

En raison du développement des affaires, l'utilisation de MySQL pour créer des index et des recherches a provoqué le blocage du flux de données dans la base de données, par exemple, à chaque fois qu'elle est pleine. La table est vidée, cela entraînera une pression trop forte, ce qui prendra beaucoup de temps et le volume de données actuel a essentiellement atteint 100 millions de niveaux. Si vous voulez que MySQL fournisse de meilleurs services, l'étape suivante doit être d'envisager des sous. -bases de données et tables basées sur ceci Dans ce cas, envisagez d'utiliser hbase pour le stockage de données, car la quantité de données que hbase peut supporter est beaucoup plus grande que mysql, et l'expansion des colonnes est également très pratique
Dans les bases de données relationnelles telles que mysql, sqlserver, oracle, les données sont stockées en fonction des lignes, comme indiqué ci-dessous. figure :
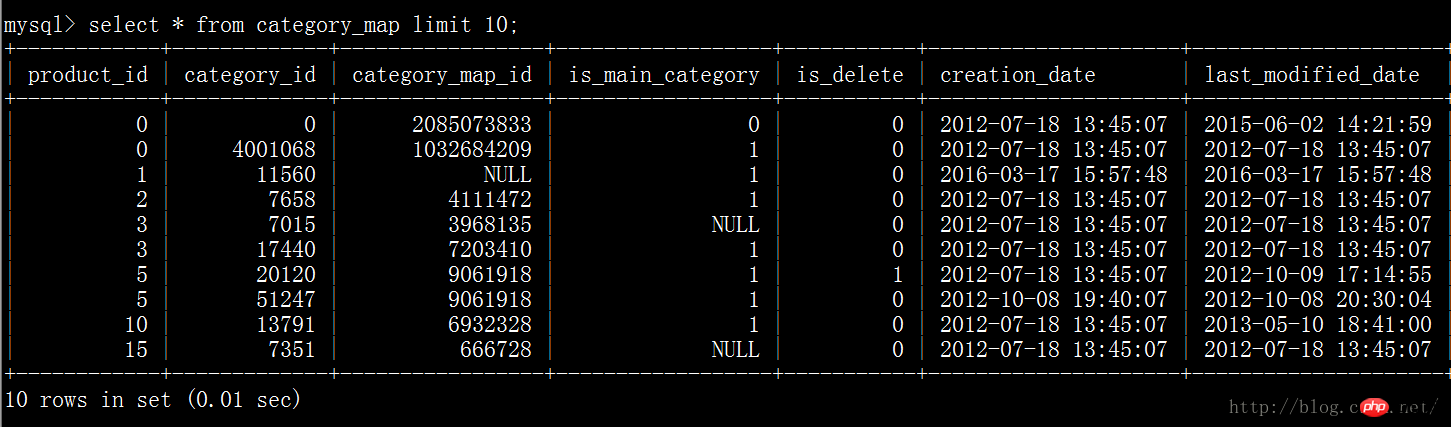
Mais dans hbase, toutes les données sont stockées en fonction de colonnes, comme indiqué ci-dessous :

Le modèle logique de hbase est le suivant :
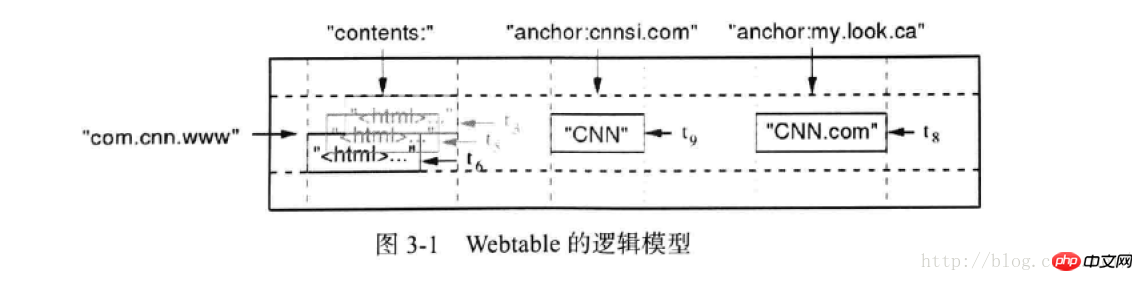
Parmi eux : com.cnn.ww correspond à rowkey, qui est équivalent au concept de clé primaire de mysql
contenu, ancre : Ces deux correspondent à la notion de famille de colonnes En terme de stockage physique, les données d'une même famille de colonnes sont stockées dans le même fichier
cnnsi.com. , mylook.ca : correspond à Les colonnes sous la famille de colonnes peuvent être ajoutées dynamiquement dans hbase
Les données de grille correspondantes représentent les données unitaires, c'est-à-dire correspondant à rowkey, cf : la valeur spécifique sous colonne
Parmi eux, tn : représente l'horodatage. Différentes versions des données unitaires
ont une structure de stockage comme suit :
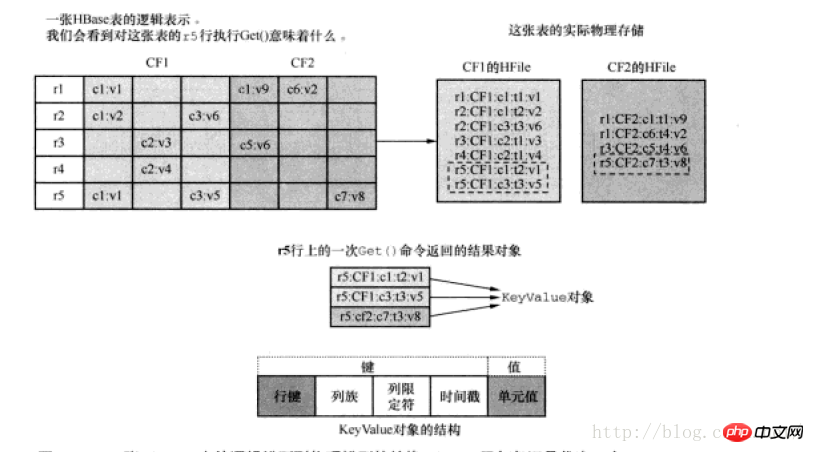
CRUD est l'opération la plus basique et la plus couramment utilisée de la base de données. Il existe également des commandes correspondantes dans hbase. Par exemple, l'instruction de création de table pour. mysql ne sera pas détaillé ici. Pour le shell hbase est le suivant
créer 'table', 'columnfamily'
pour créer une table nommée table, la famille de colonnes est columnfamily, et quelques autres. Les données de taille de bloc et de version sont par défaut
Lors de la lecture des données, utilisez des instructions hbase telles que : get 'table', 'row', 'cf:column' pour obtenir les données correspondantes
Lors de la mise à jour. data, utilisez hbase Il n'y a pas de concept de mises à jour correspondantes, mais il y aura une nouvelle version, qui peut être reflétée à partir de l'horodatage. Les instructions utilisées sont
put 'table', 'row', 'cf : name', 'value '
peut attribuer la valeur de value à la famille de colonnes cf correspondante. Le nom de la colonne name est
La différence entre la suppression de données est que la suppression de données dans MySQL peut être effectuée. supprimez uniquement directement une ligne ou modifiez une certaine colonne sur vide, et vous pouvez supprimer directement une certaine colonne dans hbase
Dans MySQL, vous pouvez créer index ou filtrer les requêtes, mais dans hbase, seule la clé de ligne est prise en charge La vitesse de requête la plus rapide
Les bases de données relationnelles ont une longue histoire, mais lorsque la quantité de données augmente, par exemple, pour la base de données mysql, lorsque la quantité de données atteint des centaines de millions ou plus Parfois, si vous interrogez sur la base de l'index, l'effet peut ne pas être particulièrement évident. En fin de compte, vous ne pouvez interroger que sur la base de la clé primaire, ou évoluer progressivement vers un modèle de sous-base de données et de sous-table. Cependant, les sous-bases de données et les sous-tables posent beaucoup de problèmes d'exploitation, de maintenance et d'utilisation ; c'est pourquoi à cette époque, la clé primaire de la base de données NoSQL, abréviation de non seulement sql, a été progressivement développée et développée. s'est développé à mesure que la quantité de données a considérablement augmenté. En prenant hbase dans NoSQL comme exemple, il prend en charge les données TB et PB, ainsi que les colonnes. L'expansion est particulièrement flexible


Ce qui précède contient quelques réflexions et conceptions sur la migration des données de MySQL vers hbase. Pour plus de contenu connexe, veuillez prêter attention au site Web PHP chinois (www. .php.cn) !
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



