
 base de données
tutoriel mysql
Introduction détaillée de la partition range de la partition mysql
base de données
tutoriel mysql
Introduction détaillée de la partition range de la partition mysql
Introduction détaillée de la partition range de la partition mysql

Avec le développement d'Internet, il y a de plus en plus de données sous tous leurs aspects, comme en témoigne l'appel croissant pour le big data au cours des deux dernières années.
Bien que le projet que nous réalisons ne soit pas de grande envergure, en raison du volume d'affaires, il y a beaucoup de données.
Lorsqu'il y a trop de données, des problèmes de performances sont susceptibles de survenir. Pour résoudre ce problème, nous pensons généralement facilement au clustering, au sharding, etc.
Mais à un moment donné, il n'est pas nécessaire d'utiliser des clusters ou du sharding, et le partitionnement des données peut également être utilisé de manière appropriée.
Qu'est-ce qu'une cloison ?
Lorsque MySQL n'active pas la fonction de partition, le contenu d'une seule table de la base de données est stocké sur le système de fichiers sous la forme d'un seul fichier. Lorsque la fonction de partitionnement est activée, MySQL divisera le contenu d'une seule table en plusieurs fichiers et les stockera sur le système de fichiers selon les règles spécifiées par l'utilisateur. Le partitionnement est divisé en partitionnement horizontal et partitionnement vertical. Le partitionnement horizontal divise les données du tableau en différents fichiers de données par lignes, tandis que le partitionnement vertical divise les données du tableau en différents fichiers de données par colonnes. Le partage doit suivre les principes d’exhaustivité, de reconfigurabilité et de disjonction. L'exhaustivité signifie que toutes les données doivent être mappées sur un fragment. La reconfigurabilité signifie que toutes les données fragmentées doivent pouvoir être reconstruites en données globales. La disjonction signifie qu'il n'y a pas de duplication de données sur différentes partitions (sauf si vous les rendez délibérément redondantes).
Probablement en raison de diverses considérations, la table que nous avons utilisée utilise le partitionnement par plage. La base de données est gérée par d'autres, mais comme cette table est utilisée, j'ai pris le temps de le faire.
Pour autant que je sache, si vous souhaitez utiliser le partitionnement, vous devez utiliser l'instruction pour créer une partition lors de la création de la structure de la table, et elle ne peut pas être modifiée ultérieurement.
Par exemple, je crée une table emp simple avec trois champs : identifiant, nom et âge, puis je la partitionne en fonction de l'identifiant. L'instruction correcte de création de table est essentiellement la suivante :
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
Ici, je définis les données de la table entière à diviser en trois zones. La zone avec un identifiant inférieur à 6 est une zone, et la zone. le nom est p0 ; l'identifiant est compris entre 6 et 11. appartient à une zone, le nom de la zone est p1 alors toutes les zones avec un identifiant supérieur à 11 ont un nom de zone pmax ;
Organisez une syntaxe, essentiellement comme suit :
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
Ce qu'il faut noter ici, c'est que la dernière ligne de l'exemple, partitionne les valeurs pmax inférieures à maxvalue, dans cette phrase uniquement pmax, qui représente le nom de la partition, peut être obtenu arbitrairement, les mots restants ne peuvent pas être modifiés et maxvalue représente la valeur maximale de la condition de partitionnement ci-dessus.
Cela garantira que toutes les données peuvent être stockées normalement dans la base de données. Sinon, s'il n'y a pas de phrase de ce type, les données avec un identifiant supérieur ou égal à 11 ne seront pas stockées dans la base de données et une erreur sera signalée.
Après la création de la structure de la table, afin de tester si le partitionnement a réussi, j'ai inséré quelques données dans la table. L'instruction est la suivante :
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
Après l'insertion des données. est terminé, vérifiez si cela correspond à l'identifiant. Les données sont enregistrées dans la partition correspondante. Vous pouvez utiliser la commande pour interroger la partition, comme suit :
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
Le résultat de la requête est tel qu'indiqué dans la figure. : 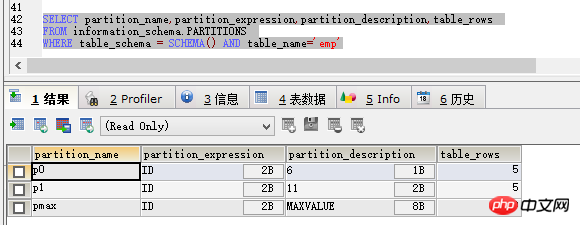
On peut voir que partition_name est le nom de la partition est le champ dont dépend la partition, partition_description peut être compris comme la condition de la partition et table_rows représente la quantité de données actuellement. dans la partition.
Les données ci-dessus montrent que le partitionnement est réussi. Cependant, bien que le partitionnement ci-dessus puisse éviter le problème de l'impossibilité d'être inséré, un nouveau problème est apparu.
C'est-à-dire que les données dans la dernière zone pmax peuvent être très volumineuses. Par conséquent, les données sont inégales et disproportionnées, ce qui peut entraîner des problèmes de performances lors de l'interrogation des données dans la dernière zone. Par conséquent, il existe environ trois solutions :
Premièrement, si vous pouvez contrôler les données du champ de partition, comme l'identifiant ici, si vous pouvez clairement savoir quand et quelle valeur ce sera, alors vous ne pouvez pas utilisez ce pmax au début, mais ajoutez régulièrement des partitions. Par exemple, si p0 et p1 existent ici, vous pouvez ajouter p2, p3 ou même plus lorsque l'identifiant est sur le point d'atteindre 11. Des exemples d'instructions pour ajouter des partitions sont les suivants :
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
La syntaxe est :
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
La méthode ci-dessus peut résoudre le problème des données disproportionnées, mais elle présente également des dangers cachés, c'est-à-dire que si vous oubliez d'ajouter des partitions ultérieures, ou si les valeurs des champs dont dépendent les partitions dépassent les attentes, cela peut entraîner le problème que les données ne peuvent pas être stockées dans la base de données. De cette façon, il existe deux façons de résoudre le problème :
Tout d'abord, vous pouvez utiliser le mécanisme de transaction et les procédures stockées de MySQL pour créer une tâche planifiée MySQL, puis demander au système de base de données d'ajouter des partitions à un moment précis. De cette façon, les problèmes mentionnés dans la première méthode ne se produiront fondamentalement pas, mais cette méthode nécessite une certaine compréhension des transactions MySQL et des procédures stockées, et elle est difficile à utiliser.
Je connais cette méthode, mais je ne l'ai pas encore implémentée. Je donnerai des exemples pertinents plus tard après en avoir appris davantage sur les transactions et les procédures stockées.
En plus de la méthode de tâche planifiée ci-dessus, il existe une autre façon de diviser la partition, c'est-à-dire d'utiliser la structure de table qui avait la partition pmax auparavant, puis d'utiliser l'instruction split partition pour la diviser pmax. Un exemple est le suivant :
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 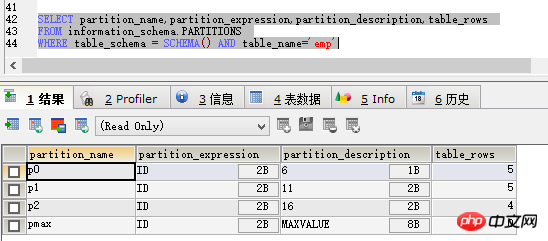
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 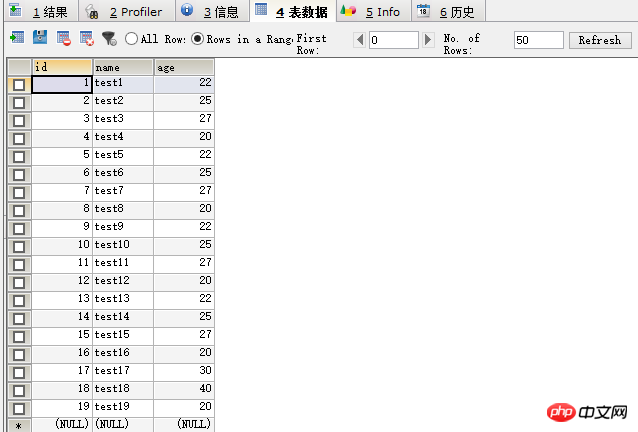
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 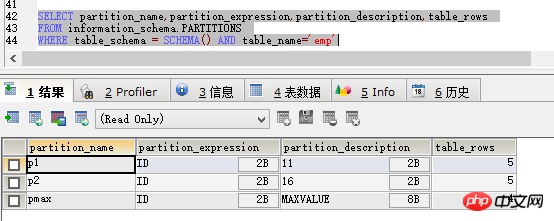
可以看到p0区不见了,在select * 一下,如图: 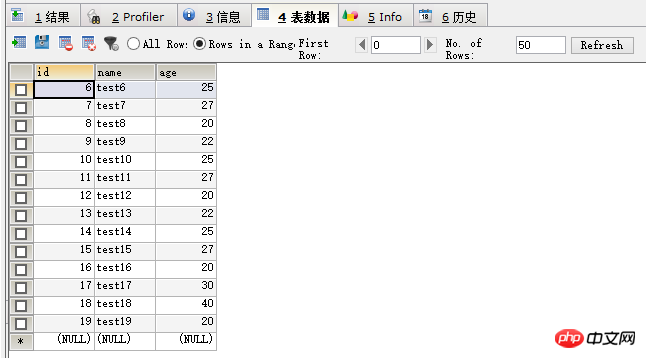
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(www.php.cn)!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
