

Chapitre d'amélioration Java (vingt)-----Rassembler une grande famille

Lors de l'écriture de programmes Java, en plus des huit types de données de base et des objets String, nous utilisons le plus souvent une classe de collection. Les classes de collection sont partout dans nos programmes ! Il y a tellement de membres de la famille des collections en Java, y compris les ArrayList, HashMap et HashSet couramment utilisés, ainsi que les moins couramment utilisés Stack et Queue, les thread-safe Vector et HashTable et les thread-unsafe LinkedList, TreeMap. , etc.!
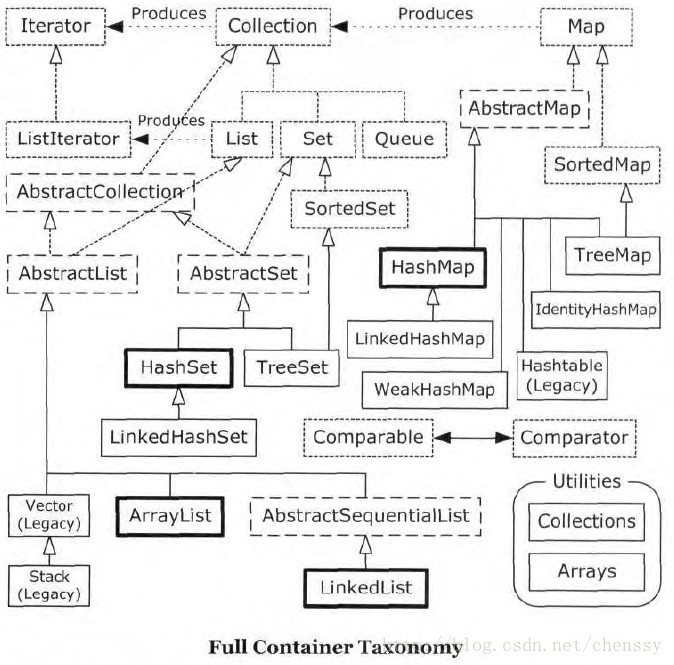
Les membres de toute la famille de la collection et les relations entre eux. Vous trouverez ci-dessous une brève introduction à chacune des interfaces et classes de base ci-dessus (présentant principalement les caractéristiques et les différences de chaque collection). Une introduction plus détaillée sera expliquée une par une dans un avenir proche.
1. Interface de collection
L'interface de collection est l'interface de collection la plus basique Non. une implémentation directe est fournie. Les classes fournies par le SDK Java sont toutes des « sous-interfaces » héritées de Collection, telles que List et Set. La collection représente une règle et les éléments qu'elle contient doivent suivre une ou plusieurs règles. Par exemple, certains autorisent la duplication et d'autres ne le peuvent pas, certains doivent être insérés dans l'ordre et certains ont des hachages, certains prennent en charge le tri mais d'autres non.
En Java, toutes les classes qui implémentent l'interface Collection doivent fournir deux ensembles de constructeurs standards, un sans paramètres, utilisé pour créer une Collection vide, l'un est un constructeur paramétré avec des paramètres Collection, utilisé pour créer une nouvelle Collection. Cette nouvelle Collection a les mêmes éléments que la Collection transmise.
2. Interface de liste
L'interface de liste est l'interface directe de Collection. List représente une collection ordonnée, c'est-à-dire qu'elle utilise un ordre d'insertion spécifique pour conserver l'ordre des éléments. Les utilisateurs ont un contrôle précis sur l'endroit où chaque élément de la liste est inséré et peuvent accéder aux éléments en fonction de leur index entier (position dans la liste) et rechercher des éléments dans la liste. Les collections qui implémentent l'interface List incluent principalement : ArrayList, LinkedList, Vector et Stack.
2.1, ArrayList
ArrayList est un tableau dynamique et est également notre tableau le plus couramment utilisé un rassemblement. Il permet l'insertion de tout élément conforme aux règles, même nul. Chaque ArrayList a une capacité initiale (10), qui représente la taille du tableau. À mesure que les éléments contenus dans le conteneur continuent d’augmenter, la taille du conteneur augmentera également. Chaque fois qu'un élément est ajouté au conteneur, la capacité est vérifiée. Lorsqu'il est sur le point de déborder, la capacité est augmentée. Donc si l'on connaît le nombre d'éléments à insérer, il est préférable de préciser une valeur de capacité initiale pour éviter des opérations d'expansion excessives qui font perdre du temps et de l'efficacité .
Les opérations size, isEmpty, get, set, iterator et listIterator s'exécutent toutes à une heure fixe. L'opération d'ajout s'exécute en temps constant amorti, c'est-à-dire que l'ajout de n éléments prend un temps O(n) (en raison de considérations de mise à l'échelle, ce n'est pas aussi simple que d'ajouter des éléments avec un coût en temps constant amorti).
ArrayList est bon en accès aléatoire. En même temps, ArrayList est asynchrone.
2.2, LinkedList
LinkedList, qui implémente également l'interface List, est différent de ArrayList. ArrayList est un tableau dynamique et LinkedList est une liste doublement chaînée. Ainsi, en plus des méthodes de fonctionnement de base d'ArrayList, il fournit également des méthodes supplémentaires d'obtention, de suppression et d'insertion en tête ou à la fin de LinkedList.
En raison de différentes méthodes d'implémentation, LinkedList n'est pas accessible de manière aléatoire et toutes ses opérations doivent être effectuées en fonction des besoins d'une liste doublement chaînée. Les opérations d'indexation dans une liste parcourront la liste depuis le début ou la fin (depuis la fin la plus proche de l'index spécifié). L'avantage est que les opérations d'insertion et de suppression peuvent être effectuées dans la Liste à moindre coût.
Comme ArrayList, LinkedList est également asynchrone. Si plusieurs threads accèdent à une liste en même temps, ils doivent implémenter eux-mêmes la synchronisation des accès. Une solution consiste à construire une liste synchronisée lors de la création de la liste :
List list = Collections.synchronizedList(new LinkedList(...));
🎜>2.3 . Vector
est similaire à ArrayList, mais Vector est synchronisé. Vector est donc un tableau dynamique thread-safe. Son fonctionnement est presque le même que celui d'ArrayList.
2.4, Stack
Stack hérite de Vector, implémentant un dernier-en- pile de premier sorti. Stack fournit 5 méthodes supplémentaires qui permettent d'utiliser Vector comme pile. Les méthodes de base push et pop, ainsi que la méthode peek, placent l'élément en haut de la pile, la méthode vide teste si la pile est vide et la méthode de recherche détecte la position d'un élément dans la pile. La pile est une pile vide après sa création.
3. Interface d'ensemble
Set est une collection qui n'inclut pas d'éléments répétés . Il conserve son propre ordre interne, donc l'accès aléatoire n'a aucun sens. Comme List, il accepte également la présence de null mais d'un seul. En raison de la particularité de l'interface Set, tous les éléments transmis dans la collection Set doivent être différents. En même temps, il convient de prêter attention à tout objet mutable si e1.equals(e2)==true est provoqué lors de l'opération sur le. éléments de la collection, il faut que certains problèmes surgissent. Les collections qui implémentent l'interface Set incluent : EnumSet, HashSet et TreeSet.
3.1, EnumSet
est un ensemble dédié à l'énumération. Tous les éléments sont des types d’énumération.
3.2, HashSet
HashSet peut être appelé l'ensemble de requêtes le plus rapide, car il est implémenté en interne avec HashCode. L'ordre de ses éléments internes est déterminé par le code de hachage, il ne garantit donc pas l'ordre d'itération de l'ensemble notamment, il ne garantit pas que l'ordre soit permanent ;
3.3, TreeSet
Basé sur TreeMap, générez un arbre toujours trié set est implémenté en interne avec TreeMap. Il trie les éléments selon leur ordre naturel, ou selon le fourni lors de la création du Set, selon le constructeur utilisé. Comparator
4. Interface de la carte
La carte est différente des interfaces List et Set, elle est une collection composée d'une série de paires clé-valeur, fournissant un mappage de la clé à la valeur. En même temps, il n’hérite pas de Collection. Dans Map, il assure une correspondance biunivoque entre la clé et la valeur. C'est-à-dire qu'une clé correspond à une valeur, elle ne peut donc pas avoir la même valeur clé, mais bien sûr la valeur valeur peut être la même. Les implémentations de map incluent : HashMap, TreeMap, HashTable, Properties et EnumMap.
4.1, HashMap
est implémenté avec une structure de données de table de hachage, et la fonction de hachage est utilisée pour calculer l'objet lors de sa recherche d'emplacement, il est conçu pour une requête rapide. Il définit un tableau de table de hachage (table Entry[]) en interne. L'élément utilisera la fonction de conversion de hachage pour convertir l'adresse de hachage de l'élément en index stocké dans. le tableau. S'il y a un conflit, utilisez la forme d'une liste chaînée pour regrouper tous les éléments avec la même adresse de hachage. Vous pouvez afficher le code source de HashMap.Entry, qui est une structure de liste chaînée unique.
4.2, TreeMap
Les clés sont triées selon une certaine règle de tri, et l'ordre interne est la mise en œuvre d'une structure de données arborescente rouge-noir (rouge-noir), implémente l'interface SortedMap
HashTable
est également implémenté avec une structure de données de table de hachage. Lors de la résolution des conflits, il utilise également une liste chaînée de hachage comme HashMap, mais les performances sont inférieures à celles de HashMap
. 5. File d'attente
File d'attente, elle est principalement divisée en deux catégories, l'une bloque la file d'attente, les éléments seront insérés une fois la file d'attente pleine Une exception seront lancés, comprenant principalement ArrayBlockQueue, PriorityBlockingQueue et LinkedBlockingQueue. Un autre type de file d'attente est une file d'attente à double extrémité, qui prend en charge l'insertion et la suppression d'éléments aux extrémités de tête et de queue, notamment : ArrayDeque, LinkedBlockingDeque et LinkedList.
6. Similitudes et différences
Source : http://www.php .cn/
6.1, Vector et ArrayList
1, le vecteur est synchronisé avec les threads. , il est donc également thread-safe, tandis que arraylist est asynchrone et dangereux pour les threads. Si les facteurs de sécurité des threads ne sont pas pris en compte, il est généralement plus efficace d'utiliser arraylist.
2. Si le nombre d'éléments dans la collection est supérieur à la longueur du tableau de collection actuel, le taux de croissance du vecteur est de 100 % de la longueur actuelle du tableau et le taux de croissance de la liste de tableaux est de 50. % de la longueur actuelle du tableau. Par exemple, lors de l'utilisation d'une quantité relativement importante de données dans une collection, l'utilisation de vecteurs présente certains avantages.
3. Si vous recherchez des données à un emplacement spécifié, l'heure utilisée par vector et arraylist est la même, toutes deux 0(1). Dans ce cas, vous pouvez utiliser soit vector, soit arraylist. . Et si le temps nécessaire pour déplacer les données à un emplacement spécifié est 0(n-i) n est la longueur totale, vous devriez envisager d'utiliser linklist à ce moment-là, car il faut 0(1) pour déplacer les données à un emplacement spécifié, et le requête Le temps nécessaire pour récupérer les données à un emplacement spécifié est 0(i).
ArrayList et Vector utilisent des tableaux pour stocker des données. Le nombre d'éléments du tableau est supérieur aux données réellement stockées, de sorte que les éléments peuvent être ajoutés et insérés. indexation directe des numéros de série des éléments.Cependant, l'insertion de données nécessite des opérations de mémoire telles que le déplacement d'éléments du tableau, donc l'indexation des données est rapide et l'insertion de données est lente, Vector utilise une méthode synchronisée (sécurité des threads), ses performances sont donc pires que celles de ArrayList. utilise une liste doublement chaînée pour le stockage et indexe les données par numéro de série. Elle doit être parcourue en avant ou en arrière, mais lors de l'insertion de données, il vous suffit d'enregistrer les éléments avant et après cet élément, donc l'insertion est plus rapide !
6.2, Aarraylist et Linkedlist
1.ArrayList est basé sur la dynamique Structure de données du tableau, LinkedList est basée sur la structure de données de la liste chaînée.
2. Pour obtenir et définir un accès aléatoire, ArrayList est meilleur que LinkedList car LinkedList nécessite de déplacer le pointeur.
3. Pour les opérations de création et de suppression d'ajout et de suppression, LinedList a l'avantage car ArrayList doit déplacer les données.
Cela dépend de la situation réelle. Si une seule donnée est insérée ou supprimée, ArrayList est plus rapide que LinkedList. Mais si les données sont insérées et supprimées de manière aléatoire par lots, la vitesse de LinkedList est bien meilleure que celle d'ArrayList, car chaque fois qu'une donnée est insérée dans ArrayList, le point d'insertion et toutes les données qui le suivent doivent être déplacés.
6.3, HashMap et TreeMap
1. Recherche rapide et tous les éléments de TreeMap conservent un certain ordre fixe. Si vous avez besoin d'obtenir un résultat ordonné, vous devez utiliser TreeMap (l'ordre des éléments dans HashMap n'est pas fixe). L'ordre des éléments dans HashMap n'est pas fixe).
2. HashMap utilise un hashcode pour rechercher rapidement son contenu, tandis que tous les éléments de TreeMap maintiennent un certain ordre fixe. Si vous avez besoin d'obtenir des résultats ordonnés, vous devez utiliser TreeMap (l'ordre des éléments dans HashMap n'est pas fixe). "Collection Framework" fournit deux implémentations de Map conventionnelles : HashMap et TreeMap (TreeMap implémente l'interface SortedMap
3. , HashMap est le meilleur choix. Mais si vous souhaitez parcourir les clés dans un ordre naturel ou personnalisé, alors l'utilisation de HashMap nécessite que la classe de clé ajoutée ait une implémentation de hashCode() et equals() explicitement définie. . Il n'y a pas d'options de réglage car l'arbre est toujours dans un état équilibré
> 1 Raisons historiques : Hashtable est basé sur l'ancienne classe Dictionary et HashMap est une implémentation de la. Interface cartographique introduite dans Java 1.2 Synchronicité : Hashtable est thread-safe, ce qui signifie qu'elle est synchrone, tandis que HashMap est thread-safe et non synchrone
: Seul HashMap le permet. vous devez utiliser des valeurs nulles comme clé ou valeur d'une entrée de table 7. Sélection d'ensembles
Sélection de liste
1. Pour les requêtes aléatoires et les opérations de parcours itératives, les tableaux sont meilleurs que tous les conteneurs. Les deux sont donc plus rapides. ArrayList est généralement utilisé en accès aléatoire. ArrayList doit effectuer un déplacement d'élément lors de l'ajout et de la suppression d'éléments. >
4. Après tout, nous ne parcourons que les éléments de la collection. . Uniquement lorsque les performances du programme sont réduites en raison de l'insertion et de la suppression fréquentes de List, pensez à LinkedList >. 7.2. Choix de l'ensemble
1. HashSet est implémenté en utilisant HashCode, donc dans une certaine mesure, on le dit. que ses performances sont toujours meilleures que TreeSet, notamment pour les opérations d'addition et de recherche.
3. Bien que TreeSet n'ait pas d'aussi bonnes performances que HashSet, il a toujours son utilité car il peut maintenir l'ordre des éléments.
7.3 Choix de la carte
1. prend en charge la requête rapide. Bien que HashTable ne soit pas lent, il est encore légèrement plus lent que HashMap, donc HashMap peut remplacer HashTable dans la requête.
2. Parce que TreeMap doit maintenir l'ordre des éléments internes, il est généralement plus lent que HashMap et HashTable.
Ce qui précède est le contenu. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
