

21 meilleurs conseils d'optimisation des performances MySQL
Feb 21, 2017 am 10:47 AM1. Optimisez vos requêtes pour la mise en cache des requêtes
La plupart des serveurs MySQL ont la mise en cache des requêtes activée. C'est l'un des moyens les plus efficaces d'améliorer les performances, et il est géré par le moteur de base de données MySQL. Lorsque plusieurs requêtes identiques sont exécutées plusieurs fois, les résultats de la requête seront placés dans un cache, de sorte que les requêtes identiques suivantes n'auront pas besoin d'exploiter la table mais d'accéder directement aux résultats mis en cache.
Le principal problème ici est que pour les programmeurs, cette question est facilement négligée. Parce que certaines de nos instructions de requête empêcheront MySQL d'utiliser le cache. Veuillez consulter l'exemple suivant :
1 2 3 4 5 6 |
|
La différence entre les deux instructions SQL ci-dessus est que CURDATE() le cache de requêtes MySQL ne fonctionne pas sur cette fonction. Par conséquent, les fonctions SQL comme NOW() et RAND() ou d'autres fonctions similaires ne permettront pas la mise en cache des requêtes car les retours de ces fonctions sont volatiles. Il vous suffit donc de remplacer la fonction MySQL par une variable pour activer la mise en cache.
2. EXPLAIN votre requête SELECT
L'utilisation du mot-clé EXPLAIN peut vous permettre de savoir comment MySQL gère votre instruction SQL. Cela peut vous aider à analyser les goulots d'étranglement des performances de vos instructions de requête ou de vos structures de table.
Les résultats de la requête EXPLAIN vous indiqueront également comment votre clé primaire d'index est utilisée, comment votre table de données est recherchée et triée... etc., etc.
Choisissez l'une de vos instructions SELECT (il est recommandé de choisir la plus complexe avec plusieurs connexions de table) et ajoutez le mot-clé EXPLAIN au début. Vous pouvez utiliser phpmyadmin pour ce faire. Ensuite, vous verrez un formulaire. Dans l'exemple ci-dessous, nous avons oublié d'ajouter l'index group_id et il y a une jointure de table :
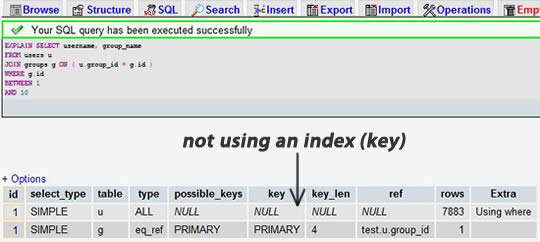
Après avoir ajouté l'index au champ group_id :

Nous pouvons voir que le premier résultat montre que 7883 lignes ont été recherchées, tandis que le second n'a recherché que 9 et 16 lignes des deux tables. L'examen de la colonne des lignes nous permet de détecter des problèmes de performances potentiels.
3. Utilisez LIMIT 1 lorsqu'il n'y a qu'une seule ligne de données
Parfois, lorsque vous interrogez la table, vous savez déjà que le résultat ne sera qu'un seul résultat, mais parce que vous devrez peut-être le faire. récupérez le curseur, ou Oui, vous pouvez vérifier le nombre d'enregistrements renvoyés.
Dans ce cas, l'ajout de LIMIT 1 peut augmenter les performances. De cette façon, le moteur de base de données MySQL arrêtera la recherche après avoir trouvé une donnée, au lieu de continuer à rechercher la donnée suivante correspondant à l'enregistrement.
L'exemple suivant sert simplement à savoir s'il existe des utilisateurs "Chine". Évidemment, ce dernier sera plus efficace que le premier. (Veuillez noter que le premier élément est Select * et le deuxième élément est Select 1)
1 2 3 4 5 6 7 8 9 10 11 |
|
4. Créez un index pour le champ de recherche
L'index ne signifie pas nécessairement le principal. ou le champ Unique. S'il y a un champ dans votre table que vous utiliserez toujours pour les recherches, veuillez créer un index pour celui-ci.
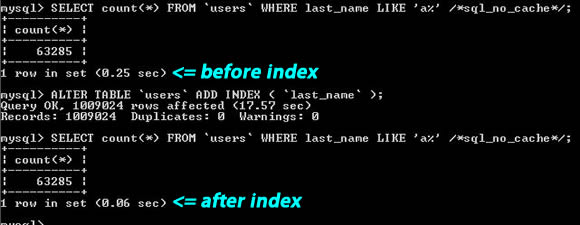
Dans l'image ci-dessus, vous pouvez voir la chaîne de recherche "last_name LIKE 'a%'", l'une est indexée, l'autre n'est pas indexée, les performances sont médiocres de 4 À propos des temps.
De plus, vous devriez également avoir besoin de savoir quels types de recherches ne peuvent pas utiliser l'indexation normale. Par exemple, lorsque vous devez rechercher un mot dans un article volumineux, tel que : "WHERE post_content LIKE '%apple%'", l'index peut ne pas avoir de sens. Vous devrez peut-être utiliser l'index de texte intégral MySQL ou créer un index vous-même (par exemple : rechercher des mots-clés ou des balises)
5 Utilisez un type d'exemple correspondant lorsque vous rejoignez la table et indexez-la
Si votre application comporte de nombreuses requêtes JOIN, vous devez vous assurer que les champs Join des deux tables sont indexés. De cette façon, MySQL lancera un mécanisme pour optimiser l'instruction Join SQL pour vous.
De plus, les champs utilisés pour Join doivent être du même type. Par exemple : si vous joignez un champ DECIMAL à un champ INT, MySQL ne peut pas utiliser leurs index. Pour ces types STRING, ils doivent également avoir le même jeu de caractères. (Les jeux de caractères des deux tables peuvent être différents)
1 2 3 4 5 6 |
|
6. Ne jamais ORDER BY RAND()
Vous souhaitez perturber les lignes de données renvoyées ? Choisir une donnée au hasard ? Je ne sais vraiment pas qui a inventé cet usage, mais de nombreux novices aiment l’utiliser de cette façon. Mais vous ne comprenez vraiment pas à quel point cela pose un terrible problème de performances.
Si vous souhaitez vraiment brouiller les lignes de données renvoyées, vous disposez de N façons d'y parvenir. Son utilisation ne fera qu'entraîner une baisse exponentielle des performances de votre base de données. Le problème ici est que MySQL devra exécuter la fonction RAND() (qui est très gourmande en CPU), et cela consiste à enregistrer les lignes pour chaque ligne, puis à les trier. Même si vous utilisez la limite 1, cela n'aidera pas (car il faut le trier)
L'exemple ci-dessous consiste à sélectionner au hasard un enregistrement
1 2 3 4 5 6 7 8 9 |
|
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
1 2 3 4 5 6 7 8 9 |
|
8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在phpmyadmin里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议

一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
12. Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。
Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题,而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
在性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而MySQL只会解析一次。
虽然最新版本的MySQL在传输Prepared Statements是使用二进制形势,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本5.1后支持了。
在PHP中要使用prepared statements,你可以查看其使用手册:mysqli 扩展 或是使用数据库抽象层,如: PDO.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
关于这个事情,在PHP的文档中有一个非常不错的说明: mysql_unbuffered_query() 函数:
“mysql_unbuffered_query() sends the SQL query query to MySQL without automatically fetching and buffering the result rows as mysql_query() does. This saves a considerable amount of memory with SQL queries that produce large result sets, and you can start working on the result set immediately after the first row has been retrieved as you don’t have to wait until the complete SQL query has been performed.”
上面那句话翻译过来是说,mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用 mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
14. 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。
1 |
|
15. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
17. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
1 2 3 4 5 6 7 8 9 10 |
|
18. 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
19. 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
target=”_blank”MyISAM Storage Engine
InnoDB Storage Engine
20. 使用一个对象关系映射器(Object Relational Mapper)
使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的PHP的ORM是:Doctrine。
21. 小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
PHP手册:mysql_pconnect()
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
De plus, Apache fonctionne dans un environnement extrêmement parallèle et créera de très nombreux processus. C'est pourquoi ce mécanisme de « lien permanent » ne fonctionne pas bien. Avant de décider d'utiliser des « liens permanents », vous devez examiner attentivement l'architecture de l'ensemble de votre système.
Ce qui précède sont les 21 meilleurs contenus d'optimisation des performances MySQL. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !

Article chaud
Outils chauds Tags
Article chaud
Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
 Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
 Technologie d'optimisation des performances et d'expansion horizontale du framework Go ?
Jun 03, 2024 pm 07:27 PM
Technologie d'optimisation des performances et d'expansion horizontale du framework Go ?
Jun 03, 2024 pm 07:27 PM
Technologie d'optimisation des performances et d'expansion horizontale du framework Go ?
 Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
 Optimiser les performances du moteur de fusée en utilisant C++
Jun 01, 2024 pm 04:14 PM
Optimiser les performances du moteur de fusée en utilisant C++
Jun 01, 2024 pm 04:14 PM
Optimiser les performances du moteur de fusée en utilisant C++
 Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
 Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
 Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
