

Chapitre d'amélioration de Java (23) -----HashMap

/www.php.cn/
1. Définition
HashMap implémente l'interface Map et hérite de AbstractMap. L'interface Map définit les règles de mappage des clés aux valeurs, tandis que la classe AbstractMap fournit l'implémentation principale de l'interface Map pour minimiser le travail requis pour implémenter cette interface. En fait, la classe AbstractMap a déjà implémenté Map, et cela est marqué ici. comme Map. LZ pense que cela devrait être plus clair !
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
2. Constructeur
HashMap fournit trois constructeurs :
HashMap() : construit un HashMap vide avec une capacité initiale par défaut (16) et un facteur de chargement par défaut (0,75) HashMap.
HashMap(int initialCapacity) : construit un HashMap vide avec la capacité initiale spécifiée et le facteur de charge par défaut (0,75).
HashMap(int initialCapacity, float loadFactor) : construit un HashMap vide avec une capacité initiale et un facteur de charge spécifiés. <<>
J'ai évoqué ici deux paramètres : la capacité initiale, le facteur de chargement. Ces deux paramètres sont des paramètres importants qui affectent les performances de HashMap. La capacité représente le nombre de compartiments dans la table de hachage, la capacité initiale est la capacité lorsque la table de hachage est créée et le facteur de charge est le degré de remplissage de la table de hachage. avant que sa capacité ne soit automatiquement augmentée. Une échelle qui mesure l'utilisation de l'espace d'une table de hachage. Plus le facteur de charge est grand, plus le niveau de remplissage de la table de hachage est élevé, et vice versa. Pour une table de hachage utilisant la méthode de liste chaînée, le temps moyen de recherche d'un élément est O(1 a). Par conséquent, si le facteur de charge est plus grand, l'espace est plus pleinement utilisé. Cependant, la conséquence est une réduction de la recherche. efficacité ; si le facteur de charge est trop petit, alors les données dans la table de hachage seront trop clairsemées, entraînant un sérieux gaspillage d'espace. Le facteur de charge par défaut du système est de 0,75 et nous n'avons généralement pas besoin de le modifier.
HashMap est une structure de données qui prend en charge un accès rapide Pour comprendre ses performances, vous devez comprendre sa structure de données.
3. Structure des données
Nous savons que les deux structures les plus couramment utilisées en Java sont les tableaux et les pointeurs simulés (références). Presque toutes les structures de données peuvent être implémentées en combinaison avec ces deux, et il en va de même pour HashMap. En fait, HashMap est un "hachage de liste chaînée". Voici sa structure de données :
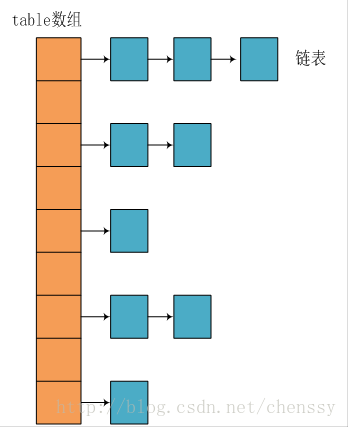
De dans l'image ci-dessus, nous pouvons voir que l'implémentation sous-jacente de HashMap est toujours un tableau, mais chaque élément du tableau est une chaîne. Le paramètre initialCapacity représente la longueur du tableau. Voici le code source du constructeur HashMap :
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能<0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ initialCapacity);
//初始容量不能 > 最大容量值,HashMap的最大容量值为2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "
+ loadFactor);
// 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//设置HashMap的容量极限,当HashMap的容量达到该极限时就会进行扩容操作
threshold = (int) (capacity * loadFactor);
//初始化table数组
table = new Entry[capacity];
init();
}
Comme le montre le code source, chaque fois qu'un HashMap est créé, un tableau de tables sera initialisé. Les éléments du tableau tableau sont des nœuds d'entrée.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
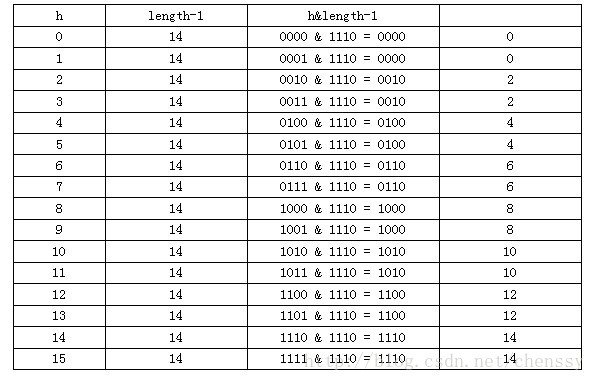
}Où Entry est la classe interne de HashMap , Il contient la clé, la valeur, le nœud suivant et la valeur de hachage. C'est précisément à cause de Entry que les éléments du tableau sont des listes chaînées. 上面简单分析了HashMap的数据结构,下面将探讨HashMap是如何实现快速存取的。 首先我们先看源码 通过源码我们可以清晰看到HashMap保存数据的过程为:首先判断key是否为null,若为null,则直接调用putForNullKey方法。若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。这个过程看似比较简单,其实深有内幕。有如下几点: 1、 先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。 2、 在看(1)、(2)处。这里是HashMap的精华所在。首先是hash方法,该方法为一个纯粹的数学计算,就是计算h的hash值。 我们知道对于HashMap的table而言,数据分布需要均匀(最好每项都只有一个元素,这样就可以直接找到),不能太紧也不能太松,太紧会导致查询速度慢,太松则浪费空间。计算hash值后,怎么才能保证table元素分布均与呢?我们会想到取模,但是由于取模的消耗较大,HashMap是这样处理的:调用indexFor方法。 HashMap的底层数组长度总是2的n次方,在构造函数中存在:capacity <<= 1;这样做总是能够保证HashMap的底层数组长度为2的n次方。当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化。至于为什么是2的n次方下面解释。 我们回到indexFor方法,该方法仅有一条语句:h&(length - 1),这句话除了上面的取模运算外还有一个非常重要的责任:均匀分布table数据和充分利用空间。 这里我们假设length为16(2^n)和15,h为5、6、7。 当n=15时,6和7的结果一样,这样表示他们在table存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,这样就会导致查询速度降低。诚然这里只分析三个数字不是很多,那么我们就看0-15。 从上面的图表中我们看到总共发生了8此碰撞,同时发现浪费的空间非常大,有1、3、5、7、9、11、13、15处没有记录,也就是没有存放数据。这是因为他们在与14进行&运算时,得到的结果最后一位永远都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的,空间减少,进一步增加碰撞几率,这样就会导致查询速度慢。而当length = 16时,length – 1 = 15 即1111,那么进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以说当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。 这里我们再来复习put的流程:当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。具体的实现过程见addEntry方法,如下: 这个方法中有两点需要注意: 一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。 二、扩容问题。 随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。 相对于HashMap的存而言,取就显得比较简单了。通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。 在这里能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
以上就是java提高篇(二三)-----HashMap的内容,更多相关内容请关注PHP中文网(www.php.cn)! 四、存储实现:put(key,vlaue)
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode()); ------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2)
//从i出开始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}static int indexFor(int h, int length) {
return h & (length-1);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//获取bucketIndex处的Entry
Entry<K, V> e = table[bucketIndex];
//将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
//若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold)
resize(2 * table.length);
} 五、读取实现:get(key)
public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
