
 Java
javaDidacticiel
Introduction détaillée aux opérations d'E/S Java et à l'optimisation avec des images et des textes
Java
javaDidacticiel
Introduction détaillée aux opérations d'E/S Java et à l'optimisation avec des images et des textes
Introduction détaillée aux opérations d'E/S Java et à l'optimisation avec des images et des textes

Cet article présente principalement en détail des informations pertinentes sur les opérations d'E/S Java et l'optimisation. Les amis qui en ont besoin peuvent se référer au
Résumé suivant :
Stream. est Un ensemble d'octets séquentiels avec un point de départ et un point de fin est un terme général ou une abstraction pour la transmission de données. Autrement dit, la transmission de données entre deux appareils est appelée flux. L'essence d'un flux est la transmission de données. Le flux est divisé en différentes catégories en fonction des caractéristiques de transmission de données pour faciliter des opérations de données plus intuitives.
Java I/O
I/O, l'abréviation de Input/Output (entrée/sortie). En ce qui concerne les E/S, il existe conceptuellement 5 modèles : E/S bloquantes, E/S non bloquantes, multiplexage d'E/S (sélection et interrogation), E/S pilotées par signal (SIGIO), E/S asynchrones (le POSIX aio_functions). Différents systèmes d'exploitation prennent en charge différemment les modèles ci-dessus et UNIX prend en charge le multiplexage d'E/S. Différents systèmes ont des noms différents. Sous FreeBSD, cela s'appelle kqueue et sous Linux, cela s'appelle epoll. IOCP est né dans Windows 2000 pour prendre en charge les E/S asynchrones.
Java est un langage multiplateforme. Afin de prendre en charge les E/S asynchrones, NIO1.0 introduit dans Java1.4 est basé sur la réutilisation des E/S et choisira différentes options. chaque plateforme. Linux utilise epoll, BSD utilise kqueue et Windows utilise des E/S superposées.
Les méthodes pertinentes d'E/S Java sont les suivantes :
Synchronisation et blocage (méthode d'E/S) : Le mode d'implémentation du serveur démarre un thread pour une connexion , chaque fois qu'un thread gère les E/S personnellement et attend que les E/S soient terminées, c'est-à-dire que lorsque le client a une demande de connexion, le serveur doit démarrer un thread pour le traitement. Mais si cette connexion ne fait rien, cela entraînera une surcharge inutile des threads. Bien entendu, cette lacune peut être améliorée grâce au mécanisme de pool de threads. La limitation des E/S est qu’il s’agit d’un processus orienté flux, bloquant et série. Les E/S de connexion Socket de chaque client nécessitent un thread à traiter, et pendant cette période, ce thread est occupé jusqu'à ce que le Socket soit fermé. Pendant cette période, les connexions TCP, la lecture et le retour des données sont tous bloqués. En d’autres termes, de nombreuses tranches de temps CPU et ressources mémoire occupées par les threads ont été gaspillées pendant cette période. De plus, chaque fois qu'une connexion Socket est établie, un nouveau thread est créé pour communiquer séparément avec le Socket (en bloquant la communication). Cette méthode a une vitesse de réponse rapide et est facile à contrôler. C'est très efficace lorsque le nombre de connexions est petit, mais générer un thread pour chaque connexion est sans aucun doute un gaspillage de ressources système. Si le nombre de connexions est important, les ressources seront insuffisantes
. Synchrone non bloquant (méthode NIO) : le mode d'implémentation du serveur démarre un thread pour une requête, et chaque thread gère les E/S personnellement, mais d'autres threads interrogent pour vérifier si les E/S sont prêtes, sans attendre les E/S. O pour terminer. Autrement dit, les demandes de connexion envoyées par le client seront enregistrées sur le multiplexeur, et le multiplexeur ne démarrera un thread à traiter que lorsqu'il y aura une demande d'E/S pour la connexion. NIO est orienté tampon, non bloquant et basé sur un sélecteur. Il utilise un thread pour interroger et surveiller plusieurs canaux de transmission de données. Quel canal est prêt (c'est-à-dire qu'il existe un ensemble de données qui peuvent être traitées). . Le serveur enregistre une liste de connexions Socket, puis interroge cette liste. S'il détecte qu'il y a des données à lire sur un certain port Socket, l'opération de lecture correspondante de la connexion Socket est appelée ; à écrire sur un certain port Socket. , l'opération d'écriture correspondante de la connexion Socket est appelée ; si la connexion Socket d'un certain port a été interrompue, la méthode destructrice correspondante est appelée pour fermer le port. Cela peut utiliser pleinement les ressources du serveur et améliorer considérablement l'efficacité ;
Non bloquant asynchrone (méthode AIO, version JDK7) : le mode d'implémentation du serveur démarre un thread pour une requête valide, et le client I Requête /O Le système d'exploitation le termine d'abord, puis informe l'application serveur de démarrer le thread pour le traitement. Chaque thread n'a pas à gérer les E/S personnellement, mais les délègue au système d'exploitation, et il n'est pas nécessaire d'attendre. pour que les E/S soient terminées. Si l'opération est terminée, le système vous en informera ultérieurement. Ce mode utilise le modèle epoll de Linux.
Lorsque le nombre de connexions est faible, le mode E/S traditionnel est plus facile à écrire et plus simple à utiliser. Cependant, à mesure que le nombre de connexions continue d'augmenter, le traitement des E/S traditionnel nécessite un thread pour chaque connexion. Lorsque le nombre de threads est faible, l'efficacité du programme augmente à mesure que le nombre de threads augmente. , Il diminue à mesure que le nombre de threads augmente. Ainsi, le goulot d’étranglement du blocage traditionnel des E/S est qu’il ne peut pas gérer trop de connexions. Le but des E/S non bloquantes est de résoudre ce goulot d’étranglement. Il n'y a aucun lien entre le nombre de threads pour les connexions de traitement des E/S non bloquantes et le nombre de connexions. Par exemple, si le système gère 10 000 connexions, les E/S non bloquantes n'ont pas besoin de démarrer 10 000 threads. ou 2 000 threads pour le traitement. Étant donné que les IO non bloquantes gèrent les connexions de manière asynchrone, lorsqu'une connexion envoie une requête au serveur, le serveur traite la demande de connexion comme un « événement » de demande et attribue cet « événement » à la fonction correspondante pour traitement. Nous pouvons placer cette fonction de traitement dans un thread pour exécution et renvoyer le thread après l'exécution, afin qu'un thread puisse traiter plusieurs événements de manière asynchrone. Les threads d’E/S bloquants passent la plupart de leur temps à attendre les requêtes.
Java NIO
Le package Java.nio est un nouveau package ajouté à Java après la version 1.4, spécifiquement utilisé pour améliorer l'efficacité des opérations d'E/S.
Le tableau 1 montre la comparaison entre les E/S et NIO.
Tableau 1. E/S VS NIO
| I/O | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞 IO | 非阻塞 IO |
| 无 | 选择器 |
NIO est basé sur des blocs, qui traitent les données en blocs comme unité de base. Dans NIO, les deux composants les plus importants sont le tampon et le canal. Le tampon est un bloc de mémoire continu et constitue le lieu de transfert permettant à NIO de lire et d'écrire des données. Le canal identifie la source ou la destination des données mises en mémoire tampon. Il est utilisé pour lire ou écrire des données dans le tampon et constitue l'interface d'accès au tampon. Le canal est un canal bidirectionnel, qui peut être lu ou écrit. Le flux est à sens unique. L'application ne peut pas lire et écrire directement le canal, mais doit le faire via le tampon, c'est-à-dire que le canal lit et écrit les données via le tampon.
L'utilisation de Buffer pour lire et écrire des données suit généralement les quatre étapes suivantes :
Écrire des données dans Buffer
Appeler ; méthode flip ();
lit les données du Buffer
appelle la méthode clear() ou la méthode compact().
Lorsque des données sont écrites dans le tampon, le tampon enregistrera la quantité de données écrites. Une fois que vous souhaitez lire des données, vous devez faire passer le Buffer du mode écriture au mode lecture via la méthode flip(). En mode lecture, toutes les données précédemment écrites dans le Buffer peuvent être lues.
Une fois toutes les données lues, le tampon doit être vidé pour pouvoir y être réécrit. Il existe deux manières de vider le tampon : en appelant la méthode clear() ou compact(). La méthode clear() efface tout le tampon. La méthode compact() efface uniquement les données lues. Toutes les données non lues sont déplacées au début du tampon et les données nouvellement écrites sont placées après les données non lues dans le tampon.
Il existe de nombreux types de tampons, et différents tampons offrent différentes manières d'exploiter les données dans le tampon.
Figure 1 Diagramme hiérarchique de l'interface Buffer
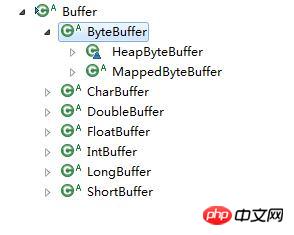
Il existe deux situations dans lesquelles Buffer écrit des données :
Écrire du canal vers le tampon. Par exemple, dans l'exemple, Channel lit les données du fichier et les écrit dans Channel
appelle directement la méthode put pour y écrire des données.
Il existe deux façons de lire les données de Buffer :
-
Lire les données de Buffer vers Channel ;
Utilisez la méthode get() pour lire les données du Buffer.
La méthode rewin de Buffer remet la position à 0, afin que vous puissiez relire toutes les données dans Buffer. La limite reste inchangée et indique toujours combien d'éléments (octet, caractère, etc.) peuvent être lus à partir du Buffer.
Méthodes clear() et compact()
Une fois les données du Buffer lues, le Buffer doit être prêt à être réécrit. Cela peut être fait via les méthodes clear() ou compact().
Si la méthode clear() est appelée, la position sera remise à 0 et la limite sera fixée à la valeur de capacité. En d’autres termes, le Buffer est vidé. Les données du Buffer ne sont pas effacées, mais ces marques nous indiquent par où commencer à écrire les données dans le Buffer.
S'il y a des données non lues dans le Buffer et que vous appelez la méthode clear(), les données seront "oubliées", ce qui signifie qu'il n'y aura plus de marqueurs pour vous indiquer quelles données ont été lues et ce qui n'est pas le cas. S'il y a encore des données non lues dans le tampon et que les données sont nécessaires plus tard, mais que vous souhaitez d'abord écrire des données, utilisez la méthode compact(). La méthode compact() copie toutes les données non lues au début du Buffer. Ensuite, définissez la position juste après le dernier élément non lu. L'attribut limit est toujours défini sur capacité, tout comme la méthode clear(). Le tampon est maintenant prêt à écrire des données, mais les données non lues ne seront pas écrasées.
Paramètres du tampon
Le tampon a trois paramètres importants : la position, la capacité et la limite.
La capacité fait référence à la taille du tampon, qui a été déterminée lors de la création du tampon.
limite Lorsque le Buffer est en mode écriture, il fait référence à la quantité de données qui peuvent être écrites ; lorsqu'il est en mode lecture, il fait référence à la quantité de données qui peuvent être lues.
position Lorsque le Buffer est en mode écriture, il fait référence à la position des prochaines données à écrire ; en mode lecture, il fait référence à la position des données actuelles à lire. Chaque fois qu'une donnée est lue ou écrite, la position 1, c'est-à-dire la limite et la position, ont des significations différentes lors de la lecture/écriture du tampon. Lors de l'appel de la méthode flip de Buffer et du passage du mode écriture au mode lecture, limite (lecture) = position (écriture), position (lecture) = 0.
Diffusion et agrégation
NIO fournit des méthodes de traitement des données structurées, appelées Scattering and Gathering. La diffusion fait référence à la lecture de données dans un ensemble de tampons, et non dans un seul. L'agrégation, quant à elle, écrit les données dans un ensemble de tampons. L'utilisation de base de la diffusion et de l'agrégation est assez similaire à celle utilisée lors du fonctionnement sur un seul tampon. Dans une lecture dispersée, les canaux remplissent chaque tampon à tour de rôle. Une fois qu'un tampon est rempli, il commence à remplir le suivant, dans un sens, le tableau de tampons est comme un gros tampon. Lorsque la structure spécifique du fichier est connue, plusieurs tampons peuvent être construits conformément à la structure du fichier, de sorte que la taille de chaque tampon corresponde exactement à la taille de chaque structure de segment du fichier. À ce stade, le contenu peut être assemblé dans chaque tampon correspondant en une seule fois grâce à une lecture dispersée, simplifiant ainsi l'opération. Si vous devez créer un fichier dans un format spécifié, il vous suffit d'abord de construire un objet Buffer de taille appropriée et d'utiliser la méthode d'écriture globale pour créer rapidement le fichier. Le listing 1 utilise FileChannel comme exemple pour montrer comment utiliser la diffusion et le rassemblement pour lire et écrire des fichiers structurés.
Listing 1. Lecture et écriture de fichiers structurés par diffusion et rassemblement
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class NIOScatteringandGathering {
public void createFiles(String TPATH){
try {
ByteBuffer bookBuf = ByteBuffer.wrap("java 性能优化技巧".getBytes("utf-8"));
ByteBuffer autBuf = ByteBuffer.wrap("test".getBytes("utf-8"));
int booklen = bookBuf.limit();
int autlen = autBuf.limit();
ByteBuffer[] bufs = new ByteBuffer[]{bookBuf,autBuf};
File file = new File(TPATH);
if(!file.exists()){
try {
file.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
try {
FileOutputStream fos = new FileOutputStream(file);
FileChannel fc = fos.getChannel();
fc.write(bufs);
fos.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ByteBuffer b1 = ByteBuffer.allocate(booklen);
ByteBuffer b2 = ByteBuffer.allocate(autlen);
ByteBuffer[] bufs1 = new ByteBuffer[]{b1,b2};
File file1 = new File(TPATH);
try {
FileInputStream fis = new FileInputStream(file);
FileChannel fc = fis.getChannel();
fc.read(bufs1);
String bookname = new String(bufs1[0].array(),"utf-8");
String autname = new String(bufs1[1].array(),"utf-8");
System.out.println(bookname+" "+autname);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args){
NIOScatteringandGathering nio = new NIOScatteringandGathering();
nio.createFiles("C://1.TXT");
}
}Le résultat est présenté dans le listing 2 ci-dessous .
Listing 2. Résultats d'exécution
java 性能优化技巧 test
Le code affiché dans le Listing 3 concerne les E/S traditionnelles et les octets. basé sur NIO Les performances de trois méthodes NIO basées sur le mappage de mémoire ont été comparées, en utilisant les opérations de lecture et d'écriture fastidieuses d'un fichier contenant 4 millions de données comme base d'évaluation.
Listing 3. Test comparatif de trois méthodes d'E/S
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class NIOComparator {
public void IOMethod(String TPATH){
long start = System.currentTimeMillis();
try {
DataOutputStream dos = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream(new File(TPATH))));
for(int i=0;i<4000000;i++){
dos.writeInt(i);//写入 4000000 个整数
}
if(dos!=null){
dos.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
try {
DataInputStream dis = new DataInputStream(
new BufferedInputStream(new FileInputStream(new File(TPATH))));
for(int i=0;i<4000000;i++){
dis.readInt();
}
if(dis!=null){
dis.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public void ByteMethod(String TPATH){
long start = System.currentTimeMillis();
try {
FileOutputStream fout = new FileOutputStream(new File(TPATH));
FileChannel fc = fout.getChannel();//得到文件通道
ByteBuffer byteBuffer = ByteBuffer.allocate(4000000*4);//分配 Buffer
for(int i=0;i<4000000;i++){
byteBuffer.put(int2byte(i));//将整数转为数组
}
byteBuffer.flip();//准备写
fc.write(byteBuffer);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
FileInputStream fin;
try {
fin = new FileInputStream(new File(TPATH));
FileChannel fc = fin.getChannel();//取得文件通道
ByteBuffer byteBuffer = ByteBuffer.allocate(4000000*4);//分配 Buffer
fc.read(byteBuffer);//读取文件数据
fc.close();
byteBuffer.flip();//准备读取数据
while(byteBuffer.hasRemaining()){
byte2int(byteBuffer.get(),byteBuffer.get(),byteBuffer.get(),byteBuffer.get());//将 byte 转为整数
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public void mapMethod(String TPATH){
long start = System.currentTimeMillis();
//将文件直接映射到内存的方法
try {
FileChannel fc = new RandomAccessFile(TPATH,"rw").getChannel();
IntBuffer ib = fc.map(FileChannel.MapMode.READ_WRITE, 0, 4000000*4).asIntBuffer();
for(int i=0;i<4000000;i++){
ib.put(i);
}
if(fc!=null){
fc.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
try {
FileChannel fc = new FileInputStream(TPATH).getChannel();
MappedByteBuffer lib = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
lib.asIntBuffer();
while(lib.hasRemaining()){
lib.get();
}
if(fc!=null){
fc.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public static byte[] int2byte(int res){
byte[] targets = new byte[4];
targets[3] = (byte)(res & 0xff);//最低位
targets[2] = (byte)((res>>8)&0xff);//次低位
targets[1] = (byte)((res>>16)&0xff);//次高位
targets[0] = (byte)((res>>>24));//最高位,无符号右移
return targets;
}
public static int byte2int(byte b1,byte b2,byte b3,byte b4){
return ((b1 & 0xff)<<24)|((b2 & 0xff)<<16)|((b3 & 0xff)<<8)|(b4 & 0xff);
}
public static void main(String[] args){
NIOComparator nio = new NIOComparator();
nio.IOMethod("c://1.txt");
nio.ByteMethod("c://2.txt");
nio.ByteMethod("c://3.txt");
}
}Le résultat courant du Listing 3 est le suivant montré dans le Listing 4 Show.
Listing 4. Exécuter la sortie
1139 906 296 157 234 125
En plus de la description ci-dessus et du code affiché dans le listing 3, les NIO Buffer Fournit également une classe DirectBuffer qui peut accéder directement à la mémoire physique du système. DirectBuffer hérite de ByteBuffer, mais est différent du ByteBuffer ordinaire. Ordinary ByteBuffer alloue toujours de l'espace sur le tas JVM, et sa mémoire maximale est limitée par le tas maximum, tandis que DirectBuffer est directement alloué sur la mémoire physique et n'occupe pas d'espace de tas. Lors de l'accès à un ByteBuffer normal, le système utilise toujours un "tampon de noyau" pour les opérations indirectes. L'emplacement de DirectrBuffer est équivalent à ce « tampon noyau ». Par conséquent, l’utilisation de DirectBuffer est une méthode plus proche du système sous-jacent, elle est donc plus rapide que ByteBuffer ordinaire. Comparé à ByteBuffer, DirectBuffer a des vitesses d'accès en lecture et en écriture beaucoup plus rapides, mais le coût de création et de destruction de DirectrBuffer est plus élevé que ByteBuffer. Le code qui compare DirectBuffer à ByteBuffer est présenté dans le listing 5.
Listing 5. DirectBuffer VS ByteBuffer
import java.nio.ByteBuffer;
public class DirectBuffervsByteBuffer {
public void DirectBufferPerform(){
long start = System.currentTimeMillis();
ByteBuffer bb = ByteBuffer.allocateDirect(500);//分配 DirectBuffer
for(int i=0;i<100000;i++){
for(int j=0;j<99;j++){
bb.putInt(j);
}
bb.flip();
for(int j=0;j<99;j++){
bb.getInt(j);
}
}
bb.clear();
long end = System.currentTimeMillis();
System.out.println(end-start);
start = System.currentTimeMillis();
for(int i=0;i<20000;i++){
ByteBuffer b = ByteBuffer.allocateDirect(10000);//创建 DirectBuffer
}
end = System.currentTimeMillis();
System.out.println(end-start);
}
public void ByteBufferPerform(){
long start = System.currentTimeMillis();
ByteBuffer bb = ByteBuffer.allocate(500);//分配 DirectBuffer
for(int i=0;i<100000;i++){
for(int j=0;j<99;j++){
bb.putInt(j);
}
bb.flip();
for(int j=0;j<99;j++){
bb.getInt(j);
}
}
bb.clear();
long end = System.currentTimeMillis();
System.out.println(end-start);
start = System.currentTimeMillis();
for(int i=0;i<20000;i++){
ByteBuffer b = ByteBuffer.allocate(10000);//创建 ByteBuffer
}
end = System.currentTimeMillis();
System.out.println(end-start);
}
public static void main(String[] args){
DirectBuffervsByteBuffer db = new DirectBuffervsByteBuffer();
db.ByteBufferPerform();
db.DirectBufferPerform();
}
}La sortie en cours d'exécution est affichée dans le Listing 6.
Listing 6. Exécuter la sortie
920 110 531 390
Comme le montre le listing 6, le coût de la création et de la destruction fréquentes DirectBuffer est bien supérieur à Allouer de l'espace mémoire sur le tas. Utilisez les paramètres -XX:MaxDirectMemorySize=200M –Xmx200M pour configurer le DirectBuffer maximum et l'espace de tas maximum dans les arguments de la VM. Le code demande respectivement 200 Mo d'espace de tas. Si l'espace de tas défini est trop petit, par exemple 1 Mo, une erreur sera générée. comme indiqué dans le listing 7 illustré.
Listing 7. Erreur d'exécution
Error occurred during initialization of VM Too small initial heap for new size specified
Les informations DirectBuffer ne seront pas imprimées dans le GC, car le GC enregistre uniquement Récupération de mémoire de l'espace du tas. On peut voir que puisque ByteBuffer alloue de l'espace sur le tas, son tableau GC est relativement fréquent. Dans les situations où Buffer doit être créé fréquemment, DirectBuffer ne doit pas être utilisé car le code pour créer et détruire DirectBuffer est relativement coûteux. Cependant, si DirectBuffer peut être réutilisé, les performances du système peuvent être grandement améliorées. Le listing 8 est un morceau de code pour surveiller DirectBuffer.
Listing 8. L'exécution du code de surveillance DirectBuffer
import java.lang.reflect.Field;
public class monDirectBuffer {
public static void main(String[] args){
try {
Class c = Class.forName("java.nio.Bits");//通过反射取得私有数据
Field maxMemory = c.getDeclaredField("maxMemory");
maxMemory.setAccessible(true);
Field reservedMemory = c.getDeclaredField("reservedMemory");
reservedMemory.setAccessible(true);
synchronized(c){
Long maxMemoryValue = (Long)maxMemory.get(null);
Long reservedMemoryValue = (Long)reservedMemory.get(null);
System.out.println("maxMemoryValue="+maxMemoryValue);
System.out.println("reservedMemoryValue="+reservedMemoryValue);
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (NoSuchFieldException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}est présentée dans le Listing 9.
Listing 9. Exécuter la sortie
maxMemoryValue=67108864 reservedMemoryValue=0
NIO étant difficile à utiliser, de nombreuses entreprises ont lancé leur propre JDK packagé Frameworks NIO, tels que Mina d'Apache, Netty de JBoss, Grizzly de Sun, etc., ces frameworks encapsulent directement le protocole TCP ou UDP de la couche de transport. Netty n'est qu'un framework NIO. Il ne nécessite pas de support supplémentaire de la part du conteneur Web. c'est-à-dire que le conteneur Web n'est pas limité.
Java AIO
Classes et interfaces liées à AIO :
java.nio.channels.AsynchronousChannel:标记一个 Channel 支持异步 IO 操作; java.nio.channels.AsynchronousServerSocketChannel:ServerSocket 的 AIO 版本,创建 TCP 服务端,绑定地址,监听端口等; java.nio.channels.AsynchronousSocketChannel:面向流的异步 Socket Channel,表示一个连接; java.nio.channels.AsynchronousChannelGroup:异步 Channel 的分组管理,目的是为了资源共享。 一个 AsynchronousChannelGroup 绑定一个线程池,这个线程池执行两个任务:处理 IO 事件和派发 CompletionHandler。AsynchronousServerSocketChannel 创建的时候可以传入一个 AsynchronousChannelGroup,那么通过 AsynchronousServerSocketChannel 创建的 AsynchronousSocketChannel 将同属于一个组,共享资源; java.nio.channels.CompletionHandler:异步 IO 操作结果的回调接口,用于定义在 IO 操作完成后所作的回调工作。 AIO 的 API 允许两种方式来处理异步操作的结果:返回的 Future 模式或者注册 CompletionHandler,推荐用 CompletionHandler 的方式, 这些 handler 的调用是由 AsynchronousChannelGroup 的线程池派发的。这里线程池的大小是性能的关键因素。
Voici un exemple de programme pour une brève introduction Jetons un coup d'œil au fonctionnement d'AIO.
Listing 10. Programme serveur
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
import java.util.concurrent.ExecutionException;
public class SimpleServer {
public SimpleServer(int port) throws IOException {
final AsynchronousServerSocketChannel listener =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(port));
//监听消息,收到后启动 Handle 处理模块
listener.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
public void completed(AsynchronousSocketChannel ch, Void att) {
listener.accept(null, this);// 接受下一个连接
handle(ch);// 处理当前连接
}
@Override
public void failed(Throwable exc, Void attachment) {
// TODO Auto-generated method stub
}
});
}
public void handle(AsynchronousSocketChannel ch) {
ByteBuffer byteBuffer = ByteBuffer.allocate(32);//开一个 Buffer
try {
ch.read(byteBuffer).get();//读取输入
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
byteBuffer.flip();
System.out.println(byteBuffer.get());
// Do something
}
}Listing 11. Programme client
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleClientClass {
private AsynchronousSocketChannel client;
public SimpleClientClass(String host, int port) throws IOException,
InterruptedException, ExecutionException {
this.client = AsynchronousSocketChannel.open();
Future<?> future = client.connect(new InetSocketAddress(host, port));
future.get();
}
public void write(byte b) {
ByteBuffer byteBuffer = ByteBuffer.allocate(32);
System.out.println("byteBuffer="+byteBuffer);
byteBuffer.put(b);//向 buffer 写入读取到的字符
byteBuffer.flip();
System.out.println("byteBuffer="+byteBuffer);
client.write(byteBuffer);
}
}Listing 12.Fonction principale
import java.io.IOException;
import java.util.concurrent.ExecutionException;
import org.junit.Test;
public class AIODemoTest {
@Test
public void testServer() throws IOException, InterruptedException {
SimpleServer server = new SimpleServer(9021);
Thread.sleep(10000);//由于是异步操作,所以睡眠一定时间,以免程序很快结束
}
@Test
public void testClient() throws IOException, InterruptedException, ExecutionException {
SimpleClientClass client = new SimpleClientClass("localhost", 9021);
client.write((byte) 11);
}
public static void main(String[] args){
AIODemoTest demoTest = new AIODemoTest();
try {
demoTest.testServer();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
demoTest.testClient();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Il y aura un article spécial plus tard Introduction détaillée et approfondie du code source, des concepts de conception, des modèles de conception, etc.
Conclusion
Une différence importante entre les E/S et NIO est que lorsque nous utilisons les E/S, nous introduisons souvent le multi-threading. Chaque connexion utilise un thread séparé, tandis que NIO utilise un seul thread ou seulement un petit nombre de multi-threads. . , chaque connexion partage un thread. Étant donné que la nature non bloquante de NIO nécessite une interrogation constante, qui consomme des ressources système, le mode asynchrone non bloquant AIO est né. Cet article présente un par un les trois modes de fonctionnement d'entrée et de sortie tels que E/S, NIO et AIO, et s'efforce de permettre aux lecteurs de maîtriser les opérations de base et les méthodes d'optimisation à travers des descriptions et des exemples simples.
Ce qui précède est une introduction détaillée au fonctionnement et à l'optimisation des E/S Java avec des images et des textes. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
 PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP est un langage de script largement utilisé du côté du serveur, particulièrement adapté au développement Web. 1.Php peut intégrer HTML, traiter les demandes et réponses HTTP et prend en charge une variété de bases de données. 2.PHP est utilisé pour générer du contenu Web dynamique, des données de formulaire de traitement, des bases de données d'accès, etc., avec un support communautaire solide et des ressources open source. 3. PHP est une langue interprétée, et le processus d'exécution comprend l'analyse lexicale, l'analyse grammaticale, la compilation et l'exécution. 4.PHP peut être combiné avec MySQL pour les applications avancées telles que les systèmes d'enregistrement des utilisateurs. 5. Lors du débogage de PHP, vous pouvez utiliser des fonctions telles que error_reportting () et var_dump (). 6. Optimiser le code PHP pour utiliser les mécanismes de mise en cache, optimiser les requêtes de base de données et utiliser des fonctions intégrées. 7
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
