

Explication approfondie des index et des structures MySQL

B-tree
B-Tree est également appelé arbre de recherche multi-chemins équilibré (non binaire). L'utilisation de la structure B-tree peut être significative. réduire Localisez le processus intermédiaire rencontré lors de l'enregistrement, accélérant ainsi l'accès.
Valeur clé du nœud enfant gauche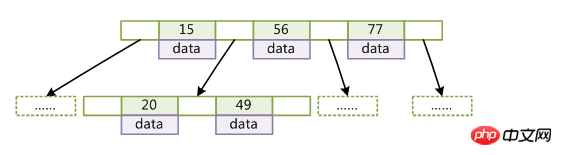
(la clé est la valeur clé de l'enregistrement. Pour différents enregistrements de données, la clé est différente les unes des autres ; les données sont les données de l'enregistrement de données à l'exception de la clé)
B tree
B Tree est un B-tree amélioré. 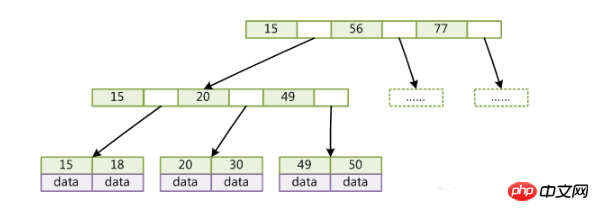
(la clé est la valeur clé de l'enregistrement. Pour différents enregistrements de données, la clé est différente les unes des autres ; les données sont les données de l'enregistrement de données à l'exception de la clé)
Semblable à B-Tree Comparé à, B Tree présente les différences suivantes :
La limite supérieure du pointeur de chaque nœud est 2d au lieu de 2d 1.
Les nœuds internes ne stockent pas de données, seuls les nœuds feuilles ne stockent pas de pointeurs.
Alors pourquoi la base de données utilise-t-elle B-tree
Le disque mécanique de l'ordinateur Afin d'amortir le temps d'attente des mouvements mécaniques, le disque va accéder à plusieurs ? éléments de données à la fois. Pas un, une telle unité d'information lue à la fois est une page. Nous pouvons utiliser le nombre de pages lues ou écrites comme approximation principale de l'accès au disque temps total. . A tout moment, les algorithmes de B Tree n'ont tous besoin de conserver qu'un certain nombre de pages en mémoire. La conception de B-tree prend en compte la pré-lecture du disque Un nœud B-tree est généralement aussi grand qu'une page (page) de disque complète, et la taille de la page de disque limite les enfants d'un B-. Le nœud d'arbre peut contenir. Le nombre (facteur de branchement), bien sûr, cela dépend aussi de la taille d'un mot-clé par rapport à une page.
Afin de minimiser les opérations d'E/S, les lectures sur disque sont lues à l'avance à chaque fois, et la taille est généralement un multiple entier de la page. Même si un seul octet doit être lu, le disque lira une page de données (généralement 4 Ko) et la placera dans la mémoire. La mémoire et le disque échangent des données en unités de pages. Parce que le principe de localité veut que lorsqu’une donnée est habituellement utilisée, les données proches seront également utilisées immédiatement.
B-Tree : Si une récupération nécessite l'accès à 4 nœuds, le concepteur du système de base de données utilise le principe de lecture anticipée du disque pour concevoir la taille du nœud comme une page, puis la lecture d'un nœud n'en nécessite qu'un seul. Opération /O , pour terminer cette opération de récupération, jusqu'à 3 E/S sont nécessaires (le nœud racine réside en mémoire). Plus l'enregistrement de données est petit, plus de données sont stockées dans chaque nœud, plus la hauteur de l'arborescence est petite, moins il y a d'opérations d'E/S et l'efficacité de la récupération augmente.
Arbre B : les nœuds non-feuilles stockent uniquement les clés, ce qui réduit considérablement la taille des nœuds non-feuilles, de sorte que chaque nœud peut stocker plus d'enregistrements L'arborescence est plus courte et les opérations d'E/S sont moindres<.>. B Tree a donc de meilleures performances.
Qu'est-ce qu'un index ?Un index est simplement une structure de données. Le coût de l'indexationL'indexation a également un coût : le fichier d'index lui-même consomme de l'espace de stockage et l'index augmente la charge d'insertion, de suppression et de modification des enregistrements. De plus, MySQL. des ressources sont également consommées pour maintenir les index, donc plus d'index n'est pas toujours mieux. Généralement, il n'est pas recommandé de construire un index dans deux circonstancesLe premier cas est que les enregistrements de la table sont relativement petits
L'autre cas où il n'est pas recommandé de construire un index est que la sélectivité de l'index est faible. La soi-disant sélectivité d'index (Sélectivité) fait référence au rapport entre les valeurs d'index uniques (également appelées cardinalité) et le nombre d'enregistrements de table (#T)
2. Index unique
3. Index de clé primaire
4. Index combiné
B Tree est couramment utilisé comme index dans MySQL. , Mais L'implémentation diffère selon l'index clusterisé et l'index non clusterisé.
Index clusterisé et index non clusterisé
Le soi-disant index clusterisé signifie que le fichier d'index principal et le fichier de données sont le même fichier. L'index clusterisé est principalement utilisé dans le moteur de stockage Innodb. Dans cette implémentation d'index, les données sur les nœuds feuilles de B Tree sont les données elles-mêmes et la clé est la clé primaire. Comme indiqué ci-dessous : 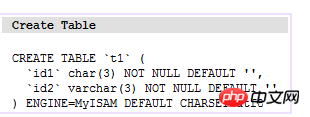
(table t1) 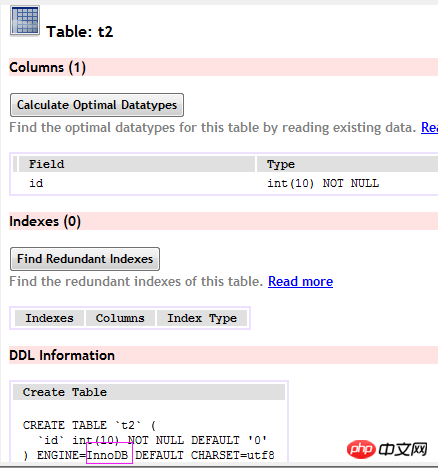
(table t2) 
(fichier correspondant à la base de données)
Car d'InnoDB Les fichiers de données eux-mêmes doivent être agrégés par clé primaire, donc InnoDB exige que la table ait une clé primaire (MyISAM peut ne pas en avoir une si cela n'est pas explicitement spécifié, le système MySQL sélectionnera automatiquement une colonne qui peut identifier de manière unique la). enregistrement de données comme clé primaire. Si aucune colonne de ce type n'existe, alors MySQL génère automatiquement un champ implicite comme clé primaire pour la table InnoDB. La longueur de ce champ est de 6 octets et le type est long.
Les principales différences entre les moteurs de stockage de données MyISAM et InnoDB dans la base de données MySQL
:
MyISAM n'est pas sécurisé sur le plan transactionnel, tandis qu'InnoDB est sécurisé sur le plan transactionnel.
La granularité des verrous MyISAM est au niveau de la table, tandis qu'InnoDB prend en charge le verrouillage au niveau de la ligne.
MyISAM prend en charge l'index de type texte intégral, mais InnoDB ne prend pas en charge l'index de texte intégral.
MyISAM est relativement simple, il est donc meilleur qu'InnoDB en termes d'efficacité. Les petites applications peuvent envisager d'utiliser MyISAM.
Les tables MyISAM sont enregistrées sous forme de fichiers. L'utilisation du stockage MyISAM dans le transfert de données multiplateforme évitera bien des problèmes.
Les tables InnoDB sont plus sécurisées que les tables MyISAM. Vous pouvez passer des tables non transactionnelles aux tables transactionnelles (alter table tablename type=innodb) tout en garantissant que les données ne seront pas perdues.
Scénario d'application :
MyISAM gère les tables non transactionnelles. Il offre un stockage et une récupération à grande vitesse, ainsi que des capacités de recherche en texte intégral. Si votre application doit effectuer un grand nombre de requêtes SELECT, MyISAM est un meilleur choix.
InnoDB est utilisé pour les applications de traitement de transactions et possède de nombreuses fonctionnalités, notamment la prise en charge des transactions ACID. Si votre application doit effectuer un grand nombre d'opérations INSERT ou UPDATE, vous devez utiliser InnoDB, qui peut améliorer les performances des opérations simultanées multi-utilisateurs.
Supplément
Stockage de la mémoire principale
Processus de récupération
Lorsque le système a besoin de lire la mémoire principale, le signal d'adresse est mis sur le bus d'adresse et transmis au mémoire principale. Une fois que la mémoire principale a lu le signal d'adresse, elle analyse le signal et localise l'unité de stockage spécifiée, puis place les données de cette unité de stockage sur le bus de données pour que d'autres composants puissent les lire.
Le processus d'écriture dans la mémoire principale est similaire. Le système place l'adresse de l'unité et les données à écrire respectivement sur le bus d'adresses et le bus de données. La mémoire principale lit le contenu des deux bus et effectue les opérations d'écriture correspondantes.
On voit ici que le temps d'accès à la mémoire principale n'est que linéairement lié au nombre d'accès. Puisqu'il n'y a pas d'opération mécanique, la "distance" des données accédées deux fois n'aura aucun impact sur le temps. Par exemple, récupérer d'abord La consommation de temps pour récupérer A0 puis A1 est la même que pour récupérer A0 puis D3
Principe d'accès au disque
Lorsque les données doivent être lues à partir du disque, le Le système transmettra l'adresse logique des données au disque, le circuit de contrôle du disque traduit l'adresse logique en une adresse physique selon la logique d'adressage, c'est-à-dire détermine sur quelle piste et sur quel secteur se trouvent les données à lire. Afin de lire les données dans ce secteur, la tête magnétique doit être placée sur ce secteur. Pour y parvenir, la tête magnétique doit se déplacer pour s'aligner avec la piste correspondante. Ce processus est appelé recherche, et le temps passé. est appelé temps de recherche. Ensuite, la rotation du disque Le secteur cible tourne sous la tête. Le temps passé dans ce processus est appelé temps de rotation.
Ce qui précède est une explication approfondie et détaillée de l'index et de la structure MySQL. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
