
 développement back-end
tutoriel php
Historique du développement de l'architecture financière de l'Internet de zéro à des dizaines de milliards
développement back-end
tutoriel php
Historique du développement de l'architecture financière de l'Internet de zéro à des dizaines de milliards
Historique du développement de l'architecture financière de l'Internet de zéro à des dizaines de milliards

Rappelant que cela fait presque trois ans depuis la création de la première ligne de code depuis la création de l'entreprise, l'architecture technique et le système technique de la plateforme ont également subi quatre mises à niveau et transformations majeures (le système d'architecture de quatrième génération est actuellement en cours), comme À l'approche de la fin de l'année, je souhaite également prendre le temps de passer en revue les changements technologiques derrière une petite entreprise, depuis zéro transaction au début jusqu'à un volume de transactions de plus de 10 milliards.
Introduction générale
Dans le secteur financier sur Internet, qui compte plus de 10 milliards de yuans, il ne s'agit pas en réalité d'une grande plate-forme, c'est-à-dire d'un camp de second rang. En fait, chaque mise à niveau de l'architecture s'accompagne d'avancées commerciales majeures. l'architecture système de la génération précédente. Certains excellents cas de développement ont été accumulés au cours du processus de développement commercial, et les mises à niveau de l'architecture seront vigoureusement encouragées dans le développement des systèmes de nouvelle génération. D'une part, cela peut faciliter la transition, d'autre part, les ressources de l'entreprise peuvent fournir un soutien solide, et en même temps, les partenaires techniques peuvent utiliser une technologie de pointe et avoir un plus grand sentiment d'accomplissement dans le développement. de cette façon, nous pouvons mettre à niveau l’architecture du système une fois tous les 9 mois environ vers notre structure actuelle.
De nombreux internautes demandent souvent quel est le TPS de votre plateforme, quelle est la simultanéité maximale et quelles sont les performances. Pour être honnête, nous sommes une petite entreprise, et le plus exagéré est que des dizaines de milliers de personnes se disputent des offres ? en même temps, mais en tant qu'Internet de taille moyenne, la plateforme financière a vraiment beaucoup de choses à faire, et bien plus que ces paramètres qui peuvent être clairement énoncés, nous ne sommes pas une plateforme haut de gamme ; , et la technologie que nous utilisons est également un produit open source relativement courant à l'heure actuelle, mais dans le processus de développement continu de l'entreprise, j'ai également rencontré de nombreux problèmes et j'ai fait de mon mieux pour utiliser des solutions open source plus courantes qui nous permettent de construire l'ensemble du système. J'aimerais partager les changements dans les mises à niveau technologiques derrière le développement de la plate-forme. J'espère également avoir plus d'échanges avec vous. Faites quelques suggestions.
Nous avons apporté quatre changements architecturaux majeurs, et chaque génération d'architecture est résumée en une phrase :
Caractéristiques de l'architecture de première génération : l'activité est relativement concentrée, les fonctions répondent aux besoins d'investissement et de gestion financière et peuvent être lancées rapidement
Caractéristiques de l'architecture de deuxième génération : transformation des systèmes distribués, plate-forme commençant à prendre forme, divers systèmes commerciaux verticaux étant construits et lancés, côté produit enrichissant considérablement l'investissement des utilisateurs, et recherche et utilisation de plates-formes Big Data.
Caractéristiques de l'architecture SOA de troisième génération, utilisant zookeeper comme centre d'enregistrement, dubbo comme centre de surveillance et de répartition, pour réaliser une authentification unique, utilisant shiro pour le contrôle des autorisations ;
Caractéristiques de l'architecture de quatrième génération : activer pleinement le modèle de développement de microservices, avec la technologie springboot et springcloud comme support technique pour l'architecture de quatrième génération
Présentation détaillée ci-dessous
Architecture système de première génération
2014 doit être considérée comme la première année de la finance Internet. En fait, de nombreuses sociétés Internet utilisaient différents modèles pour survivre, mais elles ont été timides en 2014. La première était Pingdaizhijia et Pingdao Tianyan. . Ce type de trafic sur les sites Web tiers a soudainement augmenté, puis les médias ont continué à suivre. Plus tard, il y a eu de plus en plus de rapports sur diverses sociétés financières sur Internet recevant XXX dollars américains d'investissement, et les politiques sont progressivement devenues claires, de sorte que de nombreuses sociétés financières sur Internet ont reçu des investissements de XXX dollars américains. de grandes entreprises (groupes) ont également profité de cet engouement pour donner suite, dont nous.
L'objectif principal du système de première génération était de gagner du temps. L'entreprise espérait que le système soit en ligne dans les plus brefs délais. À ce moment-là, la vague mobile avait déjà commencé, il a donc été décidé de donner la priorité au lancement de. la version mobile et le site internet ne peuvent être envisagés pour le moment. À cette époque, l'entreprise disposait de réserves techniques dans deux langages de développement, PHP et Java. Parce que PHP présentait de grands avantages en matière de développement rapide, elle a décidé d'adopter le modèle PHP front-end et Java back-end. Le système est divisé en trois couches : Couche utilisateur : terminaux mobiles Android et IOS ; Couche interface : PHP fournit des interfaces utilisateur et de transaction ; Backend : Le backend comporte deux parties, l'arrière-plan et le système de synchronisation. Le backend utilise le développement PHP et la couche d'interface pour partager un système, et l'autre est un système de chronométrage, responsable des tâches de chronométrage telles que le calcul des intérêts, la distribution des dividendes, l'expiration, etc., et est développé en Java.
Pour les services de base et le middleware, MySQL fournit la prise en charge maître-esclave la plus élémentaire. Le système de première génération utilise uniquement la base de données principale de MySQL, et la base de données esclave n'est utilisée que pour la sauvegarde synchrone et est utilisée pour gérer le problème de concurrence de l'utilisateur. enchères, et seule cette partie est utilisée ;ActiveMQ est utilisé pour utiliser la correspondance de transfert sur le marché secondaire et d'autres notifications de messages asynchrones. Déploiement du projet : PHP est déployé à l'aide d'Apache, le service de synchronisation utilise Tomcat6 comme serveur d'applications et lvs est utilisé comme charge Apache frontale. Fondamentalement, ces technologies sont la première génération. Voici le schéma d'architecture de la première génération. système.

Après le lancement du système de première génération, la construction de sites Web et de systèmes H5 (navigateur mobile ou WeChat) est devenue particulièrement importante. En tant que société financière sur Internet, elle ne pouvait supporter de ne pas avoir de site Web officiel, elle a donc commencé à développer des sites Web et H5. systèmes non-stop. Au cours de cette période, le backend que PHP avait précédemment réalisé a été supprimé et replanifié en utilisant Java. Jusqu'à présent, PHP est responsable des trois systèmes de site Web, d'interface APP et d'une transaction de base partagée. par les trois systèmes, Java est responsable du backend Pour les services de gestion et de synchronisation, nous appelons généralement cette architecture l'architecture de génération 1.1.

Schéma d'architecture du système génération 1.1, la partie verte est la partie modifiée
Les inconvénients du système de première génération sont que l'activité est trop concentrée, qu'elle est lancée à la hâte et qu'il y a de nombreux problèmes dans la période ultérieure.
Architecture système de deuxième génération
Le contexte du système de deuxième génération est qu'avec le développement rapide du volume d'affaires de l'entreprise, de nombreuses dettes techniques dues au début ont explosé et de nombreux problèmes sont apparus en ligne, le plus grave étant le paiement répété de dividendes aux particuliers. utilisateurs, et ils ont été réprimandés de diverses manières, le souvenir est encore frais maintenant. D'un autre côté, les différents départements commerciaux ont des demandes constantes et les produits de l'entreprise sont en demande constante, donc à ce stade, ils sont occupés à résoudre divers problèmes de production, tout en développant également des systèmes commerciaux verticaux. J'étais presque devenu fou pendant cette période. Le système de première génération a été développé de manière fermée. Je ne me suis toujours pas remis de mon stress lorsque je suis revenu pour le remettre sur le marché. heureux.
Le premier sous-système vertical mis en ligne était le système de contrat. À cette époque, il n'y avait pas de contrat après que les utilisateurs aient soumis des offres. De nombreux utilisateurs étaient très inquiets et accordaient la priorité. Plus tard, le système de contrat à lui seul a été modifié en trois versions. La première version générait uniquement des PDF, la deuxième phase a lancé des signatures électroniques et la troisième phase a ajouté des filigranes pour personnaliser et générer dynamiquement des PDF, puis a développé un système de points : invitation de l'utilisateur, investissement et ; d'autres points de production peuvent être utilisés pour échanger des bons d'achat, etc. ; extraire le système de messagerie : messages du site, messages texte, e-mails, etc. ; lancer le système de surveillance en ligne, la surveillance des activités et la surveillance des services, ainsi que l'alerte précoce en cas de défaillance commerciale ; le département commercial continuera d'augmenter les demandes et de se mettre en ligne. Système financier : le personnel financier calcule les montants ; système de contrôle des risques : surveille les utilisateurs anormaux et les transactions anormales et développe un système d'accès externe car il s'interface avec de nombreux tiers ; systèmes.
Le système de première génération a été construit à la hâte et l'interface du produit était épouvantable. Ensuite, nous avons commencé à planifier le site Web 2.0, APP2.0 et H52.0. En réponse aux besoins du système frontal, nous avons développé un CMS. système sur le back-end pour publier les annonces de projets et d'entreprises, les actualités, etc. ; Le côté produit de deuxième génération prévoit généralement de nombreux besoins d'analyse de données volumineuses. Il affichera sur le site officiel où les préférences d'investissement et les montants d'investissement seront complets. analyse des données. Le front-end utilise une carte pour l'afficher, et il y aura également des remboursements pour les particuliers, une analyse des données collectées, etc., car ils ont besoin d'exécuter la totalité des données, elles sont conçues pour être traitées hors ligne. pendant la planification. Les données sont synchronisées de la bibliothèque esclave mysql vers le cluster mongodb, et la technologie mapreduce de mongdo est utilisée pour traiter de grandes quantités de données. Notre couche de base de données devient l'architecture suivante.

Mysql est synchronisé avec mongodb en temps réel. Nous utilisons l'outil tungsten-relicator, qui démarrera un agent de surveillance côté serveur mysql pour surveiller le journal binlog de mysql en temps réel, un service est également démarré côté serveur mongodb. Du côté client, l'agent surveille les modifications de données et les envoie au serveur. Le serveur les analyse et les insère dans le cluster mongodb pour obtenir une synchronisation en temps réel, comme indiqué dans le fichier. photo ci-dessus. J'ai initialement écrit un article pour le présenter : Article sur la synchronisation des données sur les pratiques du Big Data tungsten-relicator (mysql->mongo) , en fait, cet outil n'est pas particulièrement stable à l'usage, mais là Il n'y avait pas beaucoup d'options au début. Heureusement, il est devenu stable après que je m'y sois progressivement familiarisé.
Nous avons utilisé avec audace Golang pour développer le système de nettoyage des données. La version de Golang que nous utilisions à l'époque était la 1.3, mais maintenant elle est la 1.8. Je n'y avais jamais été exposé auparavant et cela a également formé l'équipe. est très simple et efficace, même si j'ai marché sur le N. Il y avait beaucoup d'embûches, mais à la fin nous l'avons mis en production à temps ; plus tard, nous avons utilisé Golang pour développer un backend, basé sur le framework beego ; Le système d'analyse des mégadonnées a ensuite été mis à niveau vers une autre génération.Dans chaque système d'entreprise frontal, la couche utilisateur de l'interface utilisateur a déployé de nombreux efforts pour collecter les données des utilisateurs. Elle les a reçues via la transmission activeMQ et les a finalement stockées dans mongodb. données, les résultats nettoyés ont été stockés dans la base de données de résultats pour être utilisés par le système commercial frontal ; plus tard, une nouvelle version du système d'analyse des données a été construite à l'aide de beego echart.
Schéma d'architecture du système Big Data

Parce que la pression sur la base de données back-end continue d'augmenter, le système de gestion back-end et le système d'entreprise ont été séparés du maître et de l'esclave ; le système de gestion back-end a ajouté du cache et démarré Redis pour la mise en cache d'un serveur d'images indépendant ; a été construit à l'aide de nginx ; développement de systèmes de deuxième génération. Au cours du processus, il s'agissait également de l'étape de croissance la plus rapide de l'entreprise, avec de nombreuses activités lancées en ligne.
Schéma d'architecture système de deuxième génération :

Résumons dans un instant :
L'architecture de deuxième génération a lancé divers systèmes commerciaux, séparé le maître et l'esclave, et construit une plate-forme Big Data pour fournir une base technique pour davantage de traitement de données à l'avenir
Inconvénients : une fois chaque système d'entreprise divisé, les appels entre chaque projet sont compliqués ; il existe de nombreux systèmes back-end et il existe des systèmes de comptes distincts entre chaque système. Les opérations doivent basculer d'un côté à l'autre pour compléter la surveillance des opérations de la plate-forme.
architecture système de troisième génération
Une fois le développement du système de deuxième génération terminé, nous nous sommes retrouvés avec trois problèmes douloureux. Le premier était qu'à mesure que les systèmes d'entreprise continuaient à se développer, les relations d'appel entre les systèmes augmentaient de façon exponentielle. Nous avons développé De nombreux composants de base ont été ajoutés, aggravant ce problème ; le deuxième problème est complémentaire au premier problème, et il y a trop de relations d'appel entre les systèmes. Si vous déplacez l'un des sous-systèmes, vous devrez peut-être modifier le fichier de configuration de. le système associé et redémarrer le service. , souvent en raison de la mise à jour d'un système, d'autres systèmes doivent également être mis à jour passivement, ce qui complique la mise en production et le changement lorsque des problèmes surviennent ; systèmes finaux, mais les comptes ne sont pas unifiés. Chaque sous-système a son propre centre de comptes et le personnel opérationnel doit se connecter d'avant en arrière pour effectuer son travail quotidien. À mesure que le volume d'affaires augmente, ce problème devient de plus en plus important.
Nous avons donc commencé la recherche et la sélection de systèmes, etc. Le premier problème à résoudre était d'introduire la gouvernance des services SOA et de résoudre le découplage entre les systèmes via l'enregistrement et la découverte des services. Nous avons beaucoup étudié à cette époque et avons finalement sélectionné Dubbo pour aucune autre raison que A. un grand nombre de personnes marchaient sur l’eau en utilisant l’eau de base. Pour résoudre le deuxième problème, nous avons introduit le centre de configuration. À cette époque, nous avons étudié Qihoo360/QConf de Spring, Spring-cloud-config, Taobao Diamond et Baidu Disconf. Enfin, après avoir longtemps lutté, nous avons choisi Disconf. ce qui était parfait pour Spring Cloud, nous l'avons ignoré, mais c'est à partir de là que nous avons remarqué que spring-cloud et Spring-boot ont jeté les bases de la sélection d'architecture de quatrième génération. En fait, en fin de compte, disconf n'a été utilisé que dans. un petit nombre de projets et n'a pas été entièrement promu ; le troisième problème est résolu par le centre de compte, qui utilise cas pour implémenter l'authentification unique, shiro pour le contrôle des autorisations et dubbo pour fournir des interfaces serveur telles que la liste des autorisations après la connexion.
Schéma d'architecture après transformation

Sur cette base, nous avons extrait de nombreux composants de base. Le composant coomn gère les classes de base communes, notamment les classes de caractères, les classes de date, les classes de chiffrement..., nous avons construit un cluster fastDFS pour traiter le système de fichiers et construit un cluster redis Testing ; a développé indépendamment un système de planification planifiée, intégrant toutes les tâches planifiées dans le système de planification. Quel que soit le système nécessitant des tâches planifiées, il peut automatiquement ajouter des stratégies de planification à la page ; le PHP frontal a effectué des transformations du système, une séparation maître-esclave, une optimisation statique, etc.
Plus tard, l'entreprise a commencé la construction d'une plate-forme de financement participatif. Cette fois, le système a été entièrement développé en langage Java et le côté application a adopté un modèle de développement hybride. Toutes les pages de premier niveau de l'APP ont été développées de manière native et toutes les pages de deuxième niveau. les pages ont été développées en utilisant H5 vue. Dans ce modèle, tous les backends utilisent dubbo pour le service. L'architecture finale est la suivante :

Dans la figure, seule une partie du système est répertoriée et d'autres services sont utilisés à la place.
Le système de troisième génération a lancé la gouvernance des services SOA et introduit un centre de comptes unifié et des composants de base ; l'inconvénient est que l'environnement de développement est plus complexe ;
Architecture système de quatrième génération
Les gens sont toujours insatisfaits et la technologie espère toujours utiliser la meilleure architecture système.Au cours du développement de l'architecture système de troisième génération, j'ai découvert Spring Cloud et Spring Boot.Après un apprentissage continu, j'ai pris de plus en plus conscience de la commodité de. spring boot.J'aime beaucoup les avantages du développement rapide.Le système Spring Cloud répond également pleinement à tous les aspects qui doivent être pris en compte dans un grand système.Le concept de microservices est constamment proposé. D'autre part, le pays a commencé à exiger strictement que les entreprises P2P aient des dépôts auprès des banques. Après avoir analysé les interfaces bancaires pertinentes, nous avons constaté que si nous suivons strictement les règles, notre système nécessite en même temps une transformation majeure. Pour répondre aux exigences réglementaires, la société a également développé des produits liés à Baitiao, qui constituent également un grand projet. Tirant parti des deux contextes ci-dessus, nous avons décidé d'adopter pleinement les microservices tout en travaillant sur les projets de dépôt bancaire et de Baitiao.
Quant à la raison pour laquelle nous abandonnons Dubbo et adoptons pleinement Spring Cloud, il y a trois raisons : 1. Dubbo n'a pas été mis à jour depuis de nombreuses années et Spring Cloud est constamment mis à jour et mis à niveau. 2. Dubbo s'occupe principalement de la gestion et de la surveillance des services, et Spring. Le cloud prend presque en compte tous les microservices. Il nécessite tous les aspects, tels qu'un centre de configuration unifié et un centre de routage ; 3. Spring Cloud est non intrusif et parfaitement intégré aux autres projets Spring, ce qui rend le développement plus efficace.
Maintenant que nous avons choisi d'utiliser Spring Boot Spring Cloud pour la transformation, le choix de la technologie des microservices a été décidé. Alors, comment démarrer la transformation? Après tout, l'activité d'origine ne peut pas être affectée lors de la transformation du système de nouvelle génération. Le problème est que même si les systèmes initiaux ont été développés selon le modèle de développement distribué, certains systèmes partagent toujours une base de données en raison de l'ancien système. Les microservices nécessitent que chaque sous-système indépendant ait son propre fonctionnement de bibliothèque indépendant. Autres systèmes Si vous devez modifier. ou interroger les données du sous-système, vous devez les obtenir en appelant l'interface interservices. Par conséquent, nous prévoyons de démarrer le projet springcloud à partir de projets nouvellement développés et de projets qui doivent être transformés. D'autres systèmes communiqueront temporairement via le mode routeur. Le schéma final de l'architecture du système est le suivant :

Il n'y a pas de fin sur le chemin de l'architecture. Le changement est éternel. La mise à niveau de l'architecture consiste à mieux soutenir l'entreprise.

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
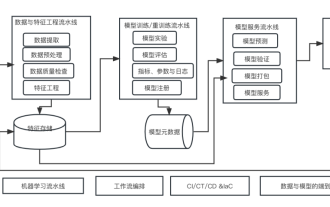 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
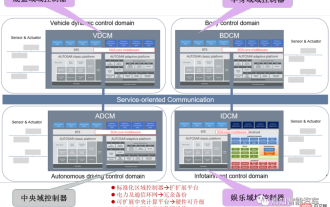 Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Pour la prochaine génération d'architecture électronique et électrique centralisée, l'utilisation d'une unité centrale de calcul centrale + zonale et d'une disposition de contrôleur régional est devenue une option incontournable pour divers OEM ou acteurs de niveau 1. Concernant l'architecture de l'unité centrale de calcul, il y en a trois. façons : séparation SOC, isolation matérielle, virtualisation logicielle. L'unité informatique centrale centralisée intégrera les fonctions commerciales de base des trois principaux domaines de la conduite autonome, du cockpit intelligent et du contrôle des véhicules. Le contrôleur régional standardisé a trois responsabilités principales : la distribution d'énergie, les services de données et la passerelle régionale. L’unité centrale de calcul intégrera donc un commutateur Ethernet haut débit. À mesure que le degré d'intégration de l'ensemble du véhicule devient de plus en plus élevé, de plus en plus de fonctions ECU seront lentement absorbées par le contrôleur régional. Et la plateforme
 Infrastructure d'IA : l'importance de la collaboration entre les équipes informatiques et scientifiques des données
May 18, 2023 pm 11:08 PM
Infrastructure d'IA : l'importance de la collaboration entre les équipes informatiques et scientifiques des données
May 18, 2023 pm 11:08 PM
L’intelligence artificielle (IA) a changé la donne dans de nombreux secteurs, permettant aux entreprises d’améliorer leur efficacité, leur prise de décision et leur expérience client. Alors que l’IA continue d’évoluer et de devenir plus complexe, il est essentiel que les entreprises investissent dans la bonne infrastructure pour soutenir son développement et son déploiement. Un aspect clé de cette infrastructure est la collaboration entre les équipes informatiques et de science des données, car toutes deux jouent un rôle essentiel pour garantir le succès des initiatives d'IA. Le développement rapide de l’intelligence artificielle a conduit à une demande croissante en matière de puissance de calcul, de stockage et de capacités réseau. Cette demande exerce une pression sur l’infrastructure informatique traditionnelle, qui n’a pas été conçue pour gérer les charges de travail complexes et gourmandes en ressources requises par l’IA. En conséquence, les entreprises cherchent désormais à créer des systèmes capables de prendre en charge les charges de travail d’IA.
