Bien qu'il existe des requêtes de jointure dans MySQL pour implémenter des requêtes de jointure multi-tables, les performances des requêtes de jointure sont très mauvaises, donc des sous-requêtes apparaissent.
1. Théoriquement, les sous-requêtes peuvent apparaître n'importe où dans l'instruction de requête, mais dans les applications pratiques, elles apparaissent souvent après from et after which. Les résultats de sous-requête qui apparaissent après "from" sont généralement multi-lignes et multi-colonnes, agissant comme des tables temporaires ; tandis que les résultats de sous-requête qui apparaissent après "where" sont généralement des lignes et des colonnes uniques, agissant comme des conditions :

2. Les sous-requêtes comme conditions après où sont souvent utilisées avec des opérateurs de comparaison tels que "=", "!=", ">" et "<". Bien que le résultat soit généralement une seule ligne et une seule colonne, parfois une seule ligne et plusieurs colonnes sont utilisées, et parfois plusieurs lignes et une seule colonne sont renvoyées. S'il s'agit de plusieurs lignes et de colonnes uniques, il est souvent utilisé en combinaison avec in, any, all, exist :
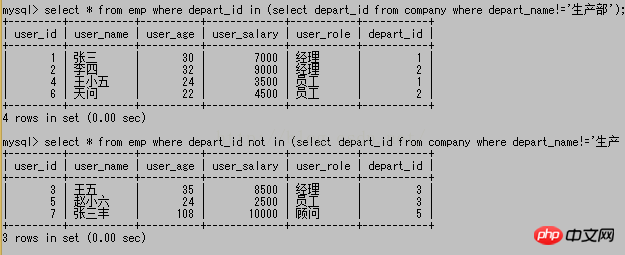
in et not in :
Parmi eux, in signifie toute personne incluse dans l'ensemble de résultats de sous-requête suivant, et not in signifie toute personne non incluse dans l'ensemble de résultats de sous-requête suivant. Dans le résultat de la sous-requête de la figure ci-dessus, le part_id renvoyé est 1, 2 et 4. Par conséquent, la première requête découvrira que tout le part_id dans emp est 1, 2 ou 4, et la deuxième requête découvrira que ce n'est ni 1 ni 4. 2 n'est pas 4 non plus.
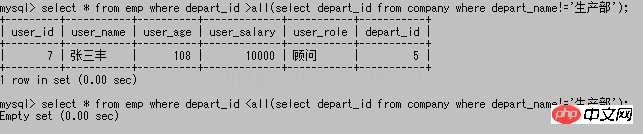
any :
= L'utilisation de any est la même que l'effet de in >any signifie qu'il est supérieur à la sous-requête ; jeu de résultats N'importe lequel est correct. Une compréhension simple est qu'il doit seulement être supérieur au plus petit dans le jeu de résultats ;
any doit seulement être supérieur à 1, et all :
>all signifie être supérieur à all dans l'ensemble de résultats de la sous-requête. Une compréhension simple est qu'il est plus grand que. le plus grand; Big existe :
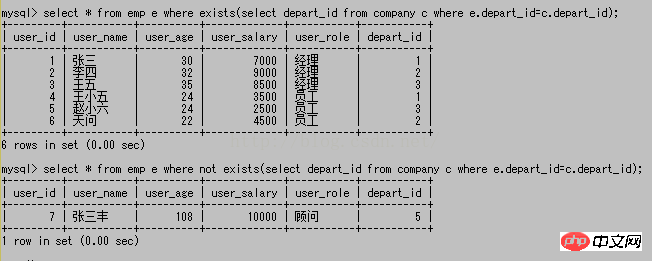
existe et n'existe pas, se soucie uniquement de savoir si la sous-requête suivante a des résultats, et Peu importe le résultat de la sous-requête ; car existe, si la sous-requête suivante a un résultat, alors sa valeur est vraie, sinon si aucun résultat n'est trouvé, elle est fausse, et n'existe pas, c'est tout le contraire. situation, et la valeur est fausse, aucune valeur n’est vraie. Lorsque leurs valeurs sont vraies, les résultats de la requête précédente sont établis et seront ajoutés au jeu de résultats de la requête principale. Dans le cas contraire, ils ne seront pas ajoutés au jeu de résultats de la requête principale. Dans la requête ci-dessus, l'instruction de requête interrogera d'abord une donnée de emp, puis comparera le part_id de ces données avec le part_id de company. Lorsqu'il y a deux données avec le même ID, il y en a. les résultats sont renvoyés, puis 6 éléments de données sont finalement renvoyés. La même raison est vraie pour la deuxième requête. Lorsqu'il n'y a pas deux données avec le même ID, la requête principale renverra des résultats et un seul élément de données. Ce qui précède est le contenu de la syntaxe des opérations de base communes de MySQL (10) ~~ sous-requête [mode ligne de commande]. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !




 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



