. Utilisez FetchAPI pour envoyer des requêtes POST et gérer les réponses du serveur.
