

XML : DOM pour l'analyse XML

1. Programmation XML
La programmation XML consiste à effectuer des opérations grossières sur des fichiers XML.
Alors pourquoi avez-vous besoin d'utiliser Java ou C/C pour effectuer des opérations grossières sur XML ?
1.XML doit être analysé en tant que transfert de données
2.XML doit être lu en tant que fichier de configuration
3.XML doit être une opération grossière en tant que petite base de données
organisation w3C permet à tout le monde d'analyser XML , définit un ensemble de spécifications (API)
1.1 Introduction à la technologie d'analyse XML
1. analyse dom et analyse sax
dom : (Document Object Model) est un moyen de traitement XML recommandé par l'organisation W3C
sax : (API simple pour XML), n'est pas un standard officiel, mais c'est le standard de facto dans la communauté XML, et presque tous les analyseurs XML le prennent en charge
SAX l'analyse utilise le bord du modèle basé sur les événements Analyse pendant la lecture : analyse ligne par ligne de haut en bas, analyse jusqu'à un certain élément et appelle la méthode d'analyse correspondante.
DOM alloue une structure arborescente en mémoire selon la structure hiérarchique XML et encapsule les balises XML, les attributs, le texte et d'autres éléments dans des objets de nœud d'arborescence.
Différentes entreprises et organisations fournissent des analyseurs pour DOM et SAX :
JAXP de Sun
Dom4j organisé par Dom4j (la plupart couramment utilisé, comme hibernate)
jdom organisé par JDom
Le JASP fait partie de J2SE, qui sont des analyseurs DOM et SAX fournis pour DOM et SAX.
Ici, nous introduisons également principalement trois types d'analyse : dom, sax et dom4j
1.2.Introduction à JAXP
Sun fournit une API Java pour l'analyse XML (JAXP) pour utiliser SAX et DOM Grâce à JAXP, nous pouvons utiliser n'importe quel analyseur XML compatible JAXP.
Le package de développement JAXP fait partie de J2SE, qui comprend les packages javax.xml, org.w3c.dom, org.xml.sax et leurs sous-packages
Dans le fichier javax.xml .parsers , plusieurs classes d'usine sont définies lorsque les programmeurs appellent ces classes d'usine, ils peuvent obtenir des objets d'analyseur DOM ou SAX qui analysent les documents XML.
2.Analyse DOM JAXP
2.1.Arborescence des nœuds DOM DOM
Expliquez d'abord l'objet DOM de l'analyse XML JAXP Le principe du XML DOM est que le document XML est considéré comme un arbre de nœuds et que tous les nœuds de l'arborescence sont liés les uns aux autres. Tous les nœuds sont accessibles via cette arborescence. Leur contenu peut être modifié ou supprimé, et de nouveaux éléments peuvent être créés.
Par exemple, le document XML actuel est le suivant (cet exemple provient du tutoriel en ligne w3cschool) :
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>Cet arbre part du nœud racine et pousse des branches vers le nœud texte au niveau le plus bas de l'arborescence. :
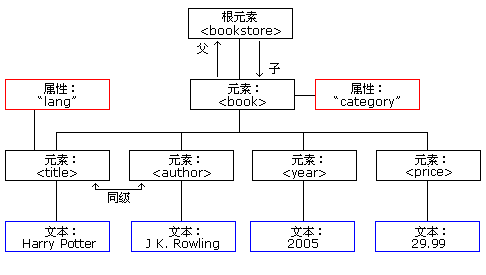
[Quelques points de connaissances à connaître] :
1.dom considérera le fichier xml comme une arborescence et le chargera dans la mémoire
2 .dom est particulièrement adaptée aux opérations grossières
3.dom ne convient pas à l'exploitation de fichiers XML plus volumineux (occupe de la mémoire)
4.dom mappera chaque élément, attribut et texte du XML fichier à l’objet Node correspondant.
2.2. Étapes pour obtenir l'analyseur DOM dans JAXP
1 Appelez la méthode DocumentBuilderFactory.newInstance() pour obtenir la fabrique qui crée l'analyseur DOM
. 2. Appelez La méthode newDocumentBuilder de l'objet factory obtient l'objet analyseur DOM
3. Appelez la méthode parse() de l'objet analyseur DOM pour analyser le document XML et obtenir l'objet Document représentant l'intégralité du document XML. peut être exploité à l’aide des fonctionnalités DOM.
2.3. Exemple d'analyse JAXP DOM :
Le document XML est le suivant :
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1 Lire XML. document
Utilisez d'abord les trois étapes introduites dans 2.2 pour obtenir l'objet document représentant l'intégralité du document, et appelez la méthode read(Document document) que nous avons écrite, comme suit :
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);où La méthode read est écrite comme ceci :
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }Le résultat final de l'exécution est le suivant :

2.3.2 Mettre à jour XML. document
L'utilisation de DOM pour mettre à jour des documents XML doit utiliser la classe Transformer pour écrire les modifications dans le fichier, sinon cela modifiera simplement l'objet du document XML en mémoire.
La classe Transformer du package javax.xml.transform est utilisée pour convertir l'objet Document représentant le fichier XML dans un certain format de sortie. Par exemple, appliquer une feuille de style au. xml et convertissez-le en un document HTML. En utilisant cet objet, bien sûr, vous pouvez également réécrire l'objet Document dans un fichier XML
La classe Transformer termine l'opération de conversion via la méthode transform, qui reçoit une source et une destination . On peut associer l'objet document à convertir via :
classe javax.xml.transform.dom.DOMSource
Utilisez l'objet javax.xml.transform.stream.StreamResult pour représenter la destination des données
L'objet Transformer est obtenu via TransformerFactory
【1】Ajouter un élément
Nous pouvons ajouter un nœud enfant étudiant au XML ci-dessus, comme suit :
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
}1.XML编程
XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.1.XML解析技术介绍
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
1.2.JAXP介绍
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
2.JAXP之DOM解析
2.1.XML DOM节点树
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
2.2.获得JAXP中的DOM解析器步骤
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
2.3.JAXP之DOM解析实例:
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1.读取XML文档
首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的XML : DOM pour lanalyse XML如下所示:
2.3.2.更新XML文档
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
} 以上就是XML—XML解析之DOM的内容,更多相关内容请关注PHP中文网(www.php.cn)!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Puis-je ouvrir un fichier XML à l'aide de PowerPoint ?
Feb 19, 2024 pm 09:06 PM
Puis-je ouvrir un fichier XML à l'aide de PowerPoint ?
Feb 19, 2024 pm 09:06 PM
Les fichiers XML peuvent-ils être ouverts avec PPT ? XML, Extensible Markup Language (Extensible Markup Language), est un langage de balisage universel largement utilisé dans l'échange et le stockage de données. Comparé au HTML, XML est plus flexible et peut définir ses propres balises et structures de données, rendant le stockage et l'échange de données plus pratiques et unifiés. PPT, ou PowerPoint, est un logiciel développé par Microsoft pour créer des présentations. Il fournit un moyen complet de
 Filtrage et tri des données XML à l'aide de Python
Aug 07, 2023 pm 04:17 PM
Filtrage et tri des données XML à l'aide de Python
Aug 07, 2023 pm 04:17 PM
Implémentation du filtrage et du tri des données XML à l'aide de Python Introduction : XML est un format d'échange de données couramment utilisé qui stocke les données sous forme de balises et d'attributs. Lors du traitement de données XML, nous devons souvent filtrer et trier les données. Python fournit de nombreux outils et bibliothèques utiles pour traiter les données XML. Cet article explique comment utiliser Python pour filtrer et trier les données XML. Lecture du fichier XML Avant de commencer, nous devons lire le fichier XML. Python possède de nombreuses bibliothèques de traitement XML,
 Utiliser Python pour fusionner et dédupliquer des données XML
Aug 07, 2023 am 11:33 AM
Utiliser Python pour fusionner et dédupliquer des données XML
Aug 07, 2023 am 11:33 AM
Utilisation de Python pour fusionner et dédupliquer des données XML XML (eXtensibleMarkupLanguage) est un langage de balisage utilisé pour stocker et transmettre des données. Lors du traitement de données XML, nous devons parfois fusionner plusieurs fichiers XML en un seul ou supprimer les données en double. Cet article explique comment utiliser Python pour implémenter la fusion et la déduplication de données XML, et donne des exemples de code correspondants. 1. Fusion de données XML Lorsque nous avons plusieurs fichiers XML, nous devons les fusionner
 Convertir des données XML au format CSV en Python
Aug 11, 2023 pm 07:41 PM
Convertir des données XML au format CSV en Python
Aug 11, 2023 pm 07:41 PM
Convertir des données XML en Python au format CSV XML (ExtensibleMarkupLanguage) est un langage de balisage extensible couramment utilisé pour le stockage et la transmission de données. CSV (CommaSeparatedValues) est un format de fichier texte délimité par des virgules couramment utilisé pour l'importation et l'exportation de données. Lors du traitement des données, il est parfois nécessaire de convertir les données XML au format CSV pour faciliter l'analyse et le traitement. Python est un puissant
 Python implémente la conversion entre XML et JSON
Aug 07, 2023 pm 07:10 PM
Python implémente la conversion entre XML et JSON
Aug 07, 2023 pm 07:10 PM
Python implémente la conversion entre XML et JSON Introduction : Dans le processus de développement quotidien, nous devons souvent convertir des données entre différents formats. XML et JSON sont des formats d'échange de données courants. En Python, nous pouvons utiliser diverses bibliothèques pour réaliser une conversion mutuelle entre XML et JSON. Cet article présentera plusieurs méthodes couramment utilisées, avec des exemples de code. 1. Pour convertir XML en JSON en Python, nous pouvons utiliser le module xml.etree.ElementTree
 Gestion des erreurs et des exceptions en XML à l'aide de Python
Aug 08, 2023 pm 12:25 PM
Gestion des erreurs et des exceptions en XML à l'aide de Python
Aug 08, 2023 pm 12:25 PM
Gestion des erreurs et des exceptions dans XML à l'aide de Python XML est un format de données couramment utilisé pour stocker et représenter des données structurées. Lorsque nous utilisons Python pour traiter XML, nous pouvons parfois rencontrer des erreurs et des exceptions. Dans cet article, je vais vous présenter comment utiliser Python pour gérer les erreurs et les exceptions dans XML, et fournir un exemple de code pour référence. Utilisez l'instruction try-sauf pour détecter les erreurs d'analyse XML Lorsque nous utilisons Python pour analyser XML, nous pouvons parfois rencontrer des
 Python analyse les caractères spéciaux et les séquences d'échappement en XML
Aug 08, 2023 pm 12:46 PM
Python analyse les caractères spéciaux et les séquences d'échappement en XML
Aug 08, 2023 pm 12:46 PM
Python analyse les caractères spéciaux et les séquences d'échappement en XML XML (eXtensibleMarkupLanguage) est un format d'échange de données couramment utilisé pour transférer et stocker des données entre différents systèmes. Lors du traitement de fichiers XML, vous rencontrez souvent des situations contenant des caractères spéciaux et des séquences d'échappement, qui peuvent provoquer des erreurs d'analyse ou une mauvaise interprétation des données. Par conséquent, lors de l’analyse de fichiers XML à l’aide de Python, nous devons comprendre comment gérer ces caractères spéciaux et ces séquences d’échappement. 1. Caractères spéciaux et
 Comment gérer les formats de données XML et JSON dans le développement C#
Oct 09, 2023 pm 06:15 PM
Comment gérer les formats de données XML et JSON dans le développement C#
Oct 09, 2023 pm 06:15 PM
La gestion des formats de données XML et JSON dans le développement C# nécessite des exemples de code spécifiques. Dans le développement de logiciels modernes, XML et JSON sont deux formats de données largement utilisés. XML (Extensible Markup Language) est un langage de balisage permettant de stocker et de transmettre des données, tandis que JSON (JavaScript Object Notation) est un format d'échange de données léger. Dans le développement C#, nous devons souvent traiter et exploiter des données XML et JSON. Cet article se concentrera sur la façon d'utiliser C# pour traiter ces deux formats de données et les attacher.
