

Python的爬虫程序编写框架Scrapy入门学习教程

1. Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
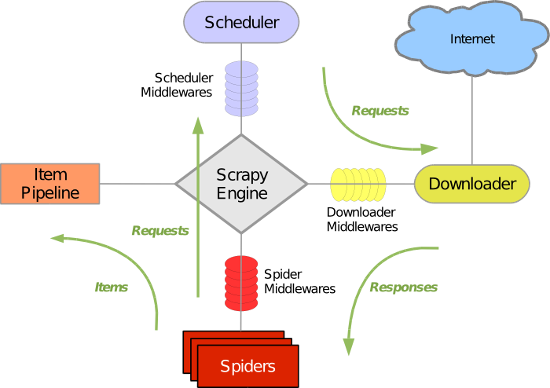
Scrapy主要包括了以下组件:
(1)引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
(2)调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
(3)下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
(4)爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(5)下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(6)爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
(7)调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
2. 安装Scrapy
使用以下命令:
sudo pip install virtualenv #安装虚拟环境工具 virtualenv ENV #创建一个虚拟环境目录 source ./ENV/bin/active #激活虚拟环境 pip install Scrapy #验证是否安装成功 pip list
#输出如下 cffi (0.8.6) cryptography (0.6.1) cssselect (0.9.1) lxml (3.4.1) pip (1.5.6) pycparser (2.10) pyOpenSSL (0.14) queuelib (1.2.2) Scrapy (0.24.4) setuptools (3.6) six (1.8.0) Twisted (14.0.2) w3lib (1.10.0) wsgiref (0.1.2) zope.interface (4.1.1)
更多虚拟环境的操作可以查看我的博文
3. Scrapy Tutorial
在抓取之前, 你需要新建一个Scrapy工程. 进入一个你想用来保存代码的目录,然后执行:
$ scrapy startproject tutorial
这个命令会在当前目录下创建一个新目录 tutorial, 它的结构如下:
. ├── scrapy.cfg └── tutorial ├── __init__.py ├── items.py ├── pipelines.py ├── settings.py └── spiders └── __init__.py
这些文件主要是:
(1)scrapy.cfg: 项目配置文件
(2)tutorial/: 项目python模块, 之后您将在此加入代码
(3)tutorial/items.py: 项目items文件
(4)tutorial/pipelines.py: 项目管道文件
(5)tutorial/settings.py: 项目配置文件
(6)tutorial/spiders: 放置spider的目录
3.1. 定义Item
Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误
通过创建scrapy.Item类, 并且定义类型为 scrapy.Field 的类属性来声明一个Item.
我们通过将需要的item模型化,来控制从 dmoz.org 获得的站点数据,比如我们要获得站点的名字,url 和网站描述,我们定义这三种属性的域。在 tutorial 目录下的 items.py 文件编辑
from scrapy.item import Item, Field class DmozItem(Item): # define the fields for your item here like: name = Field() description = Field() url = Field()
3.2. 编写Spider
Spider 是用户编写的类, 用于从一个域(或域组)中抓取信息, 定义了用于下载的URL的初步列表, 如何跟踪链接,以及如何来解析这些网页的内容用于提取items。
要建立一个 Spider,继承 scrapy.Spider 基类,并确定三个主要的、强制的属性:
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。我们可以利用正则表达式定义和过滤需要进行跟进的链接。
parse():是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
3.3. 爬取
当前项目结构
├── scrapy.cfg └── tutorial ├── __init__.py ├── items.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.py └── dmoz_spider.py
到项目根目录, 然后运行命令:
$ scrapy crawl dmoz
2014-12-15 09:30:59+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: tutorial)
2014-12-15 09:30:59+0800 [scrapy] INFO: Optional features available: ssl, http11
2014-12-15 09:30:59+0800 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial'}
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled item pipelines:
2014-12-15 09:30:59+0800 [dmoz] INFO: Spider opened
2014-12-15 09:30:59+0800 [dmoz] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] INFO: Closing spider (finished)
2014-12-15 09:31:00+0800 [dmoz] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 516,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 16338,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2014, 12, 15, 1, 31, 0, 666214),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2014, 12, 15, 1, 30, 59, 533207)}
2014-12-15 09:31:00+0800 [dmoz] INFO: Spider closed (finished)
3.4. 提取Items
3.4.1. 介绍Selector
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 或者 CSS 表达式机制: Scrapy Selectors
出XPath表达式的例子及对应的含义:
- /html/head/title: 选择HTML文档中 标签内的
元素</li> <li>/html/head/title/text(): 选择 <title> 元素内的文本</li> <li>//td: 选择所有的 <td> 元素</li> <li>//div[@class="mine"]: 选择所有具有class="mine" 属性的 div 元素</li> </ul> <p>等多强大的功能使用可以查看XPath tutorial</p> <p>为了方便使用 XPaths,Scrapy 提供 Selector 类, 有四种方法 :</p> <ul> <li>xpath():返回selectors列表, 每一个selector表示一个xpath参数表达式选择的节点.</li> <li>css() : 返回selectors列表, 每一个selector表示CSS参数表达式选择的节点</li> <li>extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据</li> <li>re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来</li> </ul> <p><strong>3.4.2. 取出数据<br /> </strong></p> <ul> <li>首先使用谷歌浏览器开发者工具, 查看网站源码, 来看自己需要取出的数据形式(这种方法比较麻烦), 更简单的方法是直接对感兴趣的东西右键审查元素, 可以直接查看网站源码</li> </ul> <p>在查看网站源码后, 网站信息在第二个<ul>内</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> <ul class="directory-url" style="margin-left:0;"> <li><a href="http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html" class="listinglink">Core Python Programming</a> - By Wesley J. Chun; Prentice Hall PTR, 2001, ISBN 0130260363. For experienced developers to improve extant skills; professional level examples. Starts by introducing syntax, objects, error handling, functions, classes, built-ins. [Prentice Hall] <div class="flag"><a href="/public/flag?cat=Computers%2FProgramming%2FLanguages%2FPython%2FBooks&url=http%3A%2F%2Fwww.pearsonhighered.com%2Feducator%2Facademic%2Fproduct%2F0%2C%2C0130260363%2C00%252Ben-USS_01DBC.html"><img src="/static/imghw/default1.png" data-src="/img/flag.png" class="lazy" alt="[!]" title="report an issue with this listing"></a></div> </li> ...省略部分... </ul> </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>那么就可以通过一下方式进行提取数据</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> #通过如下命令选择每个在网站中的 <li> 元素: sel.xpath('//ul/li') #网站描述: sel.xpath('//ul/li/text()').extract() #网站标题: sel.xpath('//ul/li/a/text()').extract() #网站链接: sel.xpath('//ul/li/a/@href').extract() </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>如前所述,每个 xpath() 调用返回一个 selectors 列表,所以我们可以结合 xpath() 去挖掘更深的节点。我们将会用到这些特性,所以:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> for sel in response.xpath('//ul/li') title = sel.xpath('a/text()').extract() link = sel.xpath('a/@href').extract() desc = sel.xpath('text()').extract() print title, link, desc </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>在已有的爬虫文件中修改代码</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): for sel in response.xpath('//ul/li'): title = sel.xpath('a/text()').extract() link = sel.xpath('a/@href').extract() desc = sel.xpath('text()').extract() print title, link, desc </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p><strong>3.4.3. 使用item<br /> </strong>Item对象是自定义的python字典,可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> >>> item = DmozItem() >>> item['title'] = 'Example title' >>> item['title'] 'Example title' </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>一般来说,Spider将会将爬取到的数据以 Item 对象返回, 最后修改爬虫类,使用 Item 来保存数据,代码如下</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> from scrapy.spider import Spider from scrapy.selector import Selector from tutorial.items import DmozItem class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/", ] def parse(self, response): sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = DmozItem() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s[^\n]*\\r') items.append(item) return items </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p><strong>3.5. 使用Item Pipeline<br /> </strong>当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。<br /> 每个item pipeline组件(有时称之为ItemPipeline)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。<br /> 以下是item pipeline的一些典型应用:</p> <ul> <li>清理HTML数据</li> <li>验证爬取的数据(检查item包含某些字段)</li> <li>查重(并丢弃)</li> <li>将爬取结果保存,如保存到数据库、XML、JSON等文件中</li> </ul> <p>编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法:</p> <p>(1)process_item(item, spider) #每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。</p> <p>#参数:</p> <p>item: 由 parse 方法返回的 Item 对象(Item对象)</p> <p>spider: 抓取到这个 Item 对象对应的爬虫对象(Spider对象)</p> <p>(2)open_spider(spider) #当spider被开启时,这个方法被调用。</p> <p>#参数:</p> <p>spider : (Spider object) – 被开启的spider</p> <p>(3)close_spider(spider) #当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。</p> <p>#参数:</p> <p>spider : (Spider object) – 被关闭的spider</p> <p>为JSON文件编写一个items</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> from scrapy.exceptions import DropItem class TutorialPipeline(object): # put all words in lowercase words_to_filter = ['politics', 'religion'] def process_item(self, item, spider): for word in self.words_to_filter: if word in unicode(item['description']).lower(): raise DropItem("Contains forbidden word: %s" % word) else: return item </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>在 settings.py 中设置ITEM_PIPELINES激活item pipeline,其默认为[]</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> ITEM_PIPELINES = {'tutorial.pipelines.FilterWordsPipeline': 1} </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p><strong>3.6. 存储数据<br /> </strong>使用下面的命令存储为json文件格式</p> <p>scrapy crawl dmoz -o items.json</p> <p><strong>4.示例<br /> 4.1最简单的spider(默认的Spider)<br /> </strong>用实例属性start_urls中的URL构造Request对象<br /> 框架负责执行request<br /> 将request返回的response对象传递给parse方法做分析</p> <p>简化后的源码:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> class Spider(object_ref): """Base class for scrapy spiders. All spiders must inherit from this class. """ name = None def __init__(self, name=None, **kwargs): if name is not None: self.name = name elif not getattr(self, 'name', None): raise ValueError("%s must have a name" % type(self).__name__) self.__dict__.update(kwargs) if not hasattr(self, 'start_urls'): self.start_urls = [] def start_requests(self): for url in self.start_urls: yield self.make_requests_from_url(url) def make_requests_from_url(self, url): return Request(url, dont_filter=True) def parse(self, response): raise NotImplementedError BaseSpider = create_deprecated_class('BaseSpider', Spider) </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>一个回调函数返回多个request的例子</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> import scrapyfrom myproject.items import MyItemclass MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ 'http://www.example.com/1.html', 'http://www.example.com/2.html', 'http://www.example.com/3.html', ] def parse(self, response): sel = scrapy.Selector(response) for h3 in response.xpath('//h3').extract(): yield MyItem(title=h3) for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse) </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>构造一个Request对象只需两个参数: URL和回调函数</p> <p><strong>4.2CrawlSpider<br /> </strong>通常我们需要在spider中决定:哪些网页上的链接需要跟进, 哪些网页到此为止,无需跟进里面的链接。CrawlSpider为我们提供了有用的抽象——Rule,使这类爬取任务变得简单。你只需在rule中告诉scrapy,哪些是需要跟进的。<br /> 回忆一下我们爬行mininova网站的spider.</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> class MininovaSpider(CrawlSpider): name = 'mininova' allowed_domains = ['mininova.org'] start_urls = ['http://www.mininova.org/yesterday'] rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')] def parse_torrent(self, response): torrent = TorrentItem() torrent['url'] = response.url torrent['name'] = response.xpath("//h1/text()").extract() torrent['description'] = response.xpath("//div[@id='description']").extract() torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract() return torrent </pre><div class="contentsignin">Copier après la connexion</div></div> </p> <p>上面代码中 rules的含义是:匹配/tor/\d+的URL返回的内容,交给parse_torrent处理,并且不再跟进response上的URL。<br /> 官方文档中也有个例子:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> rules = ( # 提取匹配 'category.php' (但不匹配 'subsection.php') 的链接并跟进链接(没有callback意味着follow默认为True) Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))), # 提取匹配 'item.php' 的链接并使用spider的parse_item方法进行分析 Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'), ) </pre><div class="contentsignin">Copier après la connexion</div></div> <p>除了Spider和CrawlSpider外,还有XMLFeedSpider, CSVFeedSpider, SitemapSpider</p> <p></p> </div> </div> </div> <div class="wzconShengming_sp"> <div class="bzsmdiv_sp">Déclaration de ce site Web</div> <div>Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn</div> </div> </div> <ins class="adsbygoogle" style="display:block" data-ad-format="autorelaxed" data-ad-client="ca-pub-5902227090019525" data-ad-slot="2507867629"></ins> <script> (adsbygoogle = window.adsbygoogle || []).push({}); </script> <div class="AI_ToolDetails_main4sR"> <ins class="adsbygoogle" style="display:block" data-ad-client="ca-pub-5902227090019525" data-ad-slot="3653428331" data-ad-format="auto" data-full-width-responsive="true"></ins> <script> (adsbygoogle = window.adsbygoogle || []).push({}); </script> <!-- <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>Article chaud</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780570.html" title="R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780641.html" title="R.E.P.O. Meilleurs paramètres graphiques" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Meilleurs paramètres graphiques</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796785841.html" title="Assassin's Creed Shadows: Solution d'énigmes de coquille" class="phpgenera_Details_mainR4_bottom_title">Assassin's Creed Shadows: Solution d'énigmes de coquille</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>2 Il y a quelques semaines</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780520.html" title="R.E.P.O. Comment réparer l'audio si vous n'entendez personne" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Comment réparer l'audio si vous n'entendez personne</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796779766.html" title="WWE 2K25: Comment déverrouiller tout dans Myrise" class="phpgenera_Details_mainR4_bottom_title">WWE 2K25: Comment déverrouiller tout dans Myrise</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/fr/article.html">Afficher plus</a> </div> </div> </div> --> <div class="phpgenera_Details_mainR3"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hottools2.png" alt="" /> <h2>Outils d'IA chauds</h2> </div> <div class="phpgenera_Details_mainR3_bottom"> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411540686492.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undresser.AI Undress" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_title"> <h3>Undresser.AI Undress</h3> </a> <p>Application basée sur l'IA pour créer des photos de nu réalistes</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411552797167.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Clothes Remover" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_title"> <h3>AI Clothes Remover</h3> </a> <p>Outil d'IA en ligne pour supprimer les vêtements des photos.</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173410641626608.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undress AI Tool" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_title"> <h3>Undress AI Tool</h3> </a> <p>Images de déshabillage gratuites</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411529149311.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Clothoff.io" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_title"> <h3>Clothoff.io</h3> </a> <p>Dissolvant de vêtements AI</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/ai/ai-hentai-generator" title="AI Hentai Generator" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173405034393877.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Hentai Generator" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/ai/ai-hentai-generator" title="AI Hentai Generator" class="phpmain_tab2_mids_title"> <h3>AI Hentai Generator</h3> </a> <p>Générez AI Hentai gratuitement.</p> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/fr/ai">Afficher plus</a> </div> </div> </div> <script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script> <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>Article chaud</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780570.html" title="R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780641.html" title="R.E.P.O. Meilleurs paramètres graphiques" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Meilleurs paramètres graphiques</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796785841.html" title="Assassin's Creed Shadows: Solution d'énigmes de coquille" class="phpgenera_Details_mainR4_bottom_title">Assassin's Creed Shadows: Solution d'énigmes de coquille</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>2 Il y a quelques semaines</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796780520.html" title="R.E.P.O. Comment réparer l'audio si vous n'entendez personne" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Comment réparer l'audio si vous n'entendez personne</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/1796779766.html" title="WWE 2K25: Comment déverrouiller tout dans Myrise" class="phpgenera_Details_mainR4_bottom_title">WWE 2K25: Comment déverrouiller tout dans Myrise</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4 Il y a quelques semaines</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/fr/article.html">Afficher plus</a> </div> </div> </div> <div class="phpgenera_Details_mainR3"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hottools2.png" alt="" /> <h2>Outils chauds</h2> </div> <div class="phpgenera_Details_mainR3_bottom"> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/toolset/development-tools/92" title="Bloc-notes++7.3.1" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab96f0f39f7357.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Bloc-notes++7.3.1" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/toolset/development-tools/92" title="Bloc-notes++7.3.1" class="phpmain_tab2_mids_title"> <h3>Bloc-notes++7.3.1</h3> </a> <p>Éditeur de code facile à utiliser et gratuit</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/toolset/development-tools/93" title="SublimeText3 version chinoise" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97a3baad9677.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 version chinoise" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/toolset/development-tools/93" title="SublimeText3 version chinoise" class="phpmain_tab2_mids_title"> <h3>SublimeText3 version chinoise</h3> </a> <p>Version chinoise, très simple à utiliser</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/toolset/development-tools/121" title="Envoyer Studio 13.0.1" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97ecd1ab2670.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Envoyer Studio 13.0.1" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/toolset/development-tools/121" title="Envoyer Studio 13.0.1" class="phpmain_tab2_mids_title"> <h3>Envoyer Studio 13.0.1</h3> </a> <p>Puissant environnement de développement intégré PHP</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/toolset/development-tools/469" title="Dreamweaver CS6" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d0e0fc74683535.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Dreamweaver CS6" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/toolset/development-tools/469" title="Dreamweaver CS6" class="phpmain_tab2_mids_title"> <h3>Dreamweaver CS6</h3> </a> <p>Outils de développement Web visuel</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/fr/toolset/development-tools/500" title="SublimeText3 version Mac" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d34035e2757995.png?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 version Mac" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/fr/toolset/development-tools/500" title="SublimeText3 version Mac" class="phpmain_tab2_mids_title"> <h3>SublimeText3 version Mac</h3> </a> <p>Logiciel d'édition de code au niveau de Dieu (SublimeText3)</p> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/fr/ai">Afficher plus</a> </div> </div> </div> <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>Sujets chauds</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/gmailyxdlrkzn" title="Où se trouve l'entrée de connexion pour la messagerie Gmail ?" class="phpgenera_Details_mainR4_bottom_title">Où se trouve l'entrée de connexion pour la messagerie Gmail ?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>7473</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>15</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/cakephp-tutor" title="Tutoriel CakePHP" class="phpgenera_Details_mainR4_bottom_title">Tutoriel CakePHP</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1377</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>52</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/steamdzhmcssmgs" title="Quel est le format du nom de compte de Steam" class="phpgenera_Details_mainR4_bottom_title">Quel est le format du nom de compte de Steam</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>77</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>11</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/winactivationkeyper" title="Clé d&amp;amp;amp;amp;amp;amp;#39;activation Win11 permanent" class="phpgenera_Details_mainR4_bottom_title">Clé d&amp;amp;amp;amp;amp;amp;#39;activation Win11 permanent</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>48</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>19</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/fr/faq/newyorktimesdailybrief" title="NYT Connexions Indices et réponses" class="phpgenera_Details_mainR4_bottom_title">NYT Connexions Indices et réponses</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>19</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>30</span> </div> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/fr/faq/zt">Afficher plus</a> </div> </div> </div> </div> </div> <div class="Article_Details_main2"> <div class="phpgenera_Details_mainL4"> <div class="phpmain1_2_top"> <a href="javascript:void(0);" class="phpmain1_2_top_title">Related knowledge<img src="/static/imghw/index2_title2.png" alt="" /></a> </div> <div class="phpgenera_Details_mainL4_info"> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792956.html" title="MySQL doit-il payer" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/27/2024122710314954443.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL doit-il payer" /> </a> <a href="https://www.php.cn/fr/faq/1796792956.html" title="MySQL doit-il payer" class="phphistorical_Version2_mids_title">MySQL doit-il payer</a> <span class="Articlelist_txts_time">Apr 08, 2025 pm 05:36 PM</span> <p class="Articlelist_txts_p">MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792845.html" title="Comment utiliser MySQL après l'installation" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174124098373422.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment utiliser MySQL après l'installation" /> </a> <a href="https://www.php.cn/fr/faq/1796792845.html" title="Comment utiliser MySQL après l'installation" class="phphistorical_Version2_mids_title">Comment utiliser MySQL après l'installation</a> <span class="Articlelist_txts_time">Apr 08, 2025 am 11:48 AM</span> <p class="Articlelist_txts_p">L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792826.html" title="MySQL ne peut pas être installé après le téléchargement" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/465/014/174125286330709.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL ne peut pas être installé après le téléchargement" /> </a> <a href="https://www.php.cn/fr/faq/1796792826.html" title="MySQL ne peut pas être installé après le téléchargement" class="phphistorical_Version2_mids_title">MySQL ne peut pas être installé après le téléchargement</a> <span class="Articlelist_txts_time">Apr 08, 2025 am 11:24 AM</span> <p class="Articlelist_txts_p">Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792821.html" title="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174125358798898.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" /> </a> <a href="https://www.php.cn/fr/faq/1796792821.html" title="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" class="phphistorical_Version2_mids_title">Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution</a> <span class="Articlelist_txts_time">Apr 08, 2025 am 11:21 AM</span> <p class="Articlelist_txts_p">Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792888.html" title="MySQL a-t-il besoin d'Internet" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202501/09/2025010911214941664.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL a-t-il besoin d'Internet" /> </a> <a href="https://www.php.cn/fr/faq/1796792888.html" title="MySQL a-t-il besoin d'Internet" class="phphistorical_Version2_mids_title">MySQL a-t-il besoin d'Internet</a> <span class="Articlelist_txts_time">Apr 08, 2025 pm 02:18 PM</span> <p class="Articlelist_txts_p">MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792841.html" title="Comment optimiser les performances de la base de données après l'installation de MySQL" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174124566531558.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment optimiser les performances de la base de données après l'installation de MySQL" /> </a> <a href="https://www.php.cn/fr/faq/1796792841.html" title="Comment optimiser les performances de la base de données après l'installation de MySQL" class="phphistorical_Version2_mids_title">Comment optimiser les performances de la base de données après l'installation de MySQL</a> <span class="Articlelist_txts_time">Apr 08, 2025 am 11:36 AM</span> <p class="Articlelist_txts_p">L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792966.html" title="Comment optimiser les performances MySQL pour les applications de haute charge?" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/246/273/173518851168623.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment optimiser les performances MySQL pour les applications de haute charge?" /> </a> <a href="https://www.php.cn/fr/faq/1796792966.html" title="Comment optimiser les performances MySQL pour les applications de haute charge?" class="phphistorical_Version2_mids_title">Comment optimiser les performances MySQL pour les applications de haute charge?</a> <span class="Articlelist_txts_time">Apr 08, 2025 pm 06:03 PM</span> <p class="Articlelist_txts_p">Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/fr/faq/1796792815.html" title="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/000/164/174125574360343.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" /> </a> <a href="https://www.php.cn/fr/faq/1796792815.html" title="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" class="phphistorical_Version2_mids_title">Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL</a> <span class="Articlelist_txts_time">Apr 08, 2025 am 11:18 AM</span> <p class="Articlelist_txts_p">MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration</p> </div> </div> <a href="https://www.php.cn/fr/be/" class="phpgenera_Details_mainL4_botton"> <span>See all articles</span> <img src="/static/imghw/down_right.png" alt="" /> </a> </div> </div> </div> </main> <footer> <div class="footer"> <div class="footertop"> <img src="/static/imghw/logo.png" alt=""> <p>Formation PHP en ligne sur le bien-être public,Aidez les apprenants PHP à grandir rapidement!</p> </div> <div class="footermid"> <a href="https://www.php.cn/fr/about/us.html">À propos de nous</a> <a href="https://www.php.cn/fr/about/disclaimer.html">Clause de non-responsabilité</a> <a href="https://www.php.cn/fr/update/article_0_1.html">Sitemap</a> </div> <div class="footerbottom"> <p> © php.cn All rights reserved </p> </div> </div> </footer> <input type="hidden" id="verifycode" value="/captcha.html"> <script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script> <script src="/static/js/common_new.js"></script> <script type="text/javascript" src="/static/js/jquery.cookie.js?1744457705"></script> <script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script> <link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all' /> <script type='text/javascript' src='/static/js/viewer.min.js?1'></script> <script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script> <script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script> <script> var _paq = window._paq = window._paq || []; /* tracker methods like "setCustomDimension" should be called before "trackPageView" */ _paq.push(['trackPageView']); _paq.push(['enableLinkTracking']); (function () { var u = "https://tongji.php.cn/"; _paq.push(['setTrackerUrl', u + 'matomo.php']); _paq.push(['setSiteId', '9']); var d = document, g = d.createElement('script'), s = d.getElementsByTagName('script')[0]; g.async = true; g.src = u + 'matomo.js'; s.parentNode.insertBefore(g, s); })(); </script> <script> // top layui.use(function () { var util = layui.util; util.fixbar({ on: { mouseenter: function (type) { layer.tips(type, this, { tips: 4, fixed: true, }); }, mouseleave: function (type) { layer.closeAll("tips"); }, }, }); }); document.addEventListener("DOMContentLoaded", (event) => { // 定义一个函数来处理滚动链接的点击事件 function setupScrollLink(scrollLinkId, targetElementId) { const scrollLink = document.getElementById(scrollLinkId); const targetElement = document.getElementById(targetElementId); if (scrollLink && targetElement) { scrollLink.addEventListener("click", (e) => { e.preventDefault(); // 阻止默认链接行为 targetElement.scrollIntoView({ behavior: "smooth" }); // 平滑滚动到目标元素 }); } else { console.warn( `Either scroll link with ID '${scrollLinkId}' or target element with ID '${targetElementId}' not found.` ); } } // 使用该函数设置多个滚动链接 setupScrollLink("Article_Details_main1L2s_1", "article_main_title1"); setupScrollLink("Article_Details_main1L2s_2", "article_main_title2"); setupScrollLink("Article_Details_main1L2s_3", "article_main_title3"); setupScrollLink("Article_Details_main1L2s_4", "article_main_title4"); setupScrollLink("Article_Details_main1L2s_5", "article_main_title5"); setupScrollLink("Article_Details_main1L2s_6", "article_main_title6"); // 可以继续添加更多的滚动链接设置 }); window.addEventListener("scroll", function () { var fixedElement = document.getElementById("Article_Details_main1Lmain"); var scrollTop = window.scrollY || document.documentElement.scrollTop; // 兼容不同浏览器 var clientHeight = window.innerHeight || document.documentElement.clientHeight; // 视口高度 var scrollHeight = document.documentElement.scrollHeight; // 页面总高度 // 计算距离底部的距离 var distanceToBottom = scrollHeight - scrollTop - clientHeight; // 当距离底部小于或等于300px时,取消固定定位 if (distanceToBottom <= 980) { fixedElement.classList.remove("Article_Details_main1Lmain"); fixedElement.classList.add("Article_Details_main1Lmain_relative"); } else { // 否则,保持固定定位 fixedElement.classList.remove("Article_Details_main1Lmain_relative"); fixedElement.classList.add("Article_Details_main1Lmain"); } }); </script> </body> </html>