
 développement back-end
Tutoriel C#.Net
Introduction détaillée aux directives de conception d'exceptions dans .net et d'autres architectures
développement back-end
Tutoriel C#.Net
Introduction détaillée aux directives de conception d'exceptions dans .net et d'autres architectures
Introduction détaillée aux directives de conception d'exceptions dans .net et d'autres architectures

Frontline
Pour les directives de conception d'exceptions, reportez-vous à Microsoft msdn, combinez votre propre compréhension et la gestion des erreurs d'exception dans les développements antérieurs, et résumez le logiciel architecture de développement , comment mieux concevoir un ensemble de critères d'erreur d'exception.
Introduction aux lignes directrices
Concept d'échec d'exécution
La signification de échec d'exécution : l'échec d'exécution se produit chaque fois qu'un membre ne peut pas faire ce qu'il a été conçu pour faire (ce que le nom du membre implique). Par exemple, si la méthode OpenFile ne peut pas renvoyer un descripteur de fichier ouvert à l'appelant, cela sera considéré comme un échec d'exécution.
Traduction :
La signification de l'échec de l'opération : chaque fois qu'un module membre ne peut pas terminer sa tâche attendue, on dit qu'un échec de l'opération s'est produit. Par exemple, la méthode OpenFile ne peut pas renvoyer un handle vers le fichier ouvert à l’appelant, ce qui constitue un échec d’opération.
Gestion des exceptions dans le Framework
Dans le Framework, les exceptions sont utilisées pour toutes les conditions d'erreur, y compris les erreurs d'exécution.
Traduction :
Dans le framework, les exceptions sont utilisées pour gérer toutes les conditions d'erreur, y compris les erreurs d'exécution.
Lignes directrices récapitulatives
Les méthodes qui doivent être interdites lors de la conception d'exceptions, celles qui doivent être faites sans hésitation et celles qui doivent être prises en compte sont répertoriées dans le tableau ci-dessous.
| 编号 | 方法 | 做法 |
|---|---|---|
| 1 | 返回错误代码 | 禁止 |
| 2 | 执行错误,要抛出异常;如OpenFile()未返回文件句柄 | 建议 |
| 3 | 假如代码再继续执行就变得不安全时,考虑是调用System.Environment.FailFast终止进程还是抛异常。 | 考虑 |
| 4 | 如果有可能的话,在正常的控制流处,抛异常,见下面的分析 | 禁止 |
| 5 | 抛异常对性能的影响。 | 考虑 |
| 6 | 协定中纳入异常处理部分 | 建议 |
| 7 | 将异常作为返回值返回 | 禁止 |
| 8 | 使用异常生成器方法,为避免代码膨胀, 用helper方法创建异常和属性. | 考虑 |
| 9 | 异常筛选器中抛出异常. | 禁止 |
| 10 | 从finally 块中显示地抛出异常 | 禁止 |
Explication de l'élément 4 :
Dans le codage quotidien, considérez le modèle Tester-Doer pour les membres qui peuvent lever des exceptions dans des scénarios courants pour éviter les problèmes de performances liés aux exceptions. Le modèle Tester-Doer lance un appel qui peut générer des exceptions en deux parties : un testeur et un Doer. Le testeur effectue un test pour l'état qui peut amener le Doer à lever une exception. test est inséré juste avant le code qui lève l'exception, se prémunissant ainsi contre l'exception. Exemple de code de http://www.php.cn/
Référence :
Tester et Doer effectuent chacun leurs propres tâches, réduisant parfaitement les exceptions et améliorant les performances. Doer : Si la surveillance de l'état ci-dessus est bonne, elle peut être traitée par DoProcess(); si elle est fausse, et si DoProcess() inclut la logique DoCheck(), une exception sera levée, mais après cette séparation, DoProcess ( ) ne lèvera pas d'exception !
if(DoCheck()==true)//这是Tester:状态监测
DoProcess();Il est recommandé d'envelopper l'interface d'opération exposée par la couche UI dans un essai {}catch{} bloc , l'exception levée dans le catch est écrite sur le disque.
2 Lorsqu'un minuteur est utilisé dans la couche UI,lorsqu'une exception se produit dans la fonction de rappel du compteur, le minuteur doit être arrêté pour empêcher l'écriture du journal des erreurs dans le déposer.
3Il est recommandé de ne pas envelopper le bloc try{}catch{} dans la couche inférieure Il est recommandé d'utiliser throw pour lancer une exception directement, car le try{} et. Les blocs catch{} sont encapsulés dans la couche UI, il n'y a donc pas besoin d'écrire dans ces couches.
4 throw interrompra directement les opérations futures et passera à la pile externe try{} et catch{}, c'est-à-dire la couche UI. Profitant de cette propriété,il est généralement recommandé que les fonctions le fassent. ne renvoie pas de codes d'erreur.
5 Une exception locale s'est produite lors du traitement des données importées par lots. Excel importe du personnel, des équipements, des plans, des matériaux, des processus, etc. Si une certaine ligne de données enfreint les règles, il n'est pas recommandé de lever une exception à ce stade, car une fois qu'une exception est levée, cela signifie que les données du les lignes suivantes ne peuvent pas être importées et les données importées deviennent des données sales. Il existe généralement deux approches : les données illégales apparaissent dans une certaine ligne et sont enregistrées dans le fichier journal. Plus tard, sur la base de ce fichier, il s'avère que les données n'ont pas été importées, puis celles-ci peuvent être traitées séparément. ;
Avant d'importer, vérifiez directement Après avoir vérifié si les données de toutes les lignes sont légales, importez une par une, sinon une invite apparaîtra et aucune donnée ne sera écrite dans la base de données. Cette dernière approche est généralement recommandée. Cette approche est appelée : Mode d'exception Tester-Doer, qui est également recommandé par Microsoft.
affiche les données correctes et les données illégales sont écrites dans le journal pour examen ; mais il est également possible que si les données principales dans l'interface affichée n'existent pas, une exception sera levée directement, écrite dans le journal et résolue via le journal. Par conséquent, elles doivent être traitées en fonction de la gravité des anomalies des données.
7 Sur la base des documents de développement, des journaux et des analyses,essayez de trouver la raison pour laquelle une certaine fonction n'est pas implémentée. Tout d’abord, conservez les documents de développement et vérifiez si les exigences actuelles des utilisateurs sont cohérentes avec celles des documents de développement. S'ils sont cohérents, le rôle du journal sera affiché à ce moment-là. Par exemple, un diagramme circulaire résumant l'achèvement de tous les processus en une semaine. S'il n'y a pas de données de processus, alors le diagramme circulaire peut ne pas exister. processus de développement, s'il est coché, cela ne signifie pas qu'il existe un processus. Si un processus n'est pas trouvé, une exception peut être levée. Si le processus est écrit dans le journal, la raison sera trouvée. Par conséquent, ce type de problème doit également être consigné dans le journal. Bien qu’il ne s’agisse pas d’une erreur, il peut être classé comme exception.
8 La fonction renvoie un objet dont les méthodes et propriétés sont référencées par une logique ultérieure. C'est inévitable ! Et la mise en œuvre de la plupart des fonctions en dépend. Étant donné que l'objet renvoyé sera référencé ultérieurement,est recommandé d'effectuer une comparaison nulle. S'il est nul, doit-il être transmis à la couche d'interface utilisateur et une invite de message apparaîtra, ou une exception sera levée directement. La couche d'interface utilisateur l'écrira dans le journal après le traitement, en fonction de la situation.
Ce qui précède est une introduction détaillée aux directives de conception d'exception dans .net et d'autres architectures. Pour plus de contenu connexe, veuillez prêter attention au PHP. Site chinois (www.php.cn) !

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
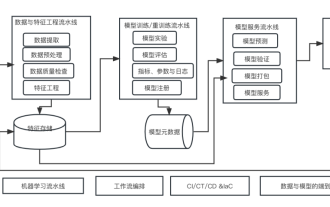 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
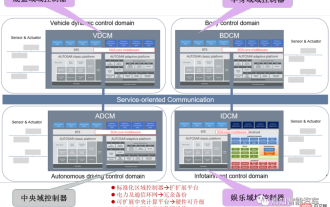 Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Conception d'architecture logicielle et méthodologie de découplage logiciel et matériel dans SOA
Apr 08, 2023 pm 11:21 PM
Pour la prochaine génération d'architecture électronique et électrique centralisée, l'utilisation d'une unité centrale de calcul centrale + zonale et d'une disposition de contrôleur régional est devenue une option incontournable pour divers OEM ou acteurs de niveau 1. Concernant l'architecture de l'unité centrale de calcul, il y en a trois. façons : séparation SOC, isolation matérielle, virtualisation logicielle. L'unité informatique centrale centralisée intégrera les fonctions commerciales de base des trois principaux domaines de la conduite autonome, du cockpit intelligent et du contrôle des véhicules. Le contrôleur régional standardisé a trois responsabilités principales : la distribution d'énergie, les services de données et la passerelle régionale. L’unité centrale de calcul intégrera donc un commutateur Ethernet haut débit. À mesure que le degré d'intégration de l'ensemble du véhicule devient de plus en plus élevé, de plus en plus de fonctions ECU seront lentement absorbées par le contrôleur régional. Et la plateforme
 Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
La courbe d'apprentissage de l'architecture du framework Go dépend de la familiarité avec le langage Go et le développement back-end ainsi que de la complexité du framework choisi : une bonne compréhension des bases du langage Go. Il est utile d’avoir une expérience en développement back-end. Les cadres qui diffèrent en complexité entraînent des différences dans les courbes d'apprentissage.
