
 base de données
tutoriel mysql
Optimisation MySQL - explication détaillée du code de sauvegarde et de récupération (image)
base de données
tutoriel mysql
Optimisation MySQL - explication détaillée du code de sauvegarde et de récupération (image)
Optimisation MySQL - explication détaillée du code de sauvegarde et de récupération (image)

Utilisez la sauvegarde de commande MYSQLDUMP
MYSQLDUMP est un outil de sauvegarde de base de données très utile fourni par MYSQL. Lorsque la commande mysqldump est exécutée, la base de données est sauvegardée dans un fichier texte. Le fichier contient en fait plusieurs instructions CREATE et INSERT. Vous pouvez utiliser ces instructions pour recréer la table et insérer des données syntaxe MYSQLDUMP et. options
mysqldump fournit de nombreuses options, notamment le débogage et la compression. Voici les plus utiles. Exécutez la commande d'aide mysqldump --help pour obtenir une liste complète des options pour une version spécifique
user représente le nom d'utilisateur host représente le nom d'hôte du ; utilisateur connecté ; pwd est le mot de passe de connexion ; dbname est le nom de la base de données qui doit être sauvegardéemysqldump -u user -p pwd -h host dbname[tbname,[tbname...]]>filename.sql 选项/Option 作用/Action Performed --add-drop-table 这个选项将会在每一个表的前面加上DROP TABLE IF EXISTS语句,这样可以保证导回MySQL数据库的时候不会出错,因为每次导回的时候,都会首先检查表是否存在,存在就删除 --add-locks 这个选项会在INSERT语句中捆上一个LOCK TABLE和UNLOCK TABLE语句。这就防止在这些记录被再次导入数据库时其他用户对表进行的操作 -c or - complete_insert 这个选项使得mysqldump命令给每一个产生INSERT语句加上列(field)的名字。当把数据导出导另外一个数据库时这个选项很有用。 --delayed-insert 在INSERT命令中加入DELAY选项 -F or -flush-logs 使用这个选项,在执行导出之前将会刷新MySQL服务器的log. -f or -force 使用这个选项,即使有错误发生,仍然继续导出 --full 这个选项把附加信息也加到CREATE TABLE的语句中 -l or -lock-tables 使用这个选项,导出表的时候服务器将会给表加锁。 -t or -no-create- info 这个选项使的mysqldump命令不创建CREATE TABLE语句,这个选项在您只需要数据而不需要DDL(数据库定义语句)时很方便。 -d or -no-data 这个选项使的mysqldump命令不创建INSERT语句。 在您只需要DDL语句时,可以使用这个选项。 --opt 此选项将打开所有会提高文件导出速度和创造一个可以更快导入的文件的选项。 -q or -quick 这个选项使得MySQL不会把整个导出的内容读入内存再执行导出,而是在读到的时候就写入导文件中。 -T path or -tab = path 这个选项将会创建两个文件,一个文件包含DDL语句或者表创建语句,另一个文件包含数据。 DDL文件被命名为table_name.sql,数据文件被命名为table_name.txt.路径名是存放这两个文件的目录。目录必须已经存在,并且命令的使用者有对文件的特权。 -w "WHERE Clause" or -where = "Where clause " 如前面所讲的,您可以使用这一选项来过筛选将要放到 导出文件的数据。 假定您需要为一个表单中要用到的帐号建立一个文件,经理要看今年(2004年)所有的订单(Orders),它们并不对DDL感兴趣,并且需要文件有逗号分隔, 因为这样就很容易导入到Excel中。 为了完成这个任务,您可以使用下面的句子: bin/mysqldump –p –where "Order_Date >='2000-01-01'" –tab = /home/mark –no-create-info –fields-terminated-by=, Meet_A_Geek Orders 这将会得到您想要的结果。 schema:模式 The set of statements, expressed in data definition language, that completely describe the structure of a data base. 一组以数据定义语言来表达的语句集,该语句集完整地描述了数据库的结构。 SELECT INTO OUTFILE :
tbname est la table de données qui doit être sauvegardée ; être sauvegardé dans la base de données dbname. Vous pouvez spécifier plusieurs tables qui doivent être sauvegardées ;
filename est le nom du fichier de sauvegarde
1. Utilisez mysqldump pour sauvegarder toutes les tables dans une seule base de donnéesLes enregistrements de la base de données sont comme ceci
Ouvrez cmd, puis exécutez ce qui suit Utilisez la commande
pour voir que le fichier school_2014-7-10.sql a été généré sous le lecteur C
Ouvrez ce fichier sql avec editplus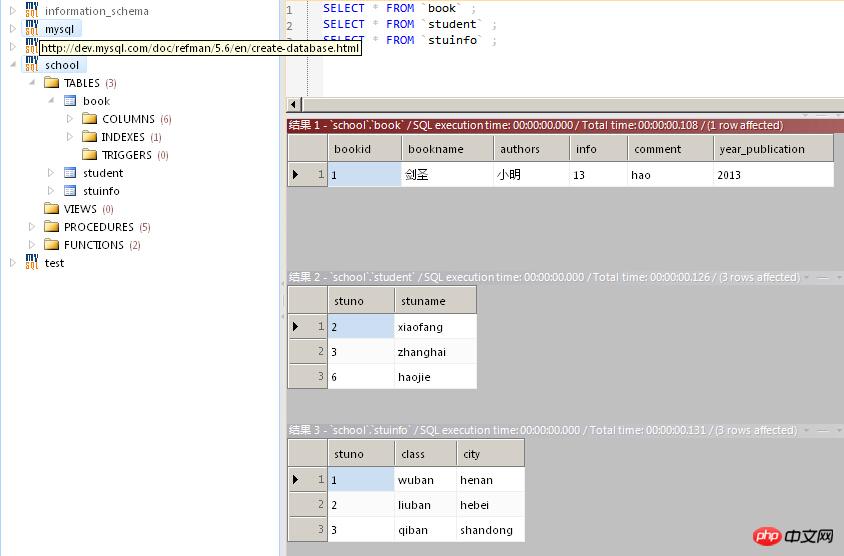
 Vous pouvez voir que le fichier de sauvegarde contient des informations, qui sont indiquées au début du fichier. Le numéro de version de l'outil mysqldump <🎜. >
Vous pouvez voir que le fichier de sauvegarde contient des informations, qui sont indiquées au début du fichier. Le numéro de version de l'outil mysqldump <🎜. >
 sauvegarde d'origine
sauvegarde d'origine
Par exemple :
Le L'instruction set attribue la valeur de la variable système actuelle Character_set_client à la variable utilisateur @OLD_CHARACTER_SET_CLIENT
-- MySQL dump 10.13 Distrib 5.5.20, for Win32 (x86) -- -- Host: 127.0.0.1 Database: school -- ------------------------------------------------------ -- Server version 5.5.20-log /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `book` -- DROP TABLE IF EXISTS `book`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `book` ( `bookid` int(11) NOT NULL, `bookname` varchar(255) NOT NULL, `authors` varchar(255) NOT NULL, `info` varchar(255) DEFAULT NULL, `comment` varchar(255) DEFAULT NULL, `year_publication` year(4) NOT NULL, KEY `BkNameIdx` (`bookname`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `book` -- LOCK TABLES `book` WRITE; /*!40000 ALTER TABLE `book` DISABLE KEYS */; INSERT INTO `book` VALUES (1,'鍓戝湥','灏忔槑','13','hao',2013); /*!40000 ALTER TABLE `book` ENABLE KEYS */; UNLOCK TABLES; -- -- Table structure for table `student` -- DROP TABLE IF EXISTS `student`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `student` ( `stuno` int(11) DEFAULT NULL, `stuname` varchar(60) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `student` -- LOCK TABLES `student` WRITE; /*!40000 ALTER TABLE `student` DISABLE KEYS */; INSERT INTO `student` VALUES (2,'xiaofang'),(3,'zhanghai'),(6,'haojie'); /*!40000 ALTER TABLE `student` ENABLE KEYS */; UNLOCK TABLES; -- -- Table structure for table `stuinfo` -- DROP TABLE IF EXISTS `stuinfo`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `stuinfo` ( `stuno` int(11) DEFAULT NULL, `class` varchar(60) DEFAULT NULL, `city` varchar(60) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `stuinfo` -- LOCK TABLES `stuinfo` WRITE; /*!40000 ALTER TABLE `stuinfo` DISABLE KEYS */; INSERT INTO `stuinfo` VALUES (1,'wuban','henan'),(2,'liuban','hebei'),(3,'qiban','shandong'); /*!40000 ALTER TABLE `stuinfo` ENABLE KEYS */; UNLOCK TABLES; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2014-07-23 22:04:16
Notez également que certaines des instructions au début du fichier de sauvegarde commencent par des chiffres. Ces chiffres représentent le numéro de version de MySQL. Ce numéro nous indique que ces instructions ne peuvent être utilisées que dans le spécifié. version mysql ou supérieure à cette version. Elle ne peut être exécutée qu'après téléchargement. Par exemple : 40101, indiquant que ces instructions ne peuvent être exécutées que lorsque la version de mysql est 4.01.01 ou supérieure
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
Sauvegarder la table des livres dans la base de données de l'école
Le contenu du fichier de sauvegarde suit L'introduction précédente est la même, la seule différence est qu'elle ne contient que l'instruction CREATE et l'instruction INSERT de la table book
3. Utilisez mysqldump pour sauvegarder plusieurs bases de données Si vous souhaitez utiliser mysqldump pour sauvegarder plusieurs bases de données, vous devez utiliser le paramètre --databases.
Après avoir utilisé le paramètre --databases, vous devez spécifier le nom d'au moins une base de données et séparer plusieurs noms de bases de données par des espaces
Utilisez mysqldump pour sauvegarder la bibliothèque scolaire et tester la bibliothèque 
-- MySQL dump 10.13 Distrib 5.5.20, for Win32 (x86) -- -- Host: 127.0.0.1 Database: school -- ------------------------------------------------------ -- Server version 5.5.20-log /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `book` -- DROP TABLE IF EXISTS `book`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `book` ( `bookid` int(11) NOT NULL, `bookname` varchar(255) NOT NULL, `authors` varchar(255) NOT NULL, `info` varchar(255) DEFAULT NULL, `comment` varchar(255) DEFAULT NULL, `year_publication` year(4) NOT NULL, KEY `BkNameIdx` (`bookname`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `book` -- LOCK TABLES `book` WRITE; /*!40000 ALTER TABLE `book` DISABLE KEYS */; INSERT INTO `book` VALUES (1,'剑圣','小明','13','hao',2013); /*!40000 ALTER TABLE `book` ENABLE KEYS */; UNLOCK TABLES; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2014-07-23 22:24:29
Le contenu du fichier de sauvegarde est fondamentalement le même que celui du premier exemple, mais il indique quelle partie du contenu appartient à la bibliothèque de test et quelle partie appartient à la bibliothèque scolaire
4. Utilisez le paramètre --all-databases pour sauvegarder toutes les bases de données du système
En utilisant --all- les bases de données ne nécessitent pas de spécifier un nom de base de données
 Une fois l'exécution terminée, le fichier de sauvegarde all_2014-7-10.sql sera généré, qui contiendra les informations de sauvegarde de toutes les bases de données
Une fois l'exécution terminée, le fichier de sauvegarde all_2014-7-10.sql sera généré, qui contiendra les informations de sauvegarde de toutes les bases de données
Conseils : si vous effectuez une sauvegarde sur le serveur et que les tables sont toutes myisam, vous devriez envisager d'utiliser mysqlhotcopy
car il peut être sauvegardé et restauré plus rapidement
使用mysqlhotcopy,如果是Windows操作系统,需要先安装perl脚本组件才能使用,因为mysqlhotcopy是使用perl来编写的
提示
(1)如果你未使用--quick或者--opt选项,那么mysqldump将在转储结果之前把全部内容载入到内存中。这在你转储大数据量的数据库时将会有些问题。该选项默认是打开的,但可以使用--skip-opt来关闭它。
(2)使用--skip-comments可以去掉导出文件中的注释语句
(3)使用--compact选项可以只输出最重要的语句,而不输出注释及删除表语句等等
(4)使用--database或-B选项,可以转储多个数据库,在这个选项名后的参数都被认定为数据库名
SQLSERVER逻辑备份
我发现SQLSERVER的备份概念并没有ORACLE和MYSQL那么多
我们通常都会使用下面的两个SQL语句来备份SQLSERVER数据库,例如备份test库
BACKUP DATABASE test TO DISK='c:\test.bak' BACKUP LOG test TO DISK='c:\test_log.bak'
第一个SQL是完整备份test库,如果加上WITH DIFFERENTIAL就是差异备份
第二个SQL是备份test库的日志
实际上从我眼中的理解,SQLSERVER就是将数据文件和必要的日志信息放入一个压缩包里面,类似于MYSQL的物理备份,直接复制文件,只是MYSQL并没有进行打包压缩
SQLSERVER的逻辑备份
逻辑备份就是生成表定义脚本和数据插入脚本,SQLSERVER2008开始支持生成数据脚本,在SQLSERVER2008之前只支持生成表定义脚本
我所用的数据库是SQLSERVER2012 SP1
选中需要生成脚本的数据库

比如我要导出test表的数据和表定义

要选择架构和数据,并且要选择索引,这样就会生成表的数据、定义、索引
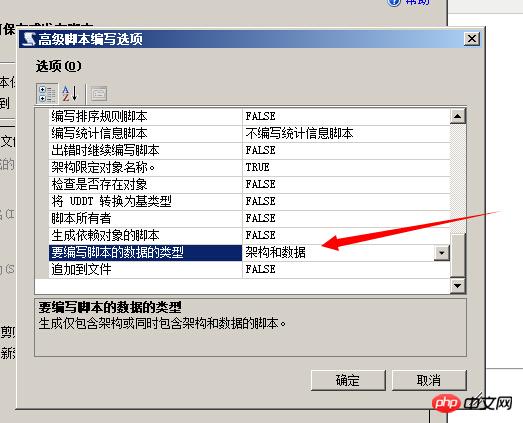

生成的脚本如下
USE [sss]
GO
/****** Object: Table [dbo].[test] Script Date: 2014/7/24 11:27:44 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[test](
[a] [int] NULL
) ON [PRIMARY]
GO
INSERT [dbo].[test] ([a]) VALUES (10)
GO由于test表是没有任何索引的,所以脚本里看不到CREATE INDEX语句
实际上各种数据库的备份恢复方法都是大同小异的
ORACLE冷备份与恢复
逻辑备份和物理备份
1、导出create table 、create index、insert into 表等语句(逻辑备份)
mysql:mysqldump、load data infile、select into outfile
sqlserver:生成脚本、导入导出向导
oracle:(exp/imp)
2、直接复制文件(物理备份)
sqlserver:backup database语句、backup log语句、停SQLSERVER服务直接拷贝数据文件
mysql:mysqlhotcopy、innobackupex
oracle:rman、直接将关键性文件拷贝到另外的位置、(exp/imp)、(expdp/impdp)
相似点:上面的各种数据库的各种备份还原方法,每一种基本上都会有一个单独的工具来做
例如sqlserver导入导出向导就是一个单独的exe来做
oracle的rman也是一个单独的工具
冷备份和热备份:无论oracle、sqlserver、mysql都有冷备份和热备份的概念
冷备份其实可以简单理解为:停止服务进行备份
热备份其实可以简单理解为:不停止服务进行备份(在线)
上面的停止服务,正确的来讲应该是停止数据库的写入
为什么mysql的myisam引擎只支持冷备份呢?
大家可以先想一下innodb引擎,innodb引擎是事务性存储引擎,每一条语句都会写日志,并且每一条语句在日志里面都有时间点
那么在备份的时候,mysql可以根据这个日志来进行redo和undo,将备份的时候没有提交的事务进行回滚,已经提交了的进行重做
但是myisam不行,myisam是没有日志的,为了保证一致性,只能停机或者锁表进行备份
在书《MYSQL性能调优和架构设计》里面说到了事务的作用

大家可以想一想,为什么sqlserver支持从某一个lsn或者时刻进行恢复数据库,他也是从日志里面读取日志的lsn号来进行恢复到某一个lsn时刻的数据或者某一个时刻的数据
假如没有事务日志,那么sqlserver是做不到时点还原的
热备份、冷备份
为什么SQLSERVER需要停止SQLSERVER服务才可以拷贝物理数据文件,为的都是保证数据一致性

物理备份方法
1、直接复制整个数据库目录
因为MYSQL表保存为文件方式,所以可以直接复制MYSQL数据库的存储目录以及文件进行备份。
MYSQL的数据库目录位置不一定相同,在Windows平台下,MYSQL5.6存放数据库的目录通常默认为
C:\Documents and Settings\All User\Application Data\MySQL\MYSQL Server 5.6\data
或者其他用户自定义的目录;
在Linux平台下,数据库目录位置通常为/var/lib/mysql/,不同Linux版本下目录会有不同
这是一种简单、快速、有效的备份方式。要想保持备份一致,备份前需要对相关表执行LOCK TABLES操作,然后对表执行
FLUSH TABLES。这样当复制数据库目录中的文件时,允许其他客户继续查询表。需要FLUSH TABLES语句来确保开始
备份前将所有激活的索引页写入磁盘。
当然,也可以停止MYSQL服务再进行备份操作
这种方法虽然简单,但并不是最好的方法。因为这种方法对INNODB存储引擎的表不适用。使用这种方法备份的数据最好还原
到相同版本的服务器中,不同的版本可能不兼容。
注意:在mysql版本中,第一个数字表示主版本号,主版本号相同的MYSQL数据库文件格式相同
2、使用mysqlhotcopy工具快速备份
mysqlhotcopy是一个perl脚本,最初由Tim Bunce编写并提供。他使用LOCK TABLES 、FLUSH TABLES和cp或scp
来快速备份数据库。他是备份数据库或单个表的最快途径,但他只能运行在数据库目录所在机器上,并且只能备份myisam类型的表。
语法
mysqlhotcopy db_name_1,...db_name_n /path/to/new_directory
db_name_1...n代表要备份的数据库的名称;
path/to/new_directory指定备份文件目录
示例
在Linux下面使用mysqlhotcopy备份test库到/usr/backup
mysqlhotcopy -u root -p test /usr/backup
要想执行mysqlhotcopy,必须可以访问备份的表文件,具有那些表的SELECT权限、RELOAD权限(以便能够执行FLUSH TABLES)
和LOCK TABLES权限
提示:mysqlhotcopy只是将表所在目录复制到另一个位置,只能用于备份myisam和archive表。备份innodb表会出现错误信息
由于他复制本地格式的文件,故也不能移植到其他硬件或操作系统下
还原
逻辑还原
1、使用mysql命令进行还原
对于已经备份的包含CREATE、INSERT语句的文本文件,可以使用myslq命令导入数据库中
备份的sql文件中包含CREATE、INSERT语句(有时也会有DROP语句)。mysql命令可以直接执行文件中的这些语句
其语法如下:
mysql -u user -p [dbname]<filename.sql
user是执行backup.sql中语句的用户名;-p表示输入用户密码;dbname是数据库名
如果filename.sql文件为mysqldump工具创建的包含创建数据库语句的文件,执行的时候不需要指定数据库名
用mysql命令将school_2014-7-10.sql文件中的备份导入到数据库中
mysql -u root -h 127.0.0.1 -p school<c:\school_2014-7-10.sql
执行语句之前我们必须建好school数据库,如果不存在恢复过程将会出错。
可以看到表数据都已经导入到数据库了

如果已经登录mysql,那么可以使用source命令导入备份文件
使用source命令导入备份文件school_2014-7-10.sql

执行source命令前必须使用use 语句选择好数据库,不然会出现ERROR 1046(3D000):NO DATABASE SELECTED 的错误
还有一点要注意的是只能在cmd界面下执行,不能在mysql工具里面执行source命令,否则会报错
因为cmd是直接调用mysql.exe来执行命令的
而这些mysql 编辑工具只是利用mysql connector连接mysql,来管理mysql并不是直接调用mysql.exe,所以执行source会报错

物理还原
2、直接复制到数据库目录
如果数据库通过复制数据库文件备份,可以直接复制备份文件到MYSQL数据目录下实现还原。通过这种方式还原时,
必须保证备份数据的数据库和待还原的数据库服务器的主版本号相同。
而且这种方式只对MYISAM引擎有效,对于innodb引擎的表不可用
执行还原以前关闭mysql服务,将备份的文件或目录覆盖mysql的data目录,启动mysql服务。
对于Linux操作系统来说,复制完文件需要将文件的用户和组更改为mysql运行的用户和组,通常用户是mysql,组也是mysql
3、mysqlhotcopy快速恢复
mysqlhotcopy备份后的文件也可以用来恢复数据库,在mysql服务器停止运行时,将备份的数据库文件复制到mysql存放数据的位置
(mysql的data文件夹),重新启动mysql服务即可。
如果根用户执行该操作,必须指定数据库文件的所有者,输入语句如下:
chown -R mysql.mysql /var/lib/mysql/dbname
从mysqlhotcopy复制的备份恢复数据库
cp -R /usr/backup/test usr/local/mysql/data
执行完该语句,重启服务器,mysql将恢复到备份状态
注意:如果需要恢复的数据库已经存在,则在使用DROP语句删除已经存在的数据库之后,恢复才能成功。
另外mysql不同版本之间必须兼容,恢复之后的数据才可以使用!!
数据库迁移
数据库迁移就是把数据从一个系统移动到另一个系统上。
迁移的一般原因:
1、需要安装新的数据库服务器
2、mysql版本更新
3、数据库管理系统变更(从SQLSERVER迁移到mysql)
相同版本的MYSQL数据库之间迁移
相同版本mysql数据库间的迁移就是主版本号相同的mysql数据库直接进行数据库移动。
前面讲解备份和还原的时候,知道最简单的方法就是复制数据库文件目录,但是这种方法只适合于myisam表
对于innodb表,不能直接复制文件来备份数据库
最常用的方法是使用mysqldump导出数据,然后在目标数据库服务器使用mysql命令导入
将www.abc.com主机上的mysql数据库全部迁移到www.bcd.com主机上。
在www.abc.com主机上执行以下命令:
mysqldump -h www.abc.com -u root -p dbname | mysql -h www.bcd.com -u root -p
mysqldump导入的数据直接通过管道符|,传给mysql命令导入到主机www.bcd.com数据库中,dbname为需要迁移的数据库名称
如果要迁移全部数据库,可以使用--all -databases参数
不同版本的mysql数据库之间的迁移
因为数据库升级,需要将旧版本mysql数据库中的数据迁移到新版本数据库中。
mysql服务器升级,需要先停止服务,然后卸载旧版本,并安装新版本的mysql,这种更新方法很简单。
如果想保留旧版本中的用户访问控制信息,则需要备份mysql的mysql库,
在新版本mysql安装完成后,重新读入mysql备份文件中的信息
旧版本和新版本的mysql可能使用不同的默认字符集,例如mysql.4.x中大多数使用latin1作为默认字符集,
而mysql5.x的默认字符集为utf8。如果数据库中有中文数据,迁移过程中需要对默认字符集进行修改,不然可能无法正常显示结果
新版本对旧版本有一定兼容性。从旧版本的mysql向新版本mysql迁移时,对于myisam引擎的表,可以直接复制数据库文件,
也可以用mysqlhotcopy工具、mysqldump工具。
对于innodb引擎的表一般只能使用mysqldump将数据导出。然后使用mysql命令导入目标服务器。
从新版本向旧版本mysql迁移数据时要小心,最好使用mysqldump命令导出,然后导入目标数据库中。
不同数据库之间的迁移
不同类型的数据库之间的迁移,是指把mysql数据库迁移到其他的数据库,例如从mysql迁移到oracle,从oracle迁移到mysql
从mysql迁移到SQLSERVER等。
迁移之前,需要了解不同数据库的结构,比较他们的差异。不同数据库定义相同类型的数据的关键字可能不同。
例如:mysql中日期字段分为DATE 和TIME两种,而ORACLE的日期字段只有DATE。
数据库迁移可以使用一些工具,例如,在Windows系统下,可以使用MyODBC实现mysql和SQLSERVER之间的迁移(使用SQLSERVER导入导出向导)
mysql官方提供的工具:MYSQL Migration Toolkit也可以在不同数据库间进行数据迁移。
表的导入导出
MYSQL数据库可以将数据导出成sql文本文件、xml文件、html文件。同样这些导出文件也可以导入到MYSQL数据库中
一般异构数据库迁移都是采用文本文件的方式来导数据
导出
1、用SELECT...INTO OUTFILE导出文本文件
mysql导出数据时,允许使用包含表定义的select语句进行数据的导出操作
该文件被创建在服务器主机上,因此必须有文件写入权限(FILE权限),才能使用此语法
SELECT INTO…OUTFILE语法:
select columnlist from Table WHERE condition into outfile 'filename' [OPTIONS] fields terminated by 'VALUE' fields [OPTIONALLY] ENCLOSED BY 'VALUE' fields ESCAPED BY 'VALUE' lines STARTING by 'VALUE' lines terminated by 'VALUE'
into outfile语句的作用就是把前面select语句查询出来的结果导出到名称为“filename”的外部文件中
[OPTIONS]部分为可选参数,[OPTIONS]部分的语法包括FILED和LINES子句,其可能取值为:
● fields子句:在FIELDS子句中有三个子句:TERMINATED BY、 [OPTIONALLY] ENCLOSED BY和ESCAPED BY。
如果指定了FIELDS子句,则这三个子句中至少要指定一个。
(1)TERMINATED BY用来指定字段值之间的符号,例如,“TERMINATED BY ','”指定了逗号作为两个字段值之间的标志,默认为“\t”制表符。
(2)ENCLOSED BY子句用来指定包裹文件中字符值的符号,例如,“ENCLOSED BY ' " '”表示文件中字符值放在双引号之间,
若加上关键字OPTIONALLY表示所有的值都放在双引号之间,则只有CHAR和VARCHAR等字符数据字段被包括。
(3)ESCAPED BY子句用来指定转义字符,例如,“ESCAPED BY '*'”将“*”指定为转义字符,取代“\”,如空格将表示为“*N”。
● LINES子句:在LINES子句中使用TERMINATED BY指定一行结束的标志,如“LINES TERMINATED BY '?'”表示一行以“?”作为结束标志,默认值为“\n”。
TERMINATED BY也是同样的原理
FIELDS子句和LINES子句都是自选的,但是如果两个都被指定了,FIELDS子句必须位于LINES子句的前面
SELECT INTO…OUTFILE只能在本机执行,如果要在其他服务器上导出数据,则需要使用下面命令来生成文件
mysql -e "select ...">filename
-e, --execute=name Execute command and quit. (Disables --force and history
SELECT INTO…OUTFILE是LOAD DATA INFILE的补语。用于语句的OPTIONS部分的语法包括部分FIELDS子句和LINES子句
这些子句与LOAD DATA INFILE语句同时使用
使用SELECT INTO…OUTFILE将test数据库中的person表的记录导出到文本文件
输入命令如下
SELECT * FROM test.person INTO OUTFILE "C:\person0.txt" ;
由于指定了INTO OUTFILE 子句,SELECT将查询出来的3个字段的值保存到C:\person0.txt文件,打开文件内容如下
1 green 29 lawer 2 suse 26 dancer 3 evans 27 sports man 4 mary 26 singer
可以看到默认情况下,MYSQL使用制表符“\t”分隔不同的字段,字段没有被其他字符括起来
另外在Windows平台下,使用记事本打开该文件,显示的格式与这里并不相同,这是因为Windows系统下回车换行为“\r\n”
默认换行符为“\n”,因此会在person.txt中可能看到类似黑色方块的字符,所有的记录也会在同一行显示
默认情况下,NULL值会显示为“\N”,转义字符会显示为“\”
使用SELECT ..INTO OUTFILE将test库中的person表中的记录导出到文本文件,使用FIELDS选项和LINES选项,要求字段之间
使用逗号“,”间隔,所有字段值用双引号括起来,定义转移字符为单引号“\'”
SELECT * FROM test.person INTO OUTFILE "C:\person1.txt" FIELDS TERMINATED BY ',' ENCLOSED BY '\'' ESCAPED BY '\'' LINES TERMINATED BY '\r\n';
在C盘下生成的person1文件内容
'1','green','29','lawer' '2','suse','26','dancer' '3','evans','27','sports man' '4','mary','26','singer'
FIELDS TERMINATED BY ','表示字段之间用逗号分隔
ENCLOSED BY '\''表示每个字段用双引号括起来
ESCAPED BY '\''表示将系统默认的转移字符替换为单引号
LINES TERMINATED BY '\r\n'表示每行以回车换行符结尾,保证每一条记录占一行
2、用mysqldump命令导出文本文件
除了使用SELECT...INTO OUTFILE导出文本文件之外,也可以使用mysqldump
mysqldump不仅可以将数据导出包含CREATE、INSERT的sql文件,也可以导出为纯文本文件
mysqldump创建一个包含创建表的CREATE TABLE语句的tablename.sql文件,和一个包含其数据
的tablename.txt文件。mysqldump导出文本文件的基本语法如下
mysqldump -T path -u root -p dbname [tables][OPTIONS] --fields-terminated-by= --fields-enclosed-by= --fields-optionally-enclosed-by= --fields-escaped-by= --lines-terminated-by=
只有指定了-T参数才可以导出纯文本文件;path表示导出数据的目录
tables为指定要导出的表名称,如果不指定,将导出dbname的所有表
基本上每个选项跟SELECT ..INTO OUTFILE语句中的OPTIONS各个参数设置相同
不同的是,等号后面的value值不要用引号括起来
使用mysqldump将test库的person表的记录导出到文本文件,执行的命令如下
mysqldump -T C:\ -u root -h 127.0.0.1 -p test person
这里要注意的是,路径这里不能先创建好person.txt文件,否则会报错,跟SELECT ..INTO OUTFILE语句是一样的
在C盘会生成一个person.txt文件和person.sql文件,内容如下

person.sql
-- MySQL dump 10.13 Distrib 5.5.28, for Win32 (x86) -- -- Host: 127.0.0.1 Database: test -- ------------------------------------------------------ -- Server version 5.5.28-log /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `person` -- DROP TABLE IF EXISTS `person`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `person` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `Name` varchar(20) NOT NULL, `Age` int(10) unsigned DEFAULT NULL, `job` varchar(90) NOT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2014-07-27 23:56:01
person.sql的内容跟之前解释的是一样的
person.txt
1 green 29 lawer 2 suse 26 dancer 3 evans 27 sports man 4 mary 26 singer
3、使用mysql命令导出文本文件
mysql是一个功能丰富的工具命令,使用mysql还可以在命令行模式下执行SQL指令,将查询结果导入到文本文件中。
相比mysqldump,mysql工具导出的结果可读性更强
如果mysql服务器是单独的机器,用户是在一个client上进行操作,用户要把数据结果导入到client机器上,可以使用mysql -e语句
基本格式如下:
mysql -u root -p --execute="SELECT 语句" dbname >filename.txt
该命令使用--execute 选项,表示执行该选项后面的语句并退出,后面的语句必须用双引号括起来
dbname为要导出的数据库名称,导出的文件中不同列之间使用制表符分隔,第一行包含了字段名称
使用mysql命令,导出test库的person表记录到文本文件,输入语句如下:
mysql -u root -p --execute="SELECT * FROM person;" test>C:\person3.txt
person3.txt的内容如下
ID Name Age job 1 green 29 lawer 2 suse 26 dancer 3 evans 27 sports man 4 mary 26 singer
可以看到,person3.txt文件中包含了每个字段的名称和各条记录,如果某行记录字段很多,可能一行不能完全显示,可以使用
--vertical参数,将每条记录分为多行显示
使用mysql命令导出test库的person表使用--vertical参数显示
mysql -u root -p --vertical --execute="SELECT * FROM person;" test>C:\person4.txt *************************** 1. row *************************** ID: 1 Name: green Age: 29 job: lawer *************************** 2. row *************************** ID: 2 Name: suse Age: 26 job: dancer *************************** 3. row *************************** ID: 3 Name: evans Age: 27 job: sports man *************************** 4. row *************************** ID: 4 Name: mary Age: 26 job: singer
如果person表中记录内容太长,这样显示将会更加容易阅读
使用mysql命令导出test库的person表记录到html文件,输入语句如下
mysql -u root -p --html --execute="SELECT * FROM PERSON;"test >C:\person5.html
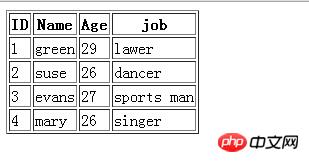
如果要导出为xml文件,那么使用--xml选项
使用mysql命令导出test库的person表的中记录到xml文件
mysql -u root -p --xml --execute="SELECT * FROM PERSON;" test >C:\person6.xml
<?xml version="1.0"?>
<resultset statement="SELECT * FROM PERSON" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<field name="ID">1</field>
<field name="Name">green</field>
<field name="Age">29</field>
<field name="job">lawer</field>
</row>
<row>
<field name="ID">2</field>
<field name="Name">suse</field>
<field name="Age">26</field>
<field name="job">dancer</field>
</row>
<row>
<field name="ID">3</field>
<field name="Name">evans</field>
<field name="Age">27</field>
<field name="job">sports man</field>
</row>
<row>
<field name="ID">4</field>
<field name="Name">mary</field>
<field name="Age">26</field>
<field name="job">singer</field>
</row>
</resultset>导入
1、使用LOAD DATA INFILE 方式导入文本文件
mysql允许将数据导出到外部文件,也可以从外部文件导入数据。
MYSQL提供了一些导入数据的工具,这些工具有:LOAD DATA语句、source命令、mysql命令
LOAD DATA INFILE语句用于高速地从一个文本文件中读取行,并装入一个表中。文件名称必须为文字字符串
语法如下:
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt' [REPLACE | IGNORE] INTO TABLE tbl_name [FIELDS [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char' ] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number LINES] [(col_name_or_user_var,...)] [SET col_name = expr,...]]
load data infile语句从一个文本文件中以很高的速度读入一个表中。
使用这个命令之前,mysqld进程(服务) 必须已经在运行。
当读取的文本文件不在本机,而是位于服务器上的文本文件时,使用load data infile语句,在服务器主机上你必须有file的权限。
1 、如果你指定关键词low_priority,那么MySQL将会等到没有其他人读取这个表的时候,
才插入数据。例如如下的命令:
load data low_priority infile "/home/mark/data.sql" into table Orders;
2 、如果指定local关键词,则表明读取的文件在本机,那么必须指定local参数。
3 、replace和ignore参数控制对现有表的唯一键记录重复的处理。
如果你指定replace,新行将代替有相同的唯一键值的现有行。
(1)如果你指定ignore,跳过有唯一键的现有行的重复行的输入。
(2)如果你不指定任何一个选项,当找到重复键时,出现一个错误,并且文本文件的余下部分被忽略。
FIELDS TERMINATED BY ','表示字段之间用逗号分隔
ENCLOSED BY '\''表示每个字段用双引号括起来
ESCAPED BY '\''表示将系统默认的转移字符替换为单引号
LINES STARTING BY ''表示每行数据开头的字符,可以为单个或多个,默认不是有任何字符
LINES TERMINATED BY '\r\n'表示每行以回车换行符结尾,保证每一条记录占一行
[IGNORE number LINES] 选项表示忽略文件开始处的行数,number表示忽略的行数。
基本上格式上的参数跟SELECT...INTO OUTFILE是一样的
使用LOAD DATA命令将C:\person0。txt文件中的数据导入到test库中的test表
LOAD DATA INFILE 'C:\person0.txt' INTO TABLE test.person
先删除person表里的数据,然后执行LOAD DATA命令

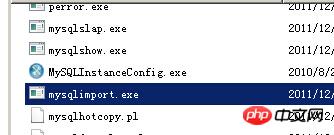
使用mysqlimport命令导入文本文件
2、使用mysqlimport命令导入文本文件
mysqlimport是一个单独的exe,他提供了许多与LOAD DATA INFILE语句相同的功能
大多数选项直接对应LOAD DATA INFILE子句
mysqlimport的语法如下
mysqlimport -u root -p dbname filename.txt [OPTIONS] --[OPTIONS] 选项 FIELDS TERMINATED BY 'value' ENCLOSED BY 'value' ESCAPED BY 'value' LINES TERMINATED BY 'value' IGNORE LINES
[OPTIONS] 选项基本上与LOAD DATA INFILE 语句是一样的,这里不做介绍了
mysqlimport不能指定导入的表名称,表名称由导入文件名称确定,即文件名作为表名,导入数据之前该表必须存在
使用mysqlimport命令将C:\目录下person.txt文件内容导入到test库
先删除test库的person表的数据
DELETE FROM `person`;
person.txt文件内容
1 green 29 lawer 2 suse 26 dancer 3 evans 27 sports man 4 mary 26 singer
命令如下
mysqlimport -u root -p test C:\person.txt

导入成功

mysqlimport的常见选项:
显示帮助消息并退出。
· --columns=column_list, -c column_list
该选项采用用逗号分隔的列名作为其值。列名的顺序指示如何匹配数据文件列和表列。
· --compress,-C
压缩在客户端和服务器之间发送的所有信息(如果二者均支持压缩)。
· ---debug[=debug_options],-# [debug_options]
写调试日志。debug_options字符串通常是'd:t:o,file_name'。
· --delete,-D
导入文本文件前清空表。
· --fields-terminated-by=...,--fields-enclosed-by=...,--fields-optionally-enclosed-by=...,--fields-escaped-by=...,--lines-terminated-by=...
这些选项与LOAD DATA INFILE相应子句的含义相同。参见13.2.5节,“LOAD DATA INFILE语法”。
· --force,-f
忽视错误。例如,如果某个文本文件的表不存在,继续处理其它文件。不使用--force,如果表不存在则mysqlimport退出。
· --host=host_name,-h host_name
将数据导入给定主机上的MySQL服务器。默认主机是localhost。
· --ignore,-i
参见--replace选项的描述。
· --ignore-lines=n
忽视数据文件的前n行。
· --local,-L
从本地客户端读入输入文件。
· --lock-tables,-l
处理文本文件前锁定所有表以便写入。这样可以确保所有表在服务器上保持同步。
· --password[=password],-p[password]
当连接服务器时使用的密码。如果使用短选项形式(-p),选项和 密码之间不能有空格。如果在命令行中--password或-p选项后面没有 密码值,则提示输入一个密码。
· --port=port_num,-P port_num
用于连接的TCP/IP端口号。
· --protocol={TCP | SOCKET | PIPE | MEMORY}
使用的连接协议。
· --replace,-r
--replace和--ignore选项控制复制唯一键值已有记录的输入记录的处理。
如果指定--replace,新行替换有相同的唯一键值的已有行。
如果指定--ignore,复制已有的唯一键值的输入行被跳过。如果不指定这两个选项,当发现一个复制键值时会出现一个错误,并且忽视文本文件的剩余部分。
· --silent,-s
沉默模式。只有出现错误时才输出。
· --socket=path,-S path
当连接localhost时使用的套接字文件(为默认主机)。
· --user=user_name,-u user_name
当连接服务器时MySQL使用的用户名。
· --verbose,-v
冗长模式。打印出程序操作的详细信息。
· --version,-V
显示版本信息并退出。提示:
LOAD DATA INFILE语句中有一个mysqlimport工具中没有特点:
LOAD DATA INFILE 可以按指定的字段把文件导入到数据库中。
当我们要把数据的一部分内容导入的时候,这个特点就很重要。
比方说,我们要从Access数据库升级到MySQL数据库的时候,需要加入一些字段(列/字 段/field)到MySQL数据库中,以适应一些额外的需要。
这个时候,我们的Access数据库中的数据仍然是可用的,但是因为这些数据的字段(field)与MySQL中的不再匹配,因此而无法再使用mysqlimport工具。
尽管如此,我们仍然可以使用LOAD DATA INFILE,下面的例子显示了如何向指定的字段(field)中导入数据:
LOAD DATA INFILE "/home/Order.txt" INTO TABLE Orders(Order_Number, Order_Date, Customer_ID);
如您所见,我们可以指定需要的字段(fields)。这些指定的字段依然是以括号括起,由逗号分隔的,如果您遗漏了其中任何一个,MySQL将会提醒您^_^
如何选择备份工具?
直接复制数据文件是最为直接、快速的备份方法,但缺点是基本上不能实现增量备份。
备份时必须确保没有使用这些表。如果在复制一个表的物理数据文件的同时服务器正在修改他,则复制无效。
备份文件时,最好关闭服务器,然后重新启动服务器,为了保证数据的一致性,需要在备份文件前执行以下SQL
FLUSH TABLES WITH READ LOCK;
也就是把内存中的数据刷新到磁盘中,同时锁定数据表,以保证复制过程中不会有新的数据写入。
这种方法备份出来的数据恢复很简单,直接复制回原来的数据库目录下即可
mysqlhotcopy是一个PERL程序,他使用LOCK TABLES、FLUSH TABLES和CP或SCP来快速备份数据库
他是备份数据库或单个表的最快的途径,但他只能运行在数据库文件所在机器上,并且mysqlhotcopy只能用于备份myisam表
mysqlhotcopy适合于小型数据库的备份,数据量不大,可以使用mysqlhotcopy程序每天进行一次完全备份
mysqldump将数据表导出为SQL脚本,在不同的MYSQL版本之间升级时相对比较合适,这也是最常用的备份方法。
mysqldump比直接复制要慢些。
使用mysqldump备份整个数据库成功,把表和数据库删除了,但使用备份文件却不能恢复数据库?
出现这种情况是因为备份的时候没有指定--databases参数。默认情况下,如果只指定数据库名称,mysqldump
备份的是数据库中的所有表,而不包括数据库的创建语句,如下
mysqldump -u root -p booksdb >c:\booksdb_2014-7-1.sql
该语句只备份了booksdb数据库下的所有表,读者打开该文件,可以看到文件中不包含创建booksdb数据库
的CREATE DATABASE语句,因此如果把booksdb也删除了,使用该sql文件不能还原以前的表,
还原时会出现ERROR 1046(3D000):NO DATABASE SELECTED 的错误信息
而下面的语句,数据库删除之后,可以正常还原备份时的状态
mysqldump -u root -p --databases booksdb>C:\booksdb_db_2014-7-1.sql
该语句不仅备份了所有数据库下的表结构,而且包括创建数据库的语句
总结
这一节介绍了MYSQL中的备份和还原,还有数据库的迁移,异构数据库之间的迁移基本上都用导出文件文件的方法
如果是小数据量尚可以,如果数据量比较大,导出文本文件也会很大,不是太可取
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
La clé de l'installation de MySQL est d'élégance pour ajouter le référentiel MySQL officiel. Les étapes spécifiques sont les suivantes: Téléchargez la clé GPG officielle MySQL pour empêcher les attaques de phishing. Ajouter un fichier de référentiel MySQL: RPM -UVH https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Mise à jour du référentiel Cache: Yum Update Installation Mysql: Yum install install install starting starting mysql Service: SystemCTL start start mysqld starger bugo boartup Service mysql Service: SystemCTL start start mysqld starger bugo bo onthing staring Service mysql Service: SystemCTL Start Start MySQLD Set Out Up Boaching Staring Service MySQL Service: SystemCTL Start Start MysQL
